BigQueryデータマスキング vs. Sensitive Data Protection:機密データ保護の最適解
BigQueryのデータマスキングとSensitive Data Protection、それぞれの役割と使い分けを解説し、データセキュリティのベストプラクティスを提案します。
Table of contents
author: Chiakoba
はじめに
今日のデータドリブンな時代において、組織は膨大なデータをBigQueryのようなデータウェアハウスに集約しています。しかし、そのデータには個人を特定できる情報(PII)や機密性の高いビジネスデータが含まれていることが少なくありません。
全てのユーザーがこれらの機密情報に無制限にアクセスできる状態は、セキュリティとコンプライアンスの観点から大きなリスクとなります。
この記事では、データ保護の2つの主要なアプローチ、BigQueryのデータマスキングとSensitive Data Protectionに焦点を当て、それぞれの仕組み、メリット、そして連携による強力なデータ保護戦略について解説します。
※2025/08現在、Cloud Data Loss PreventionはSensitive Data Protectionの一部となっています。
1. BigQueryのデータマスキング:内部統制のための「動的」な保護
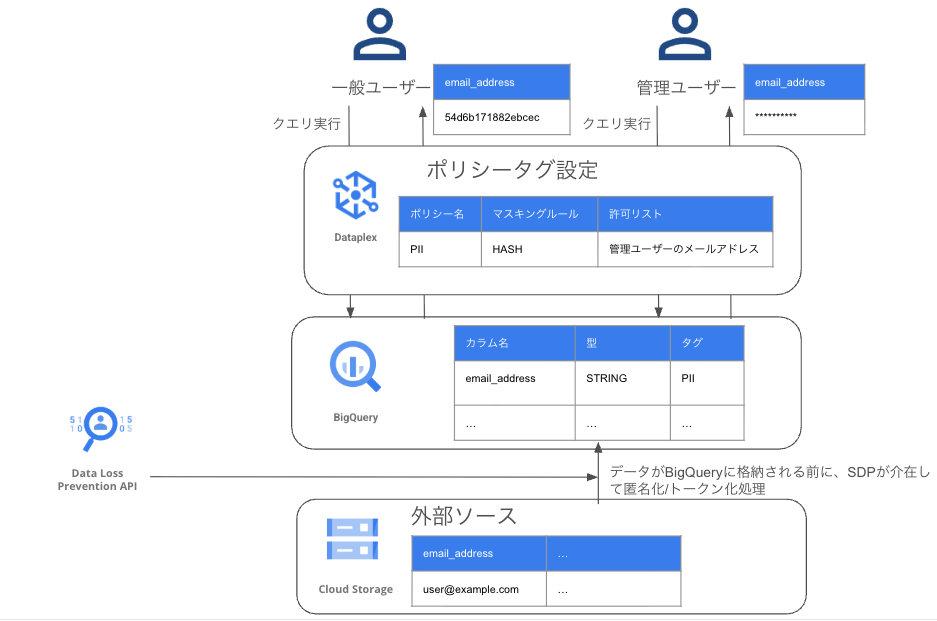
BigQueryのデータマスキングは、BigQueryに格納されたデータへの内部アクセスを制御するための機能です。データ自体を物理的に変更することなく、ユーザーの権限に応じてデータの表示をリアルタイムで変更します。
