【2025年12月】AIエージェントの「計画」能力からGraphRAGの進化まで。実装の壁を突破する注目論文5選
ArXivのAIに関する論文を厳選して紹介。
Table of contents
author: ryutah
こんにちは、イノベーショングループのryutahです。
2025年も終わりに近づき、AI研究のトレンドは「LLM単体の性能向上」から、「LLMを核としたシステム全体の信頼性と効率性」へと明確にシフトしています。特に、自律型エージェントの計画能力(Planning)、GraphRAG(グラフ検索拡張生成)の実用化、そしてモデルのエネルギー効率に関する議論が活発です。
今回は、2025年12月に公開された最新のArXiv論文の中から、AIエンジニアやリサーチャーが今読むべき5本の論文を厳選して紹介します。古典的なシンボリックAIとLLMの融合から、小規模モデル(SLM)活用の意外な落とし穴まで、実装のヒントが詰まった研究ばかりです。
1. LLMの「幻覚」をPDDLで縛る。完全自動化された計画フレームワーク
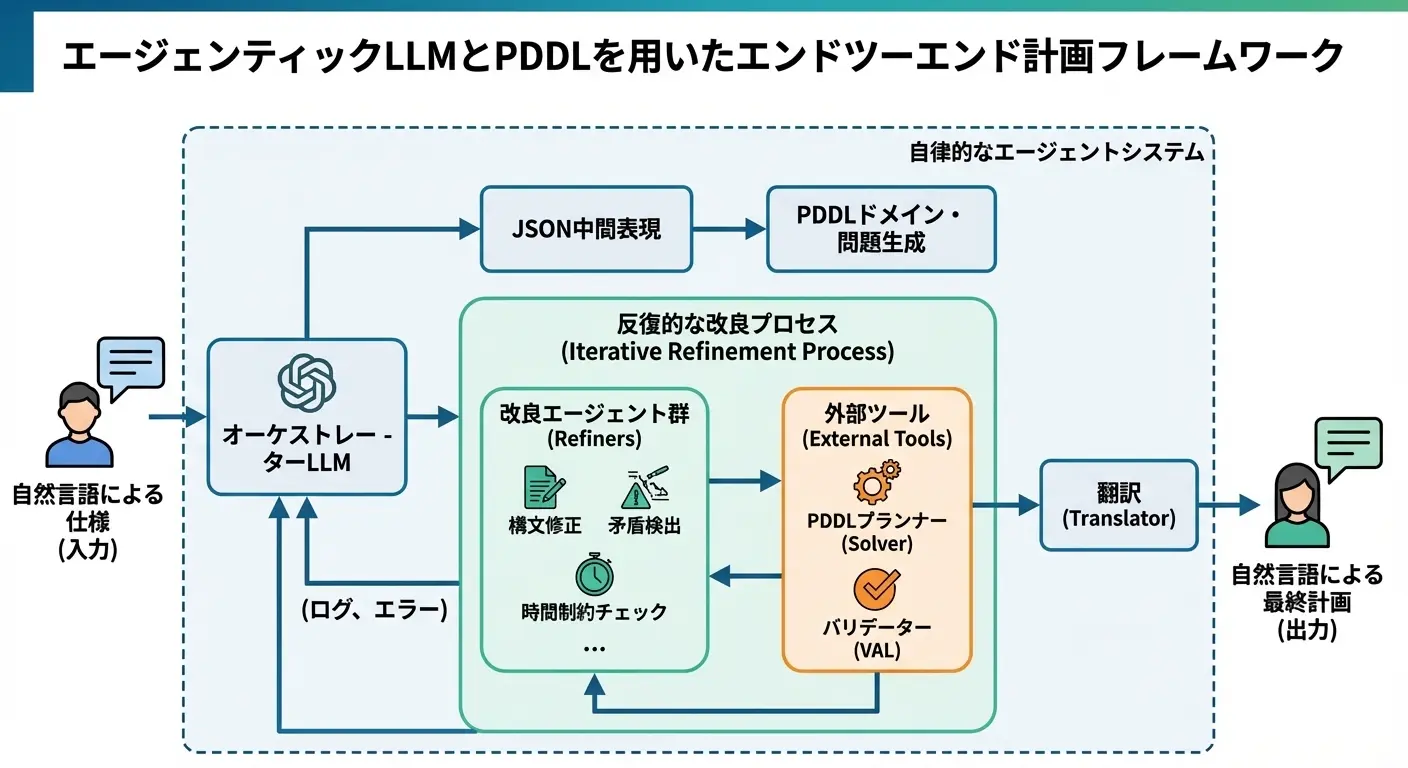
タイトル: An End-to-end Planning Framework with Agentic LLMs and PDDL
論文要約
大規模言語モデル(LLM)は自然言語の解釈に優れていますが、長期的な計画立案においては整合性を欠きがちです。一方、古典的な自動計画記述言語(PDDL)は厳密な解を保証しますが、専門知識が必要で柔軟性に欠けます。 本研究は、この両者を統合したエンドツーエンドのフレームワークを提案しています。
