Reasoning Engine(LangChain on Vertex AI)でLangGraphのエージェントを動かす
Reasoning EngineのテンプレートをカスタムしたLangGraphのエージェント構築まで解説します。
Table of contents
author: Shintaro
はじめに
Google Cloud Next’24で発表されたReasoning Engine(LangChain on Vertex AI)で、
LangGraphを使ったエージェントを構築する流れをご紹介します。
2024/9時点で特に日本語の情報が少ないため、少しでも参考になれば幸いです。
おことわりと注意
- LangChainやLangGraphが何かといったことは解説しません。
- Reasoning Engine(およびLangChain on Vertex AI)は2024/9時点でプレビューの機能です。
Reasoning Engine(LangChain on Vertex AI)とは
Reasoning Engineとは、LLMアプリ構築のための「様々な」オーケストレーションフレームワークがデプロイできる、マネージドなランタイム環境です。
「様々な」と書きましたが、LangChainのみならず、LlamaIndexなども使用できます。
概要や便利な点などはGoogle Cloudの方が書かれたZennの記事がありますので、そちらに譲ります。
事前定義されているreasoning_engines.LangchainAgentのテンプレートをカスタムして、
簡単なHuman-in-the-loopなどが可能なLangGraphのエージェント構築まで発展させている点で、
ある程度具体的な情報を求めている方の助けになればと思っています。
基本的なエージェントの構築
まずは公式ドキュメントに沿う形で要点をかいつまみながら、
環境構築からGoogle Cloudへのデプロイまで進めます。
環境構築
以下が必要です。簡単な補足とともに列挙します。
-
Cloud Storageのバケット作成
- Google Cloudへのデプロイの際に使います。
-
ライブラリのインストール
- インポートの際に
ImportError: cannot import name 'reasoning_engines' from 'vertexai.preview'のようなエラーが出る場合は、pip install google-cloud-aiplatform --upgradeでパッケージを更新すると良いとのことです。
- インポートの際に
-
サービスエージェントに必要な権限を付与
- 各種リソースへのアクセスが必要な場合は
service-PROJECT_NUMBER@gcp-sa-aiplatform-re.iam.gserviceaccount.comに権限を付与します。 - 今回は不要です。
- 各種リソースへのアクセスが必要な場合は
それぞれの具体的な方法はドキュメントをご確認ください。
ライブラリのインストールについて
- 依存関係の管理が面倒だったので、Poetryで進めていきます。
- 上記「ライブラリのインストール」の手順は、あらかじめ
poetry initでプロジェクトを作成したうえで、poetry add "google-cloud-aiplatform[reasoningengine,langchain]=1.66"コマンドを実行してください。 - 2024/9時点で、サポートされているPythonのバージョンは3.8~3.13です。
pyproject.tomlに記載のバージョンにご注意ください。今回はpython = ">=3.10, <3.13"としています。 - ここまでで、
pyproject.tomlファイルが以下のようになっている想定で進めていきます。
- 上記「ライブラリのインストール」の手順は、あらかじめ
[tool.poetry]
name = "sample"
version = "0.1.0"
description = ""
authors = ["sample"]
readme = "README.md"
[tool.poetry.dependencies]
python = ">=3.10, <3.13"
google-cloud-aiplatform = {extras = ["langchain", "reasoningengine"], version = "^1.66.0"}
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
構築
最初に、オプショナルな手順をすべて割愛した、
ローカルで動く最もシンプルなコードをお見せします。
from vertexai.preview import reasoning_engines
def main():
model = "gemini-1.5-flash-001"
agent = reasoning_engines.LangchainAgent(
model=model, # Required.
)
response = agent.query(input="日本の首都はどこですか?")