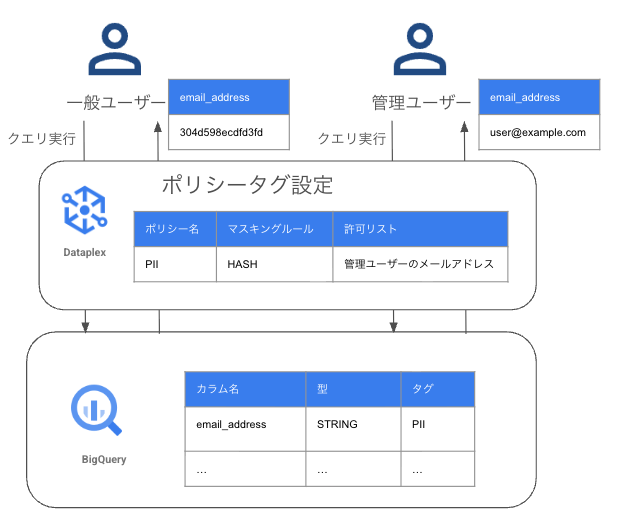
仕組み これは、ポリシータグを使ってカラムに機密性の分類を付与することから始まります。
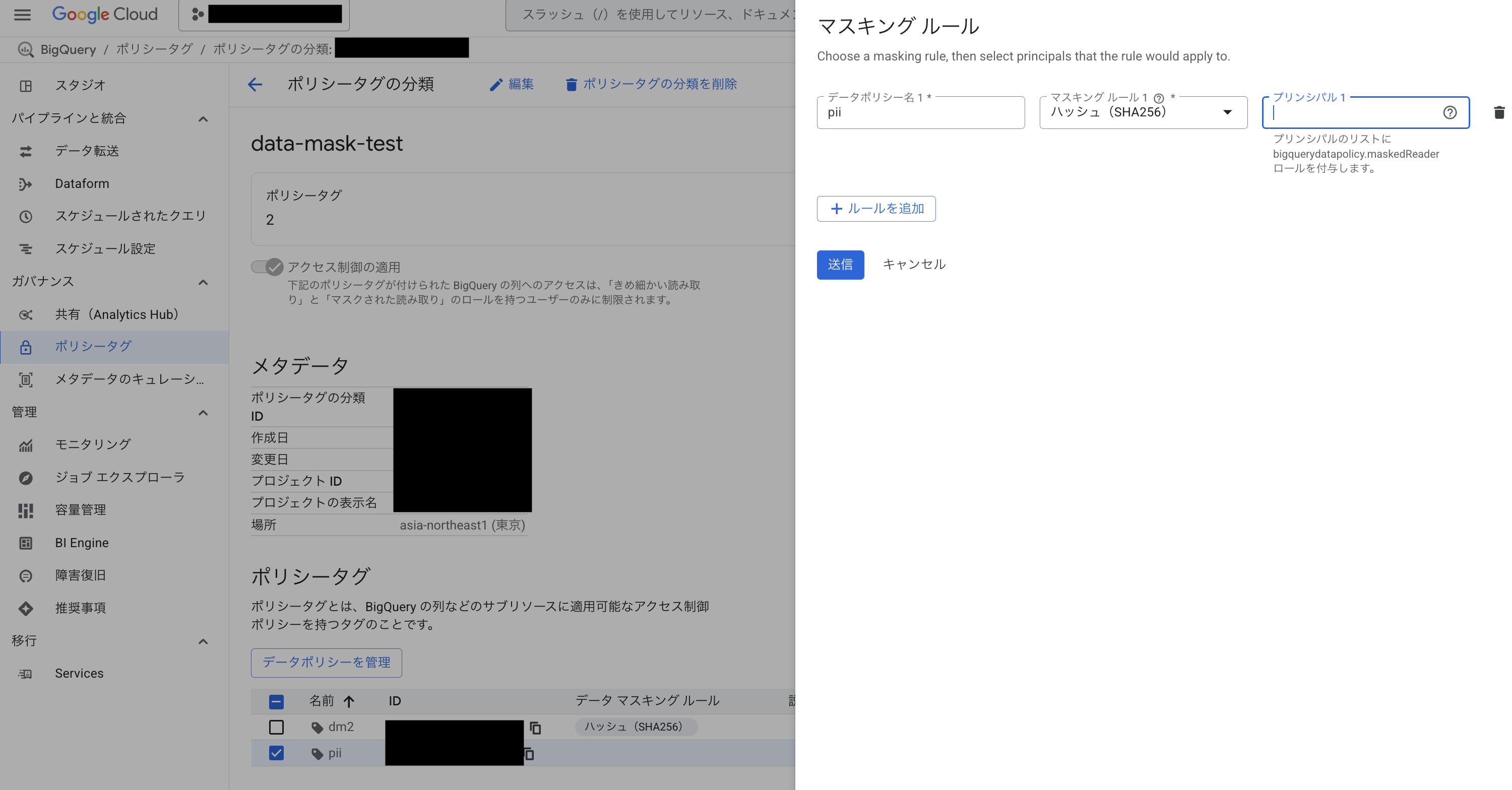
-
タグ付け: email_addressのような機密情報を含むカラムに「pii」といったポリシータグを付与します。
-
アクセス制御: マスクされた読み取りというIAMロールを持つユーザーだけが元のデータを見ることができ、それ以外のユーザーにはデータが自動的にマスキングされます。
これにより、分析者やビジネスユーザーにはマスクされたデータを、コンプライアンスチームには元のデータを提供するといった、きめ細かなアクセス制御が可能です。
メリット
-
シンプルな管理: BigQuery内で完結するため、設定や運用が比較的容易です。
-
動的な保護: クエリ実行時にリアルタイムでマスキングするため、データの複製や事前処理が不要です。
-
最小特権の原則: ユーザーが必要とする最小限のデータアクセスを許可し、セキュリティリスクを低減します。
デメリット
-
管理の手間: 新しいカラムに機密情報が含まれるたびに、手動でポリシータグを設定する必要があります。
-
エクスポート時のリスク: BigQueryの外部にデータをエクスポートする際は、マスキングが適用されません。エクスポートされたファイルには元のデータが含まれるため、別途管理が必要です。
*BigQuery の Standardエディションではご利用できません
*参考
2. Sensitive Data Protection:データのライフサイクル全体を保護する「物理的」な加工