- 動的オーケストレーション: 自然言語の指示をLLMがJSON→PDDLへと変換し、ソルバー(Fast Downward等)で解を探索します。
- 自己修正ループ: ソルバーのエラー(構文ミスや解なし)を検知すると、オーケストレーターが「構文修正」「論理整合性チェック」などの専門サブエージェントを動的に呼び出し、PDDLを修正します。
- 成果: GPT-5-miniをベースに、Google Natural PlanやPlanBenchなどでベースラインを12〜15%上回る精度を達成し、計画コストを約45%削減しました。
🖊️ 一言コメント
「ニューロ・シンボリックAI」の実用的な解の1つです。LLMにすべてを推論させるのではなく、「翻訳(LLM)」と「検証(PDDLソルバー)」の役割分担を明確にした点が勝因でしょう。特に、エラーメッセージに基づいて動的にサブエージェントを呼び出すLangGraphベースの設計は、堅牢なエージェント開発の参考になります。
2. 「小さいモデル=省エネ」は間違い? SLMエージェントの不都合な真実
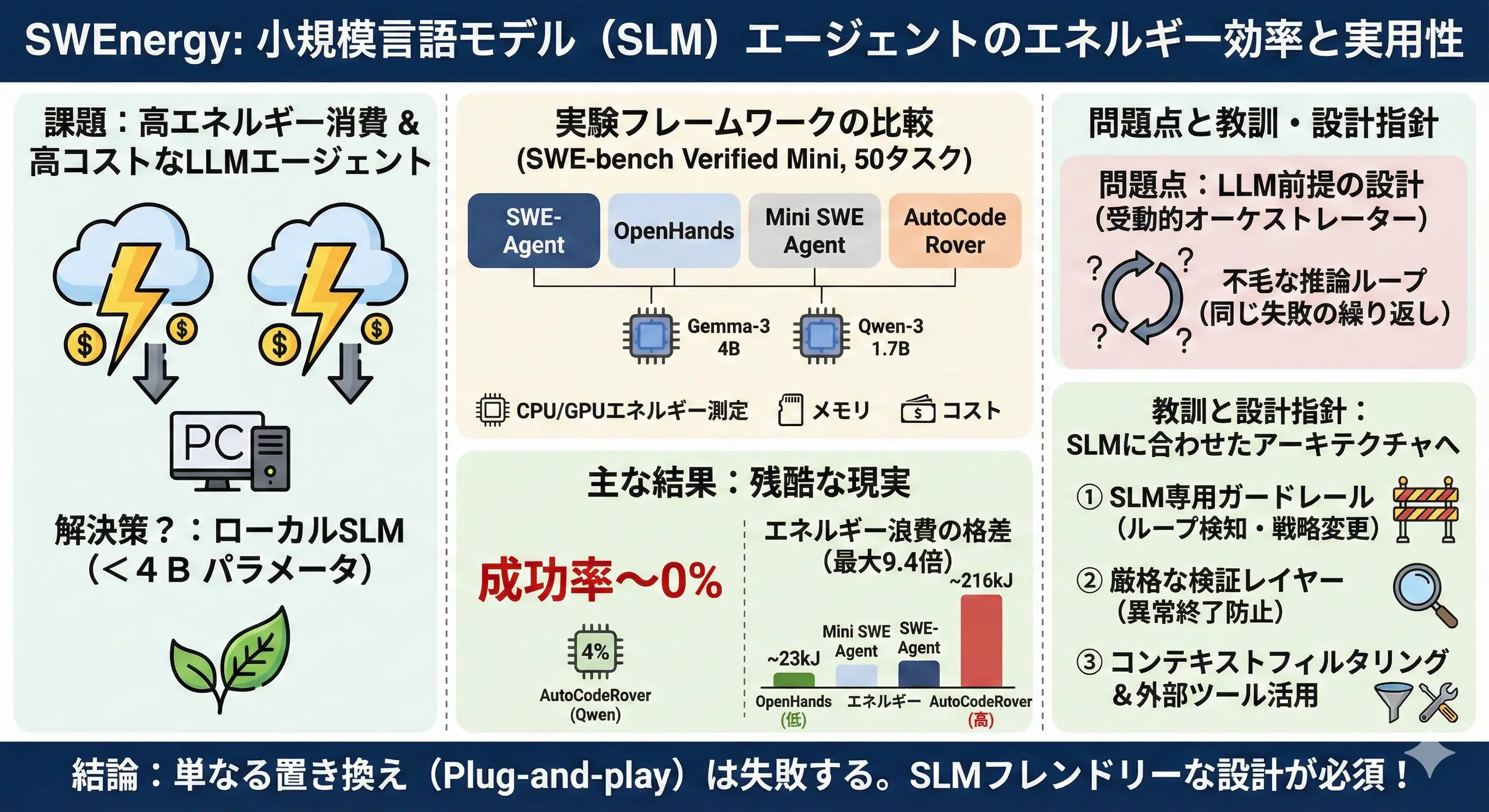
タイトル: SWEnergy: An Empirical Study on Energy Efficiency in Agentic Issue Resolution Frameworks with SLMs
