Google CloudとRAG | LlamaIndex on Vertex AI編
Google CloudとRAGについて勝手にシリーズ化して書いていく記事の第三弾です。
Table of contents
author: Shintaro
はじめに
Google I/O 2024のタイミングで発表されたLlamaIndex on Vertex AIについて解説します。
最初にお断りですが、以下の個人的な考えから、この記事ではLlamaIndex自体の説明はしません。
- LlamaIndex on Vertex AIをさわるうえで、知らなくても問題ない
- LlamaIndexを知らない人はそもそもLlamaIndex on Vertex AIには興味を持たない
LlamaIndex on Vertex AIとは?
端的に表現すると、RAGにおけるRetrievalの部分を担当してくれるツールです。
以下画像の通り、Google CloudでRAGを実装する際の選択肢が増えてきています。
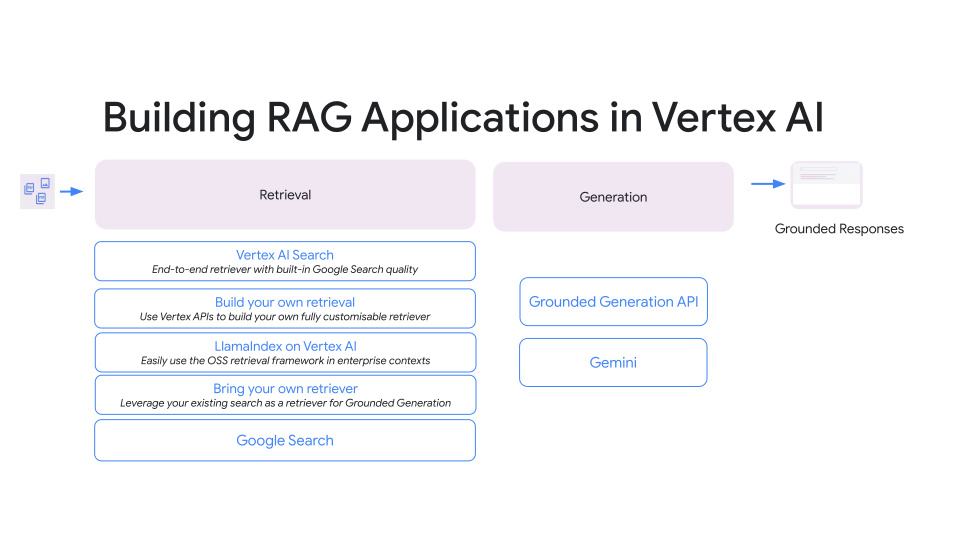
以下、ざっくりとした特徴です。
- チャンク作成、エンベディング生成、インデックスの作成、保存のステージを良い感じにやってくれる。
- 対応しているファイル形式はHTMLやMarkdown、GoogleドキュメントやGoogleスライド、パワポなど。
- 対応しているデータソースはCloud Storage、Googleドライブ、単一ファイルのアップロード
- Vertex AIのGeminiやembeddingモデルの多くが使用可能
公式ドキュメントには料金が書いておらず、また今回は小さいデータで検証していたため、
LlamaIndex on Vertex AIに特有の課金が存在するか、正直わかりませんでした。
Vertex AI Vector Searchの料金から類推すると、
corpus(インデックス)の作成時には課金されている可能性があります。
一方、corpusを作成して放置しても、インデックスがデプロイされている扱いにはなっていないようでした。
※これはLlamaIndex on Vertex AI特有の課金のお話で、モデルの利用やCloud Storageには課金されます。
以下、各種ドキュメントです。
他のRetrieverとの比較
LlamaIndex on Vertex AIと以下2つを、独断と偏見で比較してみます。
- LlamaIndex
- Vertex AI Search
3つの観点から見ていきます。
- RetrieveやIndexなど、RAGの各ステージにおけるカスタマイズ性
- 使用できるモデル
- 対応しているデータソース
検索や生成の精度の比較は大変なので今回はやりません。
LlamaIndexとの比較
-
RetrieveやIndexