BigQuery UIデータ準備機能入門:クリック操作でデータ前処理を効率化
BigQueryに搭載されたUIベースのデータ準備機能の使い方、主な操作、セキュリティを含む注意点を解説します。
Table of contents
author: Chiakoba
はじめに
分析に適した形にデータを整えるこの作業は、分析プロジェクト全体の大半の時間を占めます。地味ですが、分析の精度を左右するとても重要な工程です。
でも。
「SQLを書くのが苦手…」
「どのデータをどう加工すればいいか、試行錯誤したいけど大変…」
「もっと手軽に、サクッとデータ準備を終わらせたい!」
と感じている方も多いはず。
そんな悩みを解決してくれる可能性があるのが、BigQueryに搭載されているUIベースのデータ準備機能です。ついにGAになったので、ご紹介します。
BigQueryのUIデータ準備機能ってどんなもの?
BigQueryのUIデータ準備機能は、SQLを記述することなく、画面上の操作でデータ準備するためのツールです。主な特徴は以下の通りです。
-
直感的なGUI: まるでExcelなどの表計算ソフトのように、画面上でデータを見ながら操作できます。
-
クリック操作中心: 列の分割、不要なデータの削除、データ型の変更などが、メニューから選んでクリックするだけで実行できます。
-
リアルタイムプレビュー: 操作の結果がすぐに画面に反映されるので、試行錯誤しながら最適な処理方法を見つけられます。
-
処理手順の自動記録(レシピ化): 行った操作は「レシピ」として自動で記録されます。同じ処理を繰り返したい時や、他の人に共有したい時に非常に便利です。
実際に使ってみよう!クリック操作でデータ整形
では、実際にどのように使うのか見ていきましょう!(※2025年4月時点のBigQuery UIをベースに説明します。ボタンの位置や名前は変更される可能性がある点はご了承ください)