論文要約
ソフトウェアエンジニアリングタスク(GitHubの課題解決など)において、コスト削減のために小規模言語モデル(SLM)の利用が検討されています。しかし、実際にSLM(Gemma-3 4B, Qwen-3 1.7Bなど)を既存のエージェントフレームワーク(SWE-Agent等)に組み込んでエネルギー効率を測定したところ、衝撃的な結果が得られました。
- 解決率の低迷: ほとんどの構成でタスク解決率は0%〜4%と壊滅的でした。
- エネルギーの浪費: SLMは推論能力不足により、同じコマンドを繰り返す無限ループや、タイムアウトまでの長時間稼働を引き起こしやすく、結果としてタスクを解決できないまま大量の電力を消費するケースが多発しました。
- 結論: 単にモデルを小さくするだけではGreen AIにはなりません。SLM特有の弱点を補う能動的なガードレールが必要です。
🖊️ 一言コメント
直感に反する非常に重要な実証研究です。「推論コスト(API単価)」と「総エネルギー消費」は別物であることを突きつけています。SLMをエージェントに使うなら、「早期失敗(Fail Fast)」のメカニズムや、ループ検知機能をフレームワークレベルで実装しないと、安物買いの銭失い(かつ環境負荷増)になりかねません。
3. テキストかグラフか、強化学習が選ぶ。次世代の適応型RAG
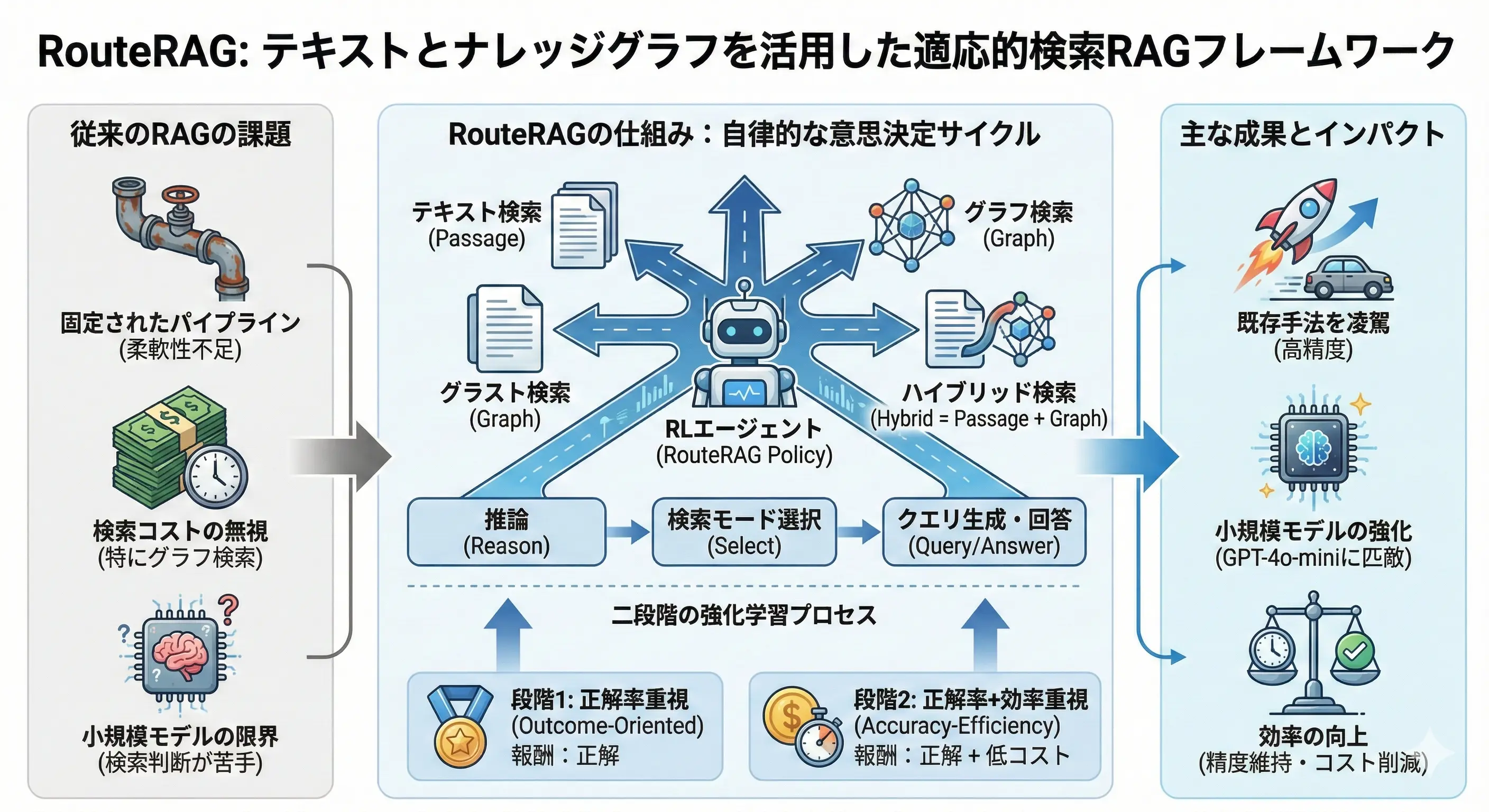