print(response)
if __name__ == "__main__":
main()出力例は以下です。
{'input': '日本の首都はどこですか?', 'output': '日本の首都は **東京** です。 \n'}上記の最もシンプルなものにGoogle検索ツールを追加して、少しだけアレンジします。
差異を明確にするため、
クエリを例えば「麻布台ヒルズの開業日はいつですか?」のように変えてみてください。
(検索しないとわからないような新しめの情報であればなんでも良いです)
現時点で、出力として以下のようなものが返ってきます。
{'input': '麻布台ヒルズの開業日はいつですか?', 'output': '麻布台ヒルズは、**2023年6月23日**に開業しました。 \n'}※普通に間違っている回答です。正しくは、2023年11月24日です。
以下のコードを追加します。
from vertexai.generative_models import grounding, Tool
grounded_search_tool = Tool.from_google_search_retrieval(
grounding.GoogleSearchRetrieval()
)そして、エージェントの定義を以下のように修正します。
agent = reasoning_engines.LangchainAgent(
model=model,
tools=[grounded_search_tool], # 追加
)改めて実行すると、以下の出力が返ってきます。
{'input': '麻布台ヒルズの開業日はいつですか?', 'output': '麻布台ヒルズは、2023年11月24日に開業しました。 \n'}Google検索ツールが使用されたため、
新しい情報に関する質問にも応答できるようになりました。
ちょっと休憩 - 使用するモデルをClaude 3 Haikuに変更
Reasoning Engineでは、Vertex AI以外の外部のモデルも使用できます。
余談として、Claude 3 Haikuの使用を試してみます。
※AnthropicのAPIキー取得を事前にお願いします。
- ライブラリのインストール
langchain_anthropicはバージョンを指定してください
poetry add "langchain_anthropic=0.1" python-dotenv- コードの修正
import os
from dotenv import load_dotenv
from vertexai.preview import reasoning_engines
load_dotenv()
# 追加
def model_builder(*, model_name: str, model_kwargs=None, **kwargs):
from langchain_anthropic import ChatAnthropic
return ChatAnthropic(model_name=model_name, **model_kwargs)
def main():
model = "claude-3-haiku-20240307"
os.environ["ANTHROPIC_API_KEY"]
agent = reasoning_engines.LangchainAgent(
model=model, # Required.
model_builder=model_builder, # Required.
model_kwargs={
"max_tokens": 1000, # Optional.
},
)
response = agent.query(input="日本の首都はどこですか?")
print(response)
if __name__ == "__main__":
main()- 出力例 - 日本の首都はどこですか?
{'input': '日本の首都はどこですか?', 'output': '日本の首都は東京です。\n\n東京はこれまで「大阪」、「京都」など、他の都市が首都であった時期もありましたが、1869年に明治政府により東京が新しい首都に選ばれて以来、日本の中心的な都市として重要な役割を果たしてきました。\n\n東京は面積が広く、人口も約1400万人と日本最大の都市です。政治、経済、文化の中心地として君臨しており、日本のシンボル的存在といえます。'}- 出力例 - 麻布台ヒルズの開業日はいつですか?
{'input': '麻布台ヒルズの開業日はいつですか?', 'output': '申し訳ありませんが、「麻布台ヒルズ」の正確な開業日については、確認できる情報がありませんでした。\n\n一般的に、大規模な建築物の開業時期については、事前に広く公表されることが多いのですが、この物件に関しては詳細な情報が見つからなかったようです。\n\n開業時期については、建築主やデベロッパー、あるいは地元自治体などに問い合わせるのが良いかもしれません。竣工準備の状況によって開業時期が変わる可能性もありますので、最新の情報を確認することをおすすめします。'}Anthropicのモデルに設定した状態でGoogle検索のツールを使うとNotImplementedError()というエラーが出ました。
つまり、以下のような状態では動かないということです。
import os
from dotenv import load_dotenv
from vertexai.generative_models import Tool, grounding
from vertexai.preview import reasoning_engines
load_dotenv()
grounded_search_tool = Tool.from_google_search_retrieval(
grounding.GoogleSearchRetrieval()
)
def model_builder(*, model_name: str, model_kwargs=None, **kwargs):
from langchain_anthropic import ChatAnthropic
return ChatAnthropic(model_name=model_name, **model_kwargs)
def main():
model = "claude-3-haiku-20240307"
os.environ["ANTHROPIC_API_KEY"]
agent = reasoning_engines.LangchainAgent(
model=model,
model_builder=model_builder,
model_kwargs={
"max_tokens": 1000,
},
tools=[grounded_search_tool],
)
response = agent.query(input="麻布台ヒルズの開業日はいつですか?")
print(response)
if __name__ == "__main__":
main()LangChainのツールも使えますので、素直にそちらを使いましょう。
では本筋に戻ります。
デプロイ
改めると、コードは以下の状況になっています。
from vertexai.generative_models import Tool, grounding
from vertexai.preview import reasoning_engines
grounded_search_tool = Tool.from_google_search_retrieval(
grounding.GoogleSearchRetrieval()
)
def main():
model = "gemini-1.5-flash-001"
agent = reasoning_engines.LangchainAgent(
model=model,
tools=[grounded_search_tool],
)
response = agent.query(input="麻布台ヒルズの開業日はいつですか?")