1.データ準備機能へのアクセス
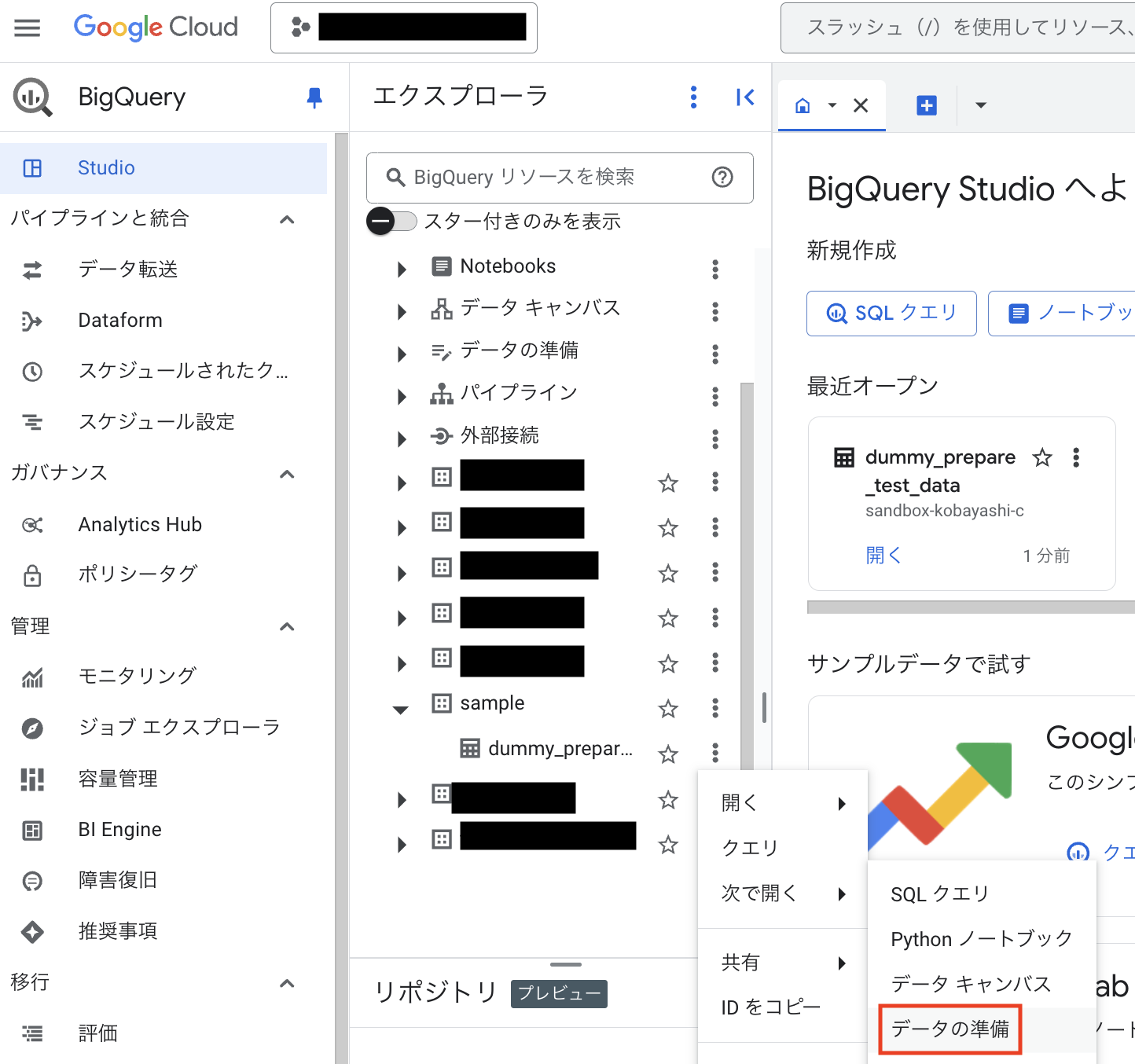
まず、コンソール画面から対象テーブルからデータの準備機能にアクセスします。
- BigQueryコンソールを開き、対象のデータセットから準備に使用したいテーブルを選択します。
- テーブルの詳細画面上部にあるメニューから、「エクスポート」や「クエリ」などと並んでいる箇所に、データ準備に関連するボタン(例:「データの準備」)を探してクリックします。
今回使用するデータについて:
この記事では、操作説明のために完全に架空のダミーデータを使用します。実際の業務で個人情報や機密情報を取り扱う際は、プライバシー保護とセキュリティに関する法令やガイドラインを遵守し、細心の注意を払ってください。可能であれば、個人情報に関連しないデータや、適切に匿名化・マスキングされたデータを使用することを強く推奨します。 GCPでは「Sensitive Data Protection」という機能で匿名化・マスキングを行うことができます。気になった際はご参照ください。
今回使用するダミーテーブル (dummy_prepare_test) のスキーマは以下の通りです。
id(INTEGER): ID (架空)age(STRING): 年齢 (数値、架空)birth_day(STRING): 生年月日 (YYYY-MM-DD形式、架空)company_name(STRING): 会社名 (架空、一部NULL値を含む)expiration_date(STRING): 有効期限 (MM/YY形式、架空)
2.基本的な操作例
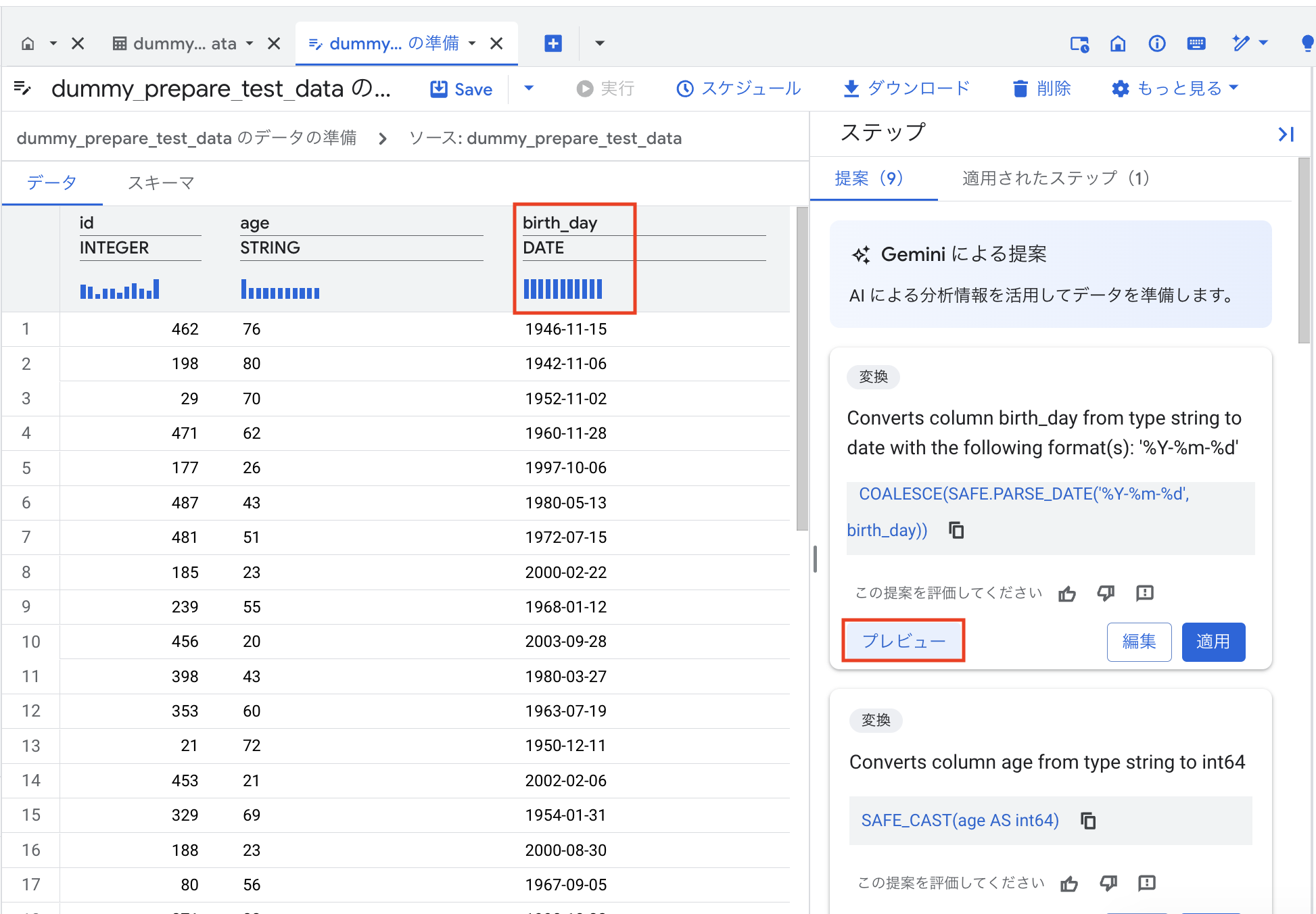
データ準備画面が開くと、テーブルデータがスプレッドシート形式で表示されます。
画面右側には、Geminiによるデータ変換の提案が表示されることもあります。