タイトル: RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning
論文要約
従来のRAGはテキスト検索が主でしたが、複雑な推論にはナレッジグラフ(KG)が有効です。しかし、常にKGを検索するのはコストがかかります。 RouteRAGは、強化学習(PPO/GRPO)を用いて、「いつ」「どこから(テキスト/グラフ/両方)」情報を取得するかを動的に判断するフレームワークです。
- 統合ポリシー: LLMが推論、検索モード選択(
[passage],[graph],[hybrid])、回答生成を一貫して行います。 - 効率性報酬: 正解率だけでなく、「検索にかかった時間(コスト)」を報酬関数に組み込むことで、必要な時だけ高コストなグラフ検索するように学習させました。
- 成果: 7Bクラスのモデルで、GPT-4o-miniを用いたSOTA手法(HippoRAG 2)を凌駕する性能を達成しました。
🖊️ 一言コメント
RAGの「ルーティング」をルールベースではなく、強化学習で最適化するアプローチです。特筆すべきは、「検索コスト」を報酬に入れた点。これにより、簡単な質問は即答し、難しい推論だけグラフを使うという、人間のようなメリハリのある挙動が実現できています。小規模モデルが高性能モデルに勝る可能性を示した点でも勇気づけられる研究です。
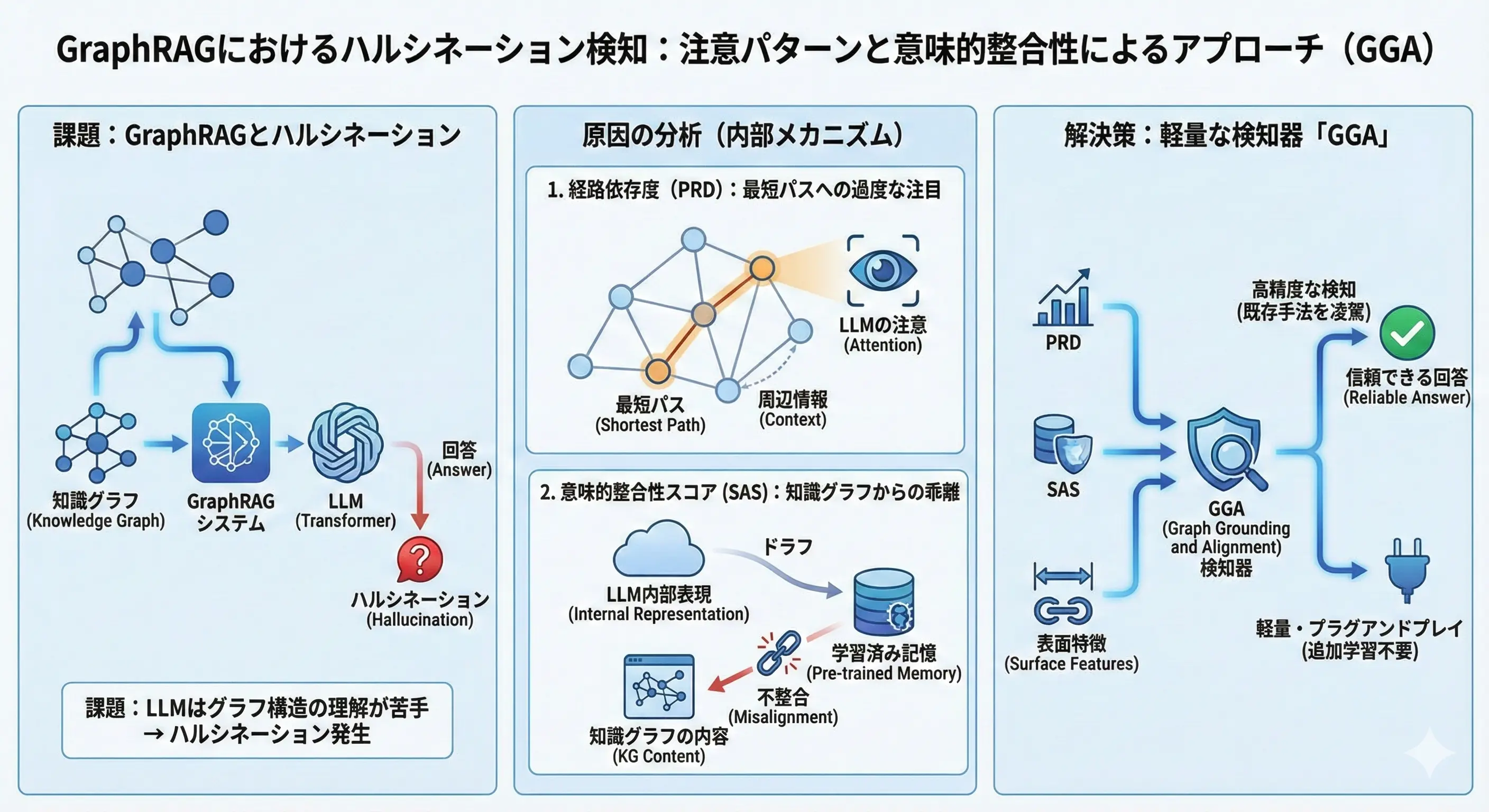
4. GraphRAGでもハルシネーションは起きる。そのメカニズムと検出