Sensitive Data Protection(以下、SDP)は、機密データを永続的に匿名化またはトークン化する、より積極的なデータ保護ツールです。BigQueryだけでなく、Google Cloud Storage(GCS)、テキストデータなど、さまざまなデータソースに適用できます。
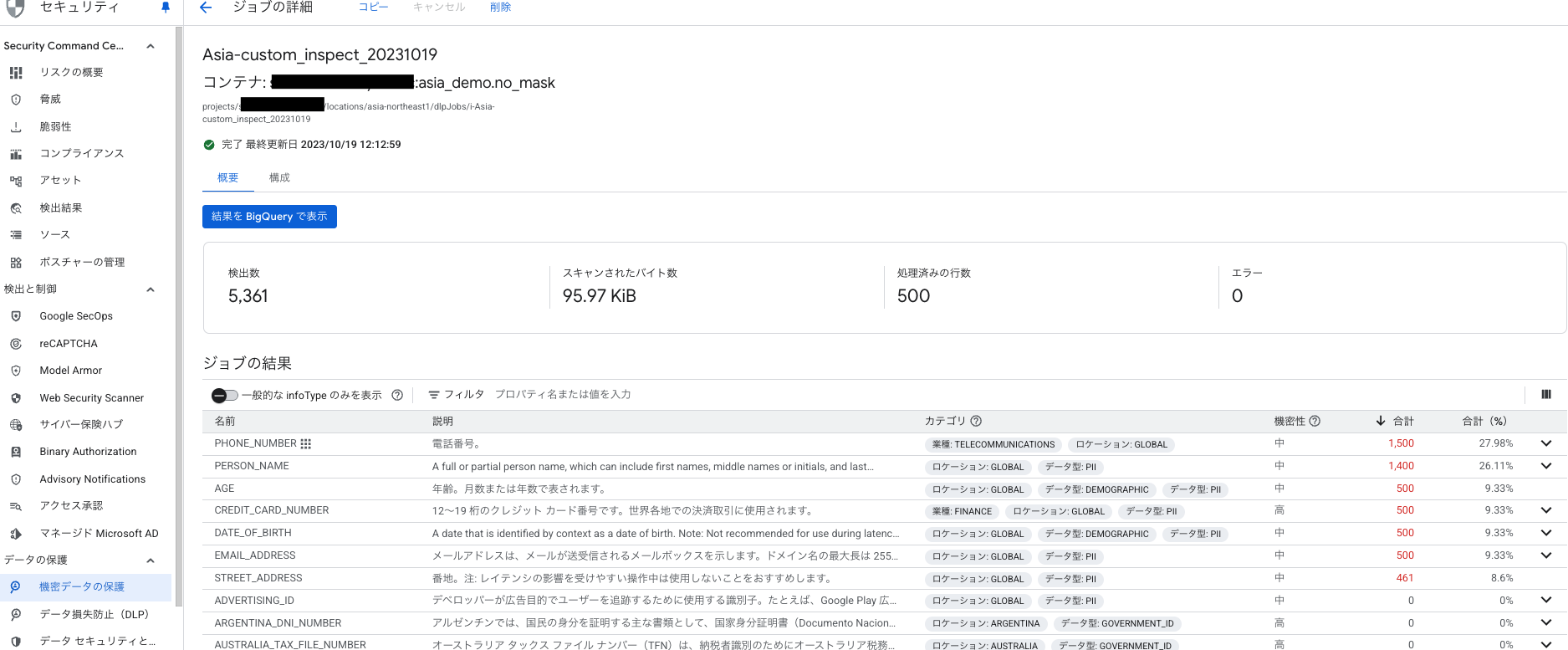
仕組み
Sensitive Data Protectionは、90種類以上の事前定義されたinfoType(例:クレジットカード番号、日本における個人番号)を使って、機密情報を高精度に検出します。検出したデータに対しては、以下の処理を実行できます。
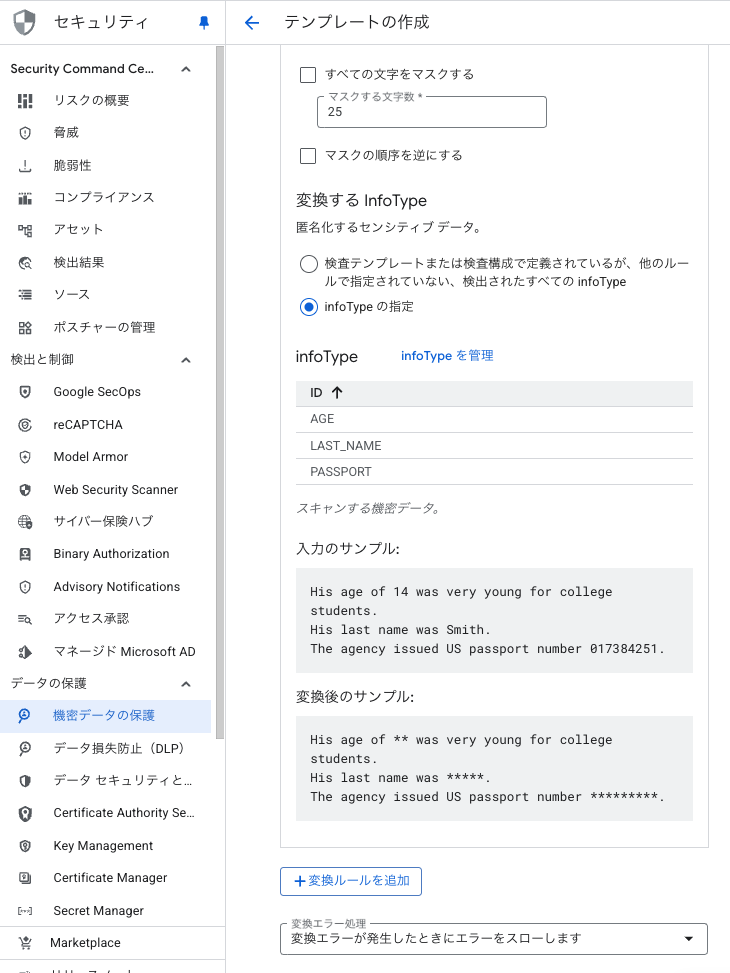
-
匿名化(Anonymization): 元のデータをハッシュ化、マスキング、または削除して、復元できない形に変更します。
-
トークン化(Tokenization): 元の機密データを、元の情報とは無関係な別名(トークン)に置き換えます。このトークンは、必要に応じて元の情報に戻すことが可能なため、データ活用の柔軟性を保ちます。
メリット
-
広範な適用範囲: BigQuery外のデータソースや、非構造化データにも適用可能です。
-
永続的な保護: 一度処理を施せば、そのデータは匿名化された状態で永続的に保存・共有されます。
-
強力な匿名化手法: ハッシュ化やトークン化など、様々なユースケースに対応する高度な匿名化手法を提供します。
デメリット
-
データの複製: データを匿名化された形式で永続的に保存する場合、元のデータと匿名化されたデータの2つを管理する必要があります。
-