ここでは例として、birth_day 列のデータ型を STRING から DATE 型に変更してみましょう。
birth_day列を選択します。- 画面右側の「提案」や、列ヘッダーのメニューからデータ型変更の操作を選択します。(または、Geminiの提案から「データ型をDATEに変更」などを選択します)
プレビュー
「プレビュー」機能を使うと、変更を実際に適用する前に結果を確認できます。「プレビュー」ボタン(またはチェックボックス)を有効にすると、birth_day 列の型が STRING から DATE に変更された状態が画面に表示されます。この時点では、実際のテーブルデータは変更されていません。
編集
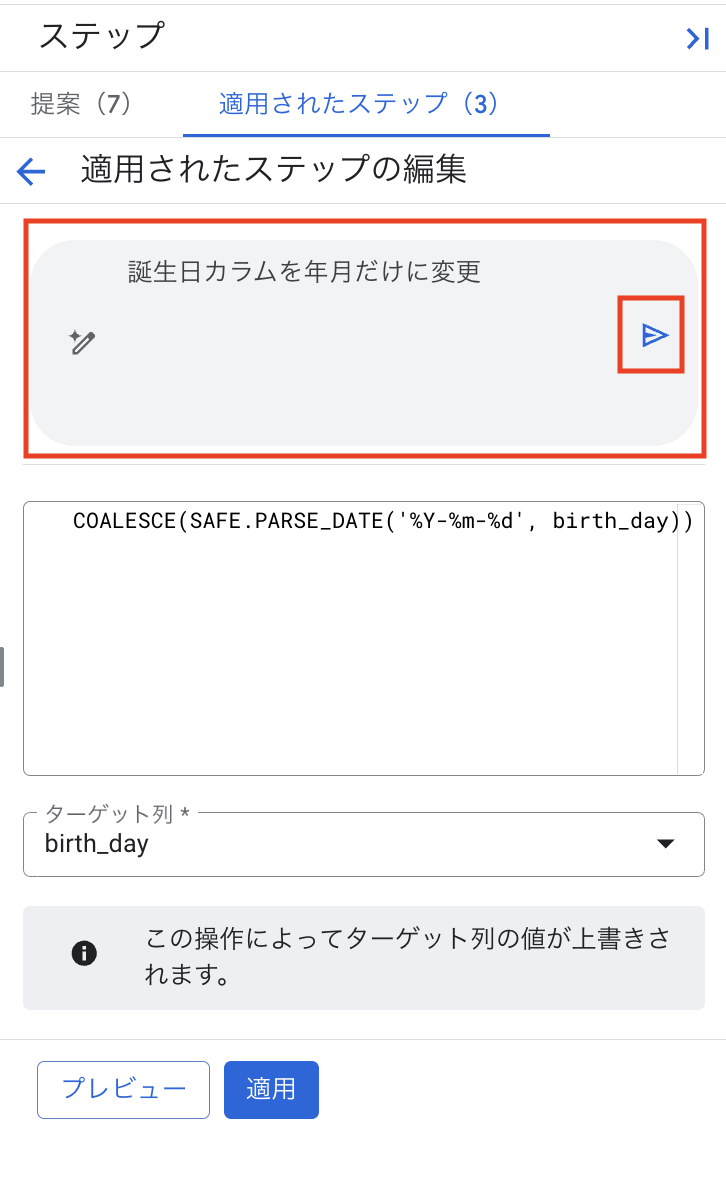
UI操作だけでなく、自然言語(日本語または英語)で指示してデータ変換できます。
- 画面右上の「ステップを追加」をクリックし、「編集」を選択します。
- 対象の列(例:
birth_day)を選択します。 - 「自然言語で記述」の入力欄に、実行したい処理内容を記述します(例:「日付形式をYYYY-MM-DDに変換」)。
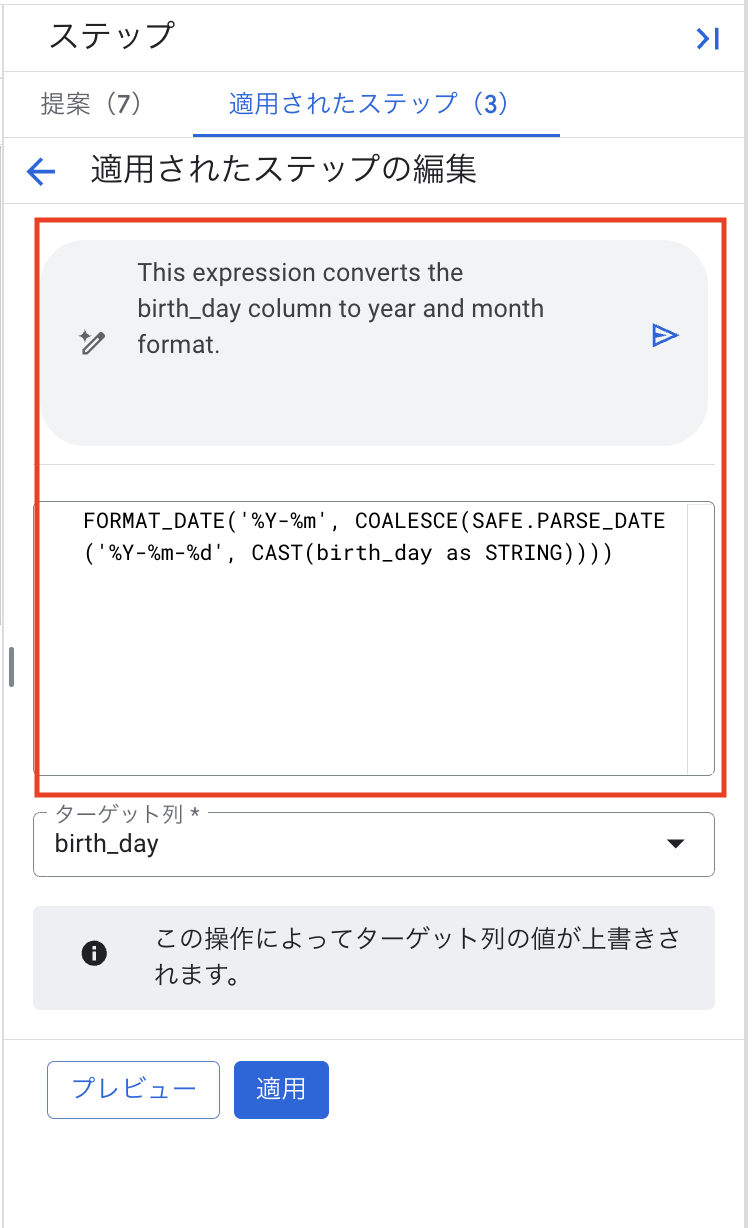
- 紙飛行機アイコンのボタンをクリックすると、指示に基づいた変換処理(内部的にはSQL関数などが生成されます)が提案されます。必要に応じて生成されたクエリを確認・編集できます。
適用
プレビューで問題がないことを確認したら、「適用」ボタンをクリックします。実行した操作が「レシピ」のステップとして画面右側の「適用されたステップ」に追加されます。
実行:データ変換ジョブの構成と実行
レシピにステップを追加しただけでは、実際のデータ変換は実行されません。
変換結果を新しいテーブルまたは既存のテーブルに書き出すためのジョブを実行する必要があります。