print(response)
if __name__ == "__main__":
main()こちらに以下のような修正を加えて、デプロイします。
※「デプロイ」は「Reasoning Engineのインスタンスを作る」という表現になるようです。
import os
import vertexai
from vertexai.generative_models import Tool, grounding
from vertexai.preview import reasoning_engines
vertexai.init(
project=os.environ.get("PROJECT_ID"),
location="us-central1",
staging_bucket=os.environ.get("STAGING_BUCKET"),
)
grounded_search_tool = Tool.from_google_search_retrieval(
grounding.GoogleSearchRetrieval()
)
def main():
model = "gemini-1.5-flash-001"
remote_app = reasoning_engines.ReasoningEngine.create(
reasoning_engines.LangchainAgent(
model=model,
tools=[grounded_search_tool],
),
# パッケージのバージョンは指定することを推奨
requirements=[
"python-dotenv==1.0.1",
"google-cloud-aiplatform[reasoningengine,langchain]==1.66.0",
],
)
print(f"{remote_app.resource_name=}")
if __name__ == "__main__":
main()remote_app.resource_nameの"projects/PROJECT_ID/locations/LOCATION/reasoningEngines/REASONING_ENGINE_ID"が呼び出す際に必要なリソース名です。
デプロイしたエージェントを動かす
Reasoning Engineのインスタンスに対してクエリを投げます。
from vertexai.preview import reasoning_engines
def main():
remote_app = reasoning_engines.ReasoningEngine("projects/PROJECT_ID/locations/LOCATION/reasoningEngines/REASONING_ENGINE_ID")
# 以下でも可
# remote_app = reasoning_engines.ReasoningEngine("REASONING_ENGINE_ID")
response = remote_app.query(input="麻布台ヒルズの開業日を教えてください")
print(response)
if __name__ == "__main__":
main()出力はローカル実行の際と同じため割愛します。
Cloud Traceによるトレーシング
LLMアプリにおけるObservabilityも徐々に情報が増えてきています。
一例を挙げると、DatadogからLLM Observabilityという機能が一般提供開始になるなどしています。
Reasoning Engineでは以下のように、パラメータを1つ加えるだけでCloud Traceと連携できます。
model = "gemini-1.5-flash-001"
agent = reasoning_engines.LangchainAgent(
model=model,
tools=[grounded_search_tool],
enable_tracing=True, # 追加
)LangSmithと似たような感じで、各Chainをスパンとして記録します。
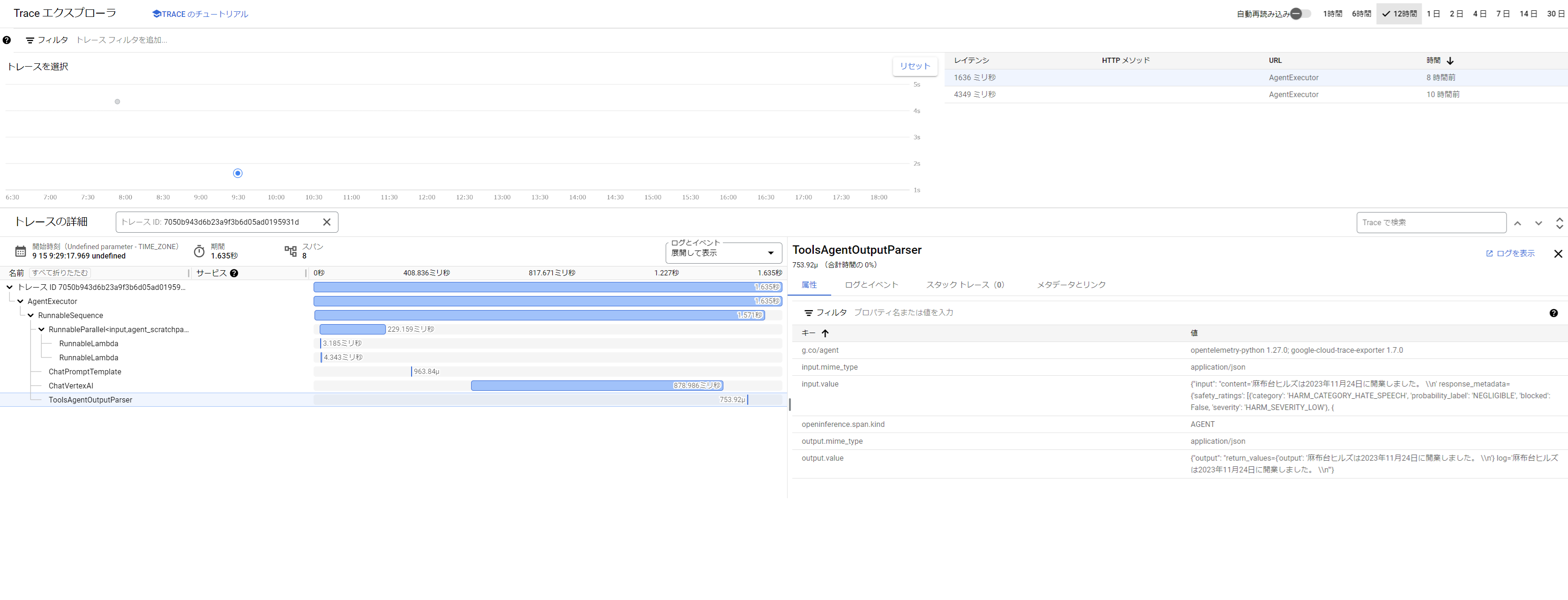
以下のような指標が取得できます。
- モデル名
- 入力に対する出力の結果
- Agentが実行したChainの履歴と、各Chainにおける入出力結果
- 消費トークン数
- 開始時刻
- レイテンシー
なお、次にご紹介するカスタムされたアプリの場合は、
Open Telemetryと、OpenInferenceまたはOpenLLMetryのような
フレームワークを組み合わせてトレースを取得する必要があります。