論文要約
構造化データを使うGraphRAGは信頼性が高いと思われがちですが、特有のハルシネーションが発生します。本研究はその原因を解明し、検出器GGAを提案しました。
- 原因の特定:
- 最短経路への過依存 (PRD): モデルがグラフ全体の文脈を無視し、特定の「近道(Shortcut)」トリプルだけにアテンションを集中させてしまう。
- 意味的逸脱 (SAS): 検索された知識よりも、モデル自身の学習済み知識(パラメトリックメモリ)を優先してしまい、内容が乖離する。
- 検出手法: 上記の傾向を定量化するメトリクス(PRDとSAS)を開発し、これを用いた軽量な分類器でハルシネーションを高精度に検出することに成功しました。
🖊️ 一言コメント
GraphRAGの実装者にとって必読の論文です。「正しいサブグラフを渡しているのに嘘をつく」現象の正体が、LLMの「近道学習」的なアテンションの偏りにあるという指摘は鋭いです。提案されているメトリクスは計算コストが低いため、実システムの品質モニタリング機能として組み込みやすいでしょう。
5. 対話エージェントの研究を加速する。解釈可能性まで統合した「SDialog」
論文要約
対話システムの構築、データ生成、評価、そして内部解析までをワンストップで行えるPythonツールキット「SDialog」が登場しました。

- 統合設計: エージェント定義、ユーザーシミュレーション、3D音響シミュレーション(部屋の反響なども再現)、評価モジュールが統一された