最後に更新するテーブルを指定し、サービスアカウントを設定する必要があります。 今回は「今すぐ実行」を試します。スケジュール実行も可能なので、バッチ実行が必要な場合も是非使ってみてください。
-
送信先(Destination)の設定:
- 画面右下の「ステップを追加」をクリックし、「送信先」を選択します。
- 変換結果を保存するデータセットとテーブル名を指定します。新しいテーブルを作成するか、既存のテーブルを上書きするかを選択できます。
- 今回は
dummy_prepare_testとして上書き保存します。(注意: 実際の運用では、命名規則に従った適切なテーブル名を設定してください。参考: テーブルの命名規則) - 設定後、「保存」ボタンをクリックします。
- 画面右下の「ステップを追加」をクリックし、「送信先」を選択します。
-
実行エクスペリエンスの構成:
- 画面右上部の「もっと見る」タブから「今すぐ実行エクスペリエンスを構成」を押してください。
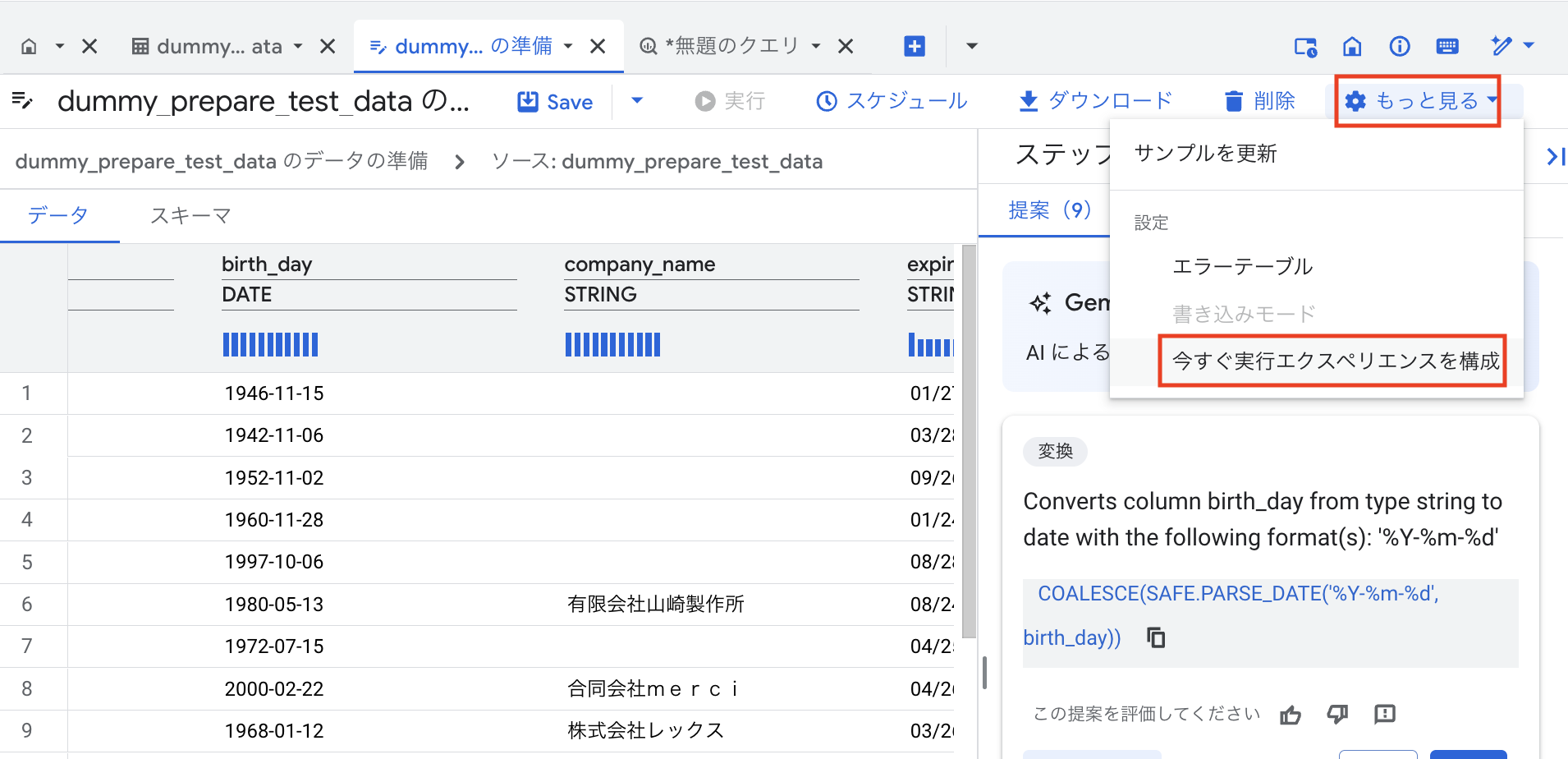
- データ変換ジョブを実行するためのサービスアカウントを指定する必要があります。
- サービスアカウントに関する重要な注意:
- 最小権限の原則: ジョブの実行に必要な最小限のIAMロール(例: サービスアカウントトークン作成者、サービスアカウントユーザー、BigQueryジョブユーザー)を付与した専用のサービスアカウントを使用してください。過剰な権限を与えないでください。
- キー管理: サービスアカウントのキー(JSONファイル)は安全に管理し、コードや設定ファイルに直接埋め込まないでください。可能であれば、キーを使用しない認証方法(Workload Identityなど)を検討してください。キーを使用する場合、適切に保管し、不要になったら削除してください。画像などにキー情報が決して含まれないように注意してください。