コスト: SDPの利用には、処理したデータ量に応じた費用が発生します。特に大量のデータを扱う場合、コストを考慮する必要があります。
*参考
3. 2つのアプローチの決定的な違い
BigQueryのデータマスキングとSDPは、同じ「機密データ保護」という目的を持ちながらも、その役割とアプローチが大きく異なります。
BigQueryのデータマスキング
-
役割: BigQuery内のアクセス権限を管理する「ガードレール」です。
-
データの状態: データは物理的に変更されません。クエリ時に表示を制御するだけです。
-
ユースケース: 社内アナリストやBIユーザーが、セキュアな環境でデータ探索や分析する場合に最適です。
Sensitive Data Protection
-
役割: データを物理的に加工する「加工ツール」です。
-
データの状態: データは永続的に変更されます(匿名化、トークン化)。
-
ユースケース: BigQueryへのデータ取り込み前、またはAI学習データセットの作成時など、データが物理的に動くタイミングでの保護に最適です。
簡潔に言えば、BigQueryのデータマスキングは「誰がデータを見るか」を制御し、SDPは「データをどう加工するか」を制御するものです。
4. BigQueryとSensitive Data Protectionの連携によるハイブリッド戦略
どちらか一方を選ぶのではなく、両方を組み合わせることで、より強固なデータセキュリティ体制を構築できます。
| 機能 | 主な目的 | 適用タイミング | データの変更 | 主なユーザー |
|---|---|---|---|---|
| BigQuery データマスキング | BigQuery内のアクセス制御 | クエリ実行時 | 変更なし(表示のみ) | データアナリスト、BIユーザー |