LangGraphによるカスタムエージェント構築
Human-in-the-loopなど、フレームワーク内でエージェントの挙動を制御したい場合などは、
事前に定義されているreasoning_engines.LangchainAgentでは不足です。
Reasoning EngineではアプリケーションのテンプレートがPythonのクラスとして定義されていますが、
これをカスタムすることで、より複雑なものを構築できます。
今回はLangGraphのQuick Startから、
Part4のHuman-in-the-loopまでを実装したエージェントをReasoning Engineで使えるようにします。
※TavilyのAPIキー取得を事前にお願いします。
エージェントの概要
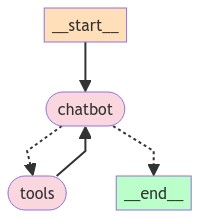
-
検索ツール(Tavily)のみ持っている。検索が不要な場合はLLMが直接応答する
-
検索が必要な場合はTavilyを使用する
- 検索の実行前に、検索クエリの表示とともに実行可否の判断をユーザーに求める
-
マルチターンの会話が可能
- セッション単位で有効なメモリ機能あり
準備
- ライブラリのインストール
langchain-anthropicをインストールした方はアンインストールしてください(パッケージのコンフリクト解消が大変でした)。
poetry remove langchain-anthropic
poetry add "langchain-community=0.2.16" "langgraph=0.2.21"- コードの準備
import json
import os
import sys
from typing import Annotated, TypedDict
from uuid import uuid4
import vertexai
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_google_vertexai import ChatVertexAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
from vertexai.preview import reasoning_engines
class State(TypedDict):
messages: Annotated[list, add_messages]
class LangGraphApp:
def __init__(self, project: str, location: str) -> None:
self.project = project
self.location = location
def set_up(self) -> None:
graph_builder = StateGraph(State)
model = ChatVertexAI(model="gemini-1.5-pro")
os.environ["TAVILY_API_KEY"]
tool = TavilySearchResults(max_results=2)
tools = [tool]
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
model_with_tools = model.bind_tools(tools)
def chatbot(state: State):
return {"messages": [model_with_tools.invoke(state["messages"])]}
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
{"tools": "tools", "__end__": "__end__"},
)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge(START, "chatbot")
memory = MemorySaver()
self.runnable = graph_builder.compile(
checkpointer=memory, interrupt_before=["tools"]
)
def query(self, message: str, config: dict):
"""Query the application.
Args:
message: The user message.
config: The configuration.
Returns:
str: The LLM response.