- 権限の確認: 指定したサービスアカウントに必要な権限(ソーステーブルの読み取り、宛先テーブルの書き込み、ジョブの実行権限など)が付与されていることを確認してください。権限が不足している場合は、IAM設定で適切に付与する必要があります。
- 構成画面でサービスアカウントを選択(または入力)します。サービスアカウントを選択した際に不足の権限が案内されます。
- 画面右上部の「もっと見る」タブから「今すぐ実行エクスペリエンスを構成」を押してください。
-
ジョブの実行:
- 構成が完了すると、「実行」ボタンが有効になります。
- 「実行」ボタンをクリックすると、ジョブとしてデータ変換処理がバックグラウンドで実行されます。ジョブの進捗状況はBigQueryの履歴画面で確認できます。
- ジョブが正常に完了すると、指定した送信先に変換後のデータが格納されたテーブルが作成(または上書き)されます。
-
結果の確認:
- BigQueryコンソールで、作成されたテーブル (
dummy_prepare_test) を開き、データ型が変更されていることなどを確認します。
- BigQueryコンソールで、作成されたテーブル (
3.よく使う操作例
データ準備機能では、データ型変更以外にも様々な処理が可能です。
例1:列の形式の変換
expiration_date 列の「MM/YY」形式を「YYYY-MM-DD」形式に変換する場合:
(例: “03/25” → “2025-03-01” のように、日付を月の初日に設定する)
- 「ステップを追加」から「変換」を選択し、「
expiration_date」列を選択します。 - 自然言語で「年を20XXとして、有効期限をYYYY-MM-DD形式にする。日付をMM/YY形式から、月の初日の日付を作成。形式が無効な場合はNULL。」のように指示します。
- プレビューで、日付形式が