| Sensitive Data Protection | データの加工と匿名化 | データ取り込み前、または外部連携時 | 永続的な変更 | データエンジニア、セキュリティ担当者 |
連携ユースケース
-
データ取り込み時の匿名化: 外部システムからBigQueryにデータを連携する際、Sensitive Data Protectionを使ってPIIをトークン化します。これにより、BigQueryに取り込まれる時点でデータが匿名化されます。
-
内部でのアクセス管理: トークン化されたBigQueryテーブルに対して、さらにBigQueryのデータマスキングを設定します。これにより、トークン化されたデータに対しても、部署や役割に応じたアクセス制御が可能になります。
このハイブリッド戦略により、データのライフサイクル全体にわたって、適切なセキュリティ対策を講じることができます。
まとめ:データ保護のレイヤーを築く
BigQueryのデータマスキングは、データガバナンスの観点から内部のデータアクセスを動的に制御するのに最適です。一方、Sensitive Data Protectionは、データそのものを永続的に加工することで、外部への持ち出しやAI活用におけるリスクを最小限に抑えます。
この2つの機能を適切に使い分けることで、セキュリティとデータ活用の両方を高いレベルで実現する、多層的なデータ保護戦略を構築できます。
データの機密性を守りながら、全社的なデータ活用を推進する。
その両立を実現するための第一歩として、この2つのツールの導入を検討してみてはいかがでしょうか。
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。