"""
if message.lower() in ["quit", "exit", "q"]:
print("Agent: さようなら!")
sys.exit()
elif message == "" and self.runnable.get_state(config).next == ("tools",):
events = self.runnable.invoke(None, config, stream_mode="values")
for event in events:
if "messages" in event:
return events["messages"][-1].content
elif message == "":
return "メッセージを入力してください"
events = self.runnable.invoke(
{"messages": [("user", message)]}, config, stream_mode="values"
)
try:
events["messages"][-1].additional_kwargs["function_call"][
"name"
] == "tavily_search_results_json"
text = events["messages"][-1].additional_kwargs["function_call"][
"arguments"
]
data = json.loads(text)
query = data["query"]
return f"Tavilyで、「{query}」と検索します。問題なければそのままエンターを押してください"
except KeyError:
pass
return events["messages"][-1].content
def main():
PROJECT = os.environ.get("PROJECT")
LOCATION = os.environ.get("LOCATION")
STAGING_BUCKET = os.environ.get("STAGING_BUCKET")
vertexai.init(
project=PROJECT,
location=LOCATION,
staging_bucket=STAGING_BUCKET,
)
# ローカルでの検証用
agent = LangGraphApp(project=PROJECT, location=LOCATION)
agent.set_up()
thread_id = ""
if thread_id == "":
thread_id = uuid4()
config = {"configurable": {"thread_id": thread_id}}
while True:
message = input("User: ")
response = agent.query(message, config)
print(f"Agent: {response}")
if __name__ == "__main__":
main()ローカルでの実行
実行すると、以下のようにCLIで対話できます。
User: こんにちは!私はShintaroと申します。
Agent: こんにちは、Shintaroさん!😊
User: 麻布台ヒルズの開業日について教えてくれませんか?
Agent: Tavilyで「麻布台ヒルズの開業日」と検索します。問題なければそのままエンターを押してください
User:
Agent: 麻布台ヒルズの開業日は2023年11月24日です。
User: 合ってます!ちなみに、私の名前を覚えていますか?
Agent: はい、もちろんです!Shintaroさんですね😊
User: q
Agent: さようなら!このエージェントをデプロイします。
デプロイ
コードを以下のように変更し、実行します。
# 変更のない箇所は割愛
def main():
PROJECT = os.environ.get("PROJECT")
LOCATION = os.environ.get("LOCATION")
STAGING_BUCKET = os.environ.get("STAGING_BUCKET")
vertexai.init(
project=PROJECT,
location=LOCATION,
staging_bucket=STAGING_BUCKET,
)
# デプロイ
remote_app = reasoning_engines.ReasoningEngine.create(
LangGraphApp(project=PROJECT, location=LOCATION),
requirements=[
"google-cloud-aiplatform[reasoningengine,langchain]==1.66.0",
"langgraph==0.2.21",
"langchain-community==0.2.16",
"python-dotenv==1.0.1",
],
display_name="LangGraph agent", # Optional
description="A sample LangGraph agent", # Optional
extra_packages=[], # Optional
)
print(f"{remote_app.resource_name=}")
if __name__ == "__main__":
main()出力されたremote_app.resource_nameを使ってエージェントを動かします。
デプロイしたエージェントを動かす
from vertexai.preview import reasoning_engines
def main():
# デプロイしたアプリへのクエリ
remote_app = reasoning_engines.ReasoningEngine("projects/PROJECT_ID/locations/us-central1/reasoningEngines/REASONING_ENGINE_ID")
thread_id = ""
if thread_id == "":
thread_id = str(uuid4())
config = {"configurable": {"thread_id": thread_id}}
while True:
message = input("User: ")
response = remote_app.query(message=message, config=config)
print(f"Agent: {response}")
if __name__ == "__main__":
main()特にデプロイすると、Human-in-the-loopの部分の挙動が不安定になる気がします。
具体的には、以下のようになってしまうことが度々あります。
User: 麻布台ヒルズの開業日について教えてくれませんか?
Agent: Tavilyで「麻布台ヒルズの開業日」と検索します。問題なければそのままエンターを押してください
User:
Agent: メッセージを入力してくださいLangGraphもしくはReasoning Engineの理解不足か、LLMゆえの不安定さか、
今後の課題として調査してみます。
環境のクリーンアップ
以下でReasoning Engineのインスタンスの一覧を取得できます。
reasoning_engines.ReasoningEngine.list()以下でReasoning Engineのインスタンスを削除できます。
remote_app = reasoning_engines.ReasoningEngine("projects/PROJECT_ID/locations/us-central1/reasoningEngines/REASONING_ENGINE_ID")
remote_app.delete()詳細はこちらをご覧ください。
参照リンク
2024/9時点でプレビューの機能ですので、各種ドキュメントで最新情報をご確認ください。
- 公式ドキュメント
- 日本語の方は更新が追い付いていないので英語版をおすすめします。
- 公式ドキュメント - トラブルシューティング
- APIリファレンス
- サンプルが色々載っているリポジトリ
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。