YYYY-MM-DDに変換されていることを確認し、「適用」します。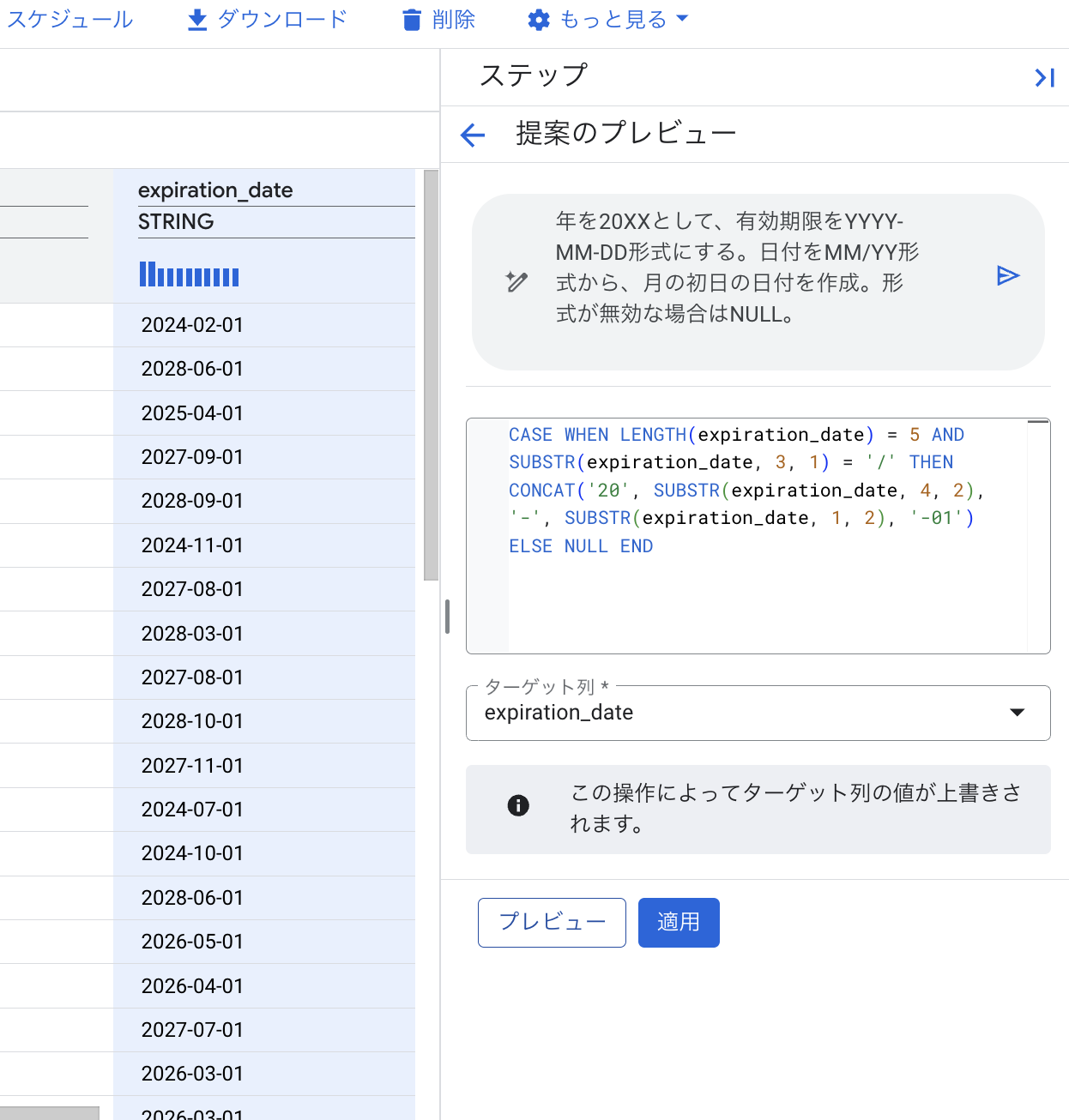
例2:NULL値の処理
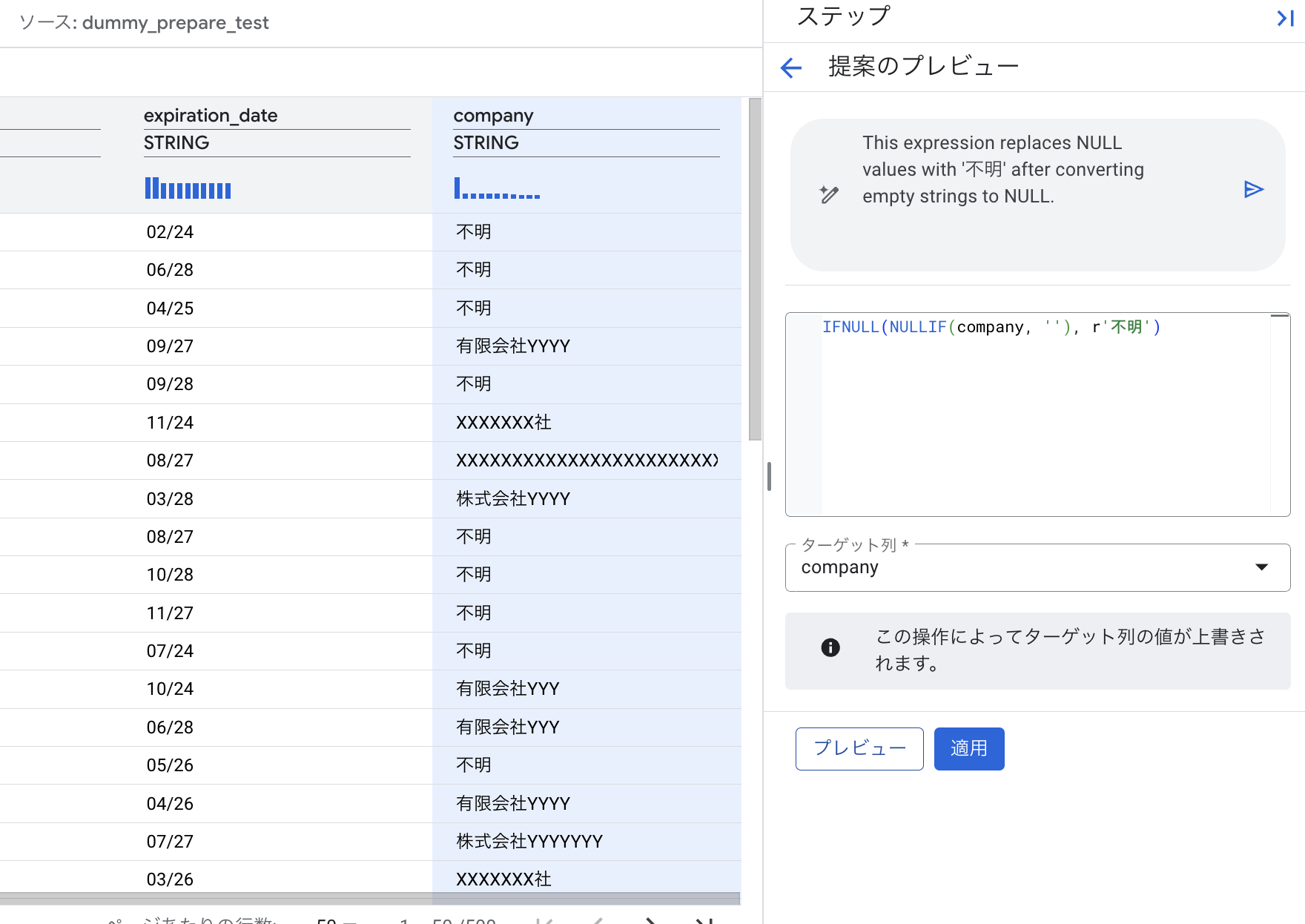
company_name 列のNULL値を特定の値(例: “不明”)で埋める場合:
- 「ステップを追加」から「変換」を選択し、「
company_name」列を選択します。 - 自然言語で「NULL値を’不明’に置換」と指示します。
- プレビューで、NULL値が「不明」に置換されていることを確認し、「適用」します。
例3:不要な行の削除
特定の条件に合致する行を削除する場合(例: age 列が70以上の行を除外):
- 「ステップを追加」から「フィルタ」を選択します。
- 「
age」列を指定します。 - 条件を設定します。自然言語で「70歳未満の行のみ保持」または「age < 70」のように指示します。
- プレビューで、指定した条件(
age >= 70)の行が除外され、行数が減少していることを確認し、「適用」します。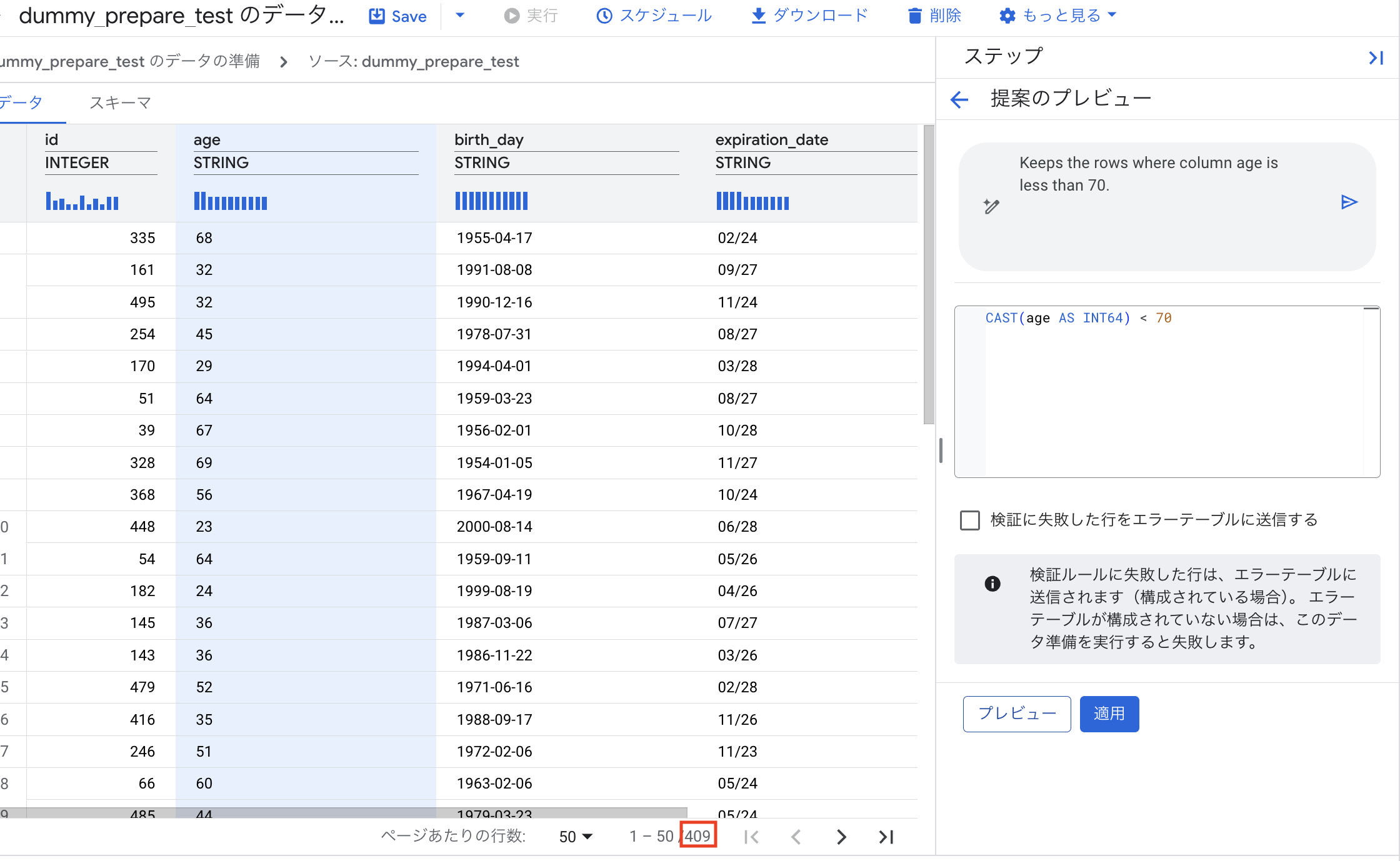
例4:テーブルの結合
別のテーブルとデータを結合する場合:
- 「ステップを追加」から「結合」を選択します。
- 結合したいテーブルを選択し、結合キーとなる列を指定します。
【重要】結合キーの選択について:
idのような一意の識別子(プライマリーキー、外部キー)を使用することが重要です。必ず一意な識別子を使用して結合してください。 プライマリーキーや外部キーが定義されていない場合は、結合に適切な列を選択する必要がありますが、その選択には十分な注意が必要です。 - 結合の種類(内部結合、左外部結合など)を選択します。今回は、性別とIDが格納されたテーブルと結合しましょう。
- 自然言語で「