Dialogオブジェクトで連携します。 - 解釈可能性(Interpretability)の民主化 : 最大の特徴は、対話生成プロセスへの メカニスティック・インタープリタビリティ(機械論的解釈可能性) の統合です。特定の振る舞いベクトルを除去(アブレーション)したり注入したりする実験が、数行のコードで実行可能です。
- 実験: 8Bモデルの対話において、有害なプロンプトへの拒絶反応をベクトル操作でON/OFFできることを実証しました。
🖊️ 一言コメント
研究者泣かせだった「バラバラなツールチェーン」を統合してくれる神ツールです。特に、 「対話生成」と「内部解析(介入実験)」がセットになっている点 が画期的。エージェントがなぜその回答をしたのかを分析したり、特定の振る舞いを強制したりする実験が劇的に楽になるはずです。
まとめ
今回紹介した論文からは、AIエージェント技術が「動けばいい」というフェーズを過ぎ、 「いかに確実に、効率よく、説明可能な形で動作させるか」 という実用化の深化フェーズに入ったことが読み取れます。
- PDDLや強化学習による制御性の向上
- SLM利用時のエネルギー効率の再考
- GraphRAGにおけるハルシネーションの構造的理解
これらは、2026年のAI開発において避けて通れない論点となるでしょう。皆さんのプロジェクトでも、これらの知見をぜひ活かしてみてください。
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。