dummy_prepare_test_genderテーブルとdummy_prepare_test列で内部結合する」のように、結合するテーブルとキー列を具体的に指示できます。(この例は、別のマスターテーブルが存在する場合を想定) - プレビューで結合結果を確認し、「適用」します。
- 外部結合でも両方の
idが出力されていたので、まだ結合機能は不安定な可能性があります。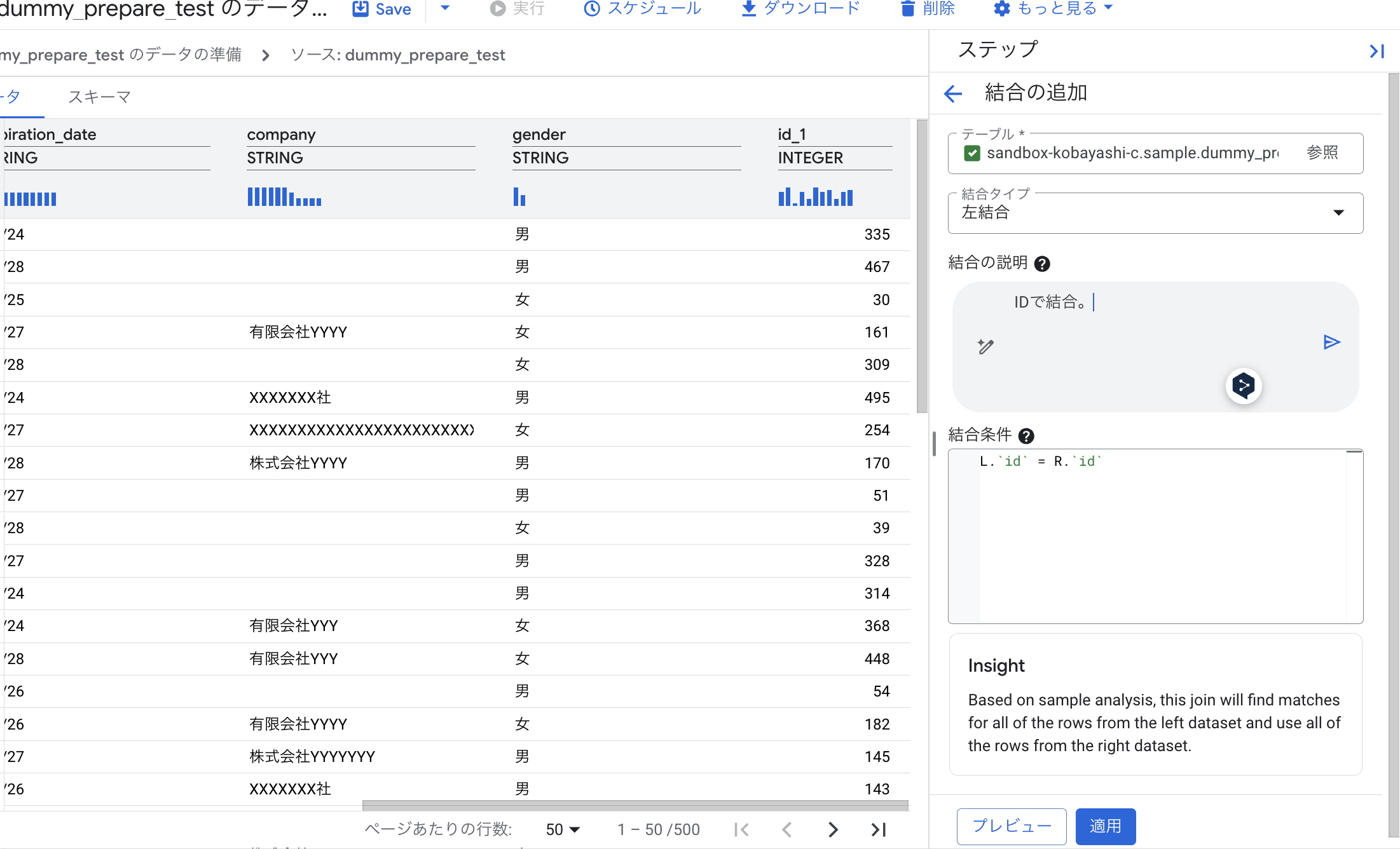
活用シーン
- Webサイトのアクセスログから、必要な情報だけを抽出して整形する。
- 広告媒体ごとのレポートデータを結合し、フォーマットを統一する。
- 顧客アンケートの自由回答欄から、特定のキーワードを含む回答を抽出する。
- CRMデータから、重複している顧客情報を整理する。
など、アイデア次第で様々な場面で活躍します。 特に、繰り返し行う必要があるデータ準備作業には最適です。
注意点
非常に便利な機能ですが、いくつか注意しておきたい点もあります。
-
生成AIの限界: Geminiを利用した変換処理は必ずしも期待通りの結果が得られるとは限りません。必要に応じてSQLを直接記述することを前提に、ご自身で正しいことを確認した上で、使用ください。
-
超大規模データ: あまりにもデータ量が大きい場合、ブラウザ上での処理に時間がかかったり、動作が不安定になったりする可能性もゼロではありません。そのような場合は、SQLバッチ処理などを検討する方が効率的なこともあります。
-
ステップの粒度: 自然言語での指示は便利ですが、現時点では1つの指示で複数の異なる操作(例: 型変換とNULL置換を同時に)を正確に実行できない場合があります。期待通りに動作しない場合は、操作を個別のステップに分割することを推奨します。
-
複雑すぎる処理: 非常に多くのステップや、高度なロジックが必要な処理は、UI操作だけでは限界がある可能性があります。SQLの方が柔軟に対応できる場面もあります。
-
エラー処理: データ準備ジョブがエラーで失敗した場合、BigQueryのログを確認して原因を特定し、レシピや元データを修正する必要があります。
-
セキュリティ:
- 機密データの取り扱い: BigQueryに個人情報や機密データが含まれる場合、データ準備プロセス全体を通してアクセス権限管理やマスキングなどのセキュリティ対策を徹底してください。
- サービスアカウントの管理: 前述の通り、サービスアカウントの権限は最小限にし、キーは安全に管理してください。不要になったサービスアカウントやキーは速やかに削除します。
-
料金: (もし該当する場合) 利用する機能によっては、処理時間やデータ量に応じて料金が発生する場合があります。事前に料金体系を確認しておくと安心です。
SQLでのデータ準備とUIでのデータ準備、どちらか一方だけを使うのではなく、データの規模や処理の複雑さに応じて使い分けるのがおすすめです。
\さっそく試してみよう!/
GoogleCloud公式ドキュメント: 例:BigQuery データ の準備の概要
まとめ
生成AIの登場で、データ活用の世界も少しずつ楽になってきていると言えるのではないでしょうか。 BigQueryのUIデータ準備機能は、SQLに慣れていないユーザーでも直感的な操作でデータ前処理を行える強力なツールです。リアルタイムプレビューやレシピ化といった機能により、試行錯誤や定型作業の効率化が期待できます。
一方で、大規模データや複雑な処理への対応、セキュリティに関する考慮事項など、注意すべき点も存在します。これらの特性を理解し、SQLによる処理と組み合わせながら活用することで、データ分析プロセス全体の生産性を向上させることができるでしょう。ぜひ、この便利な機能を試してみてください。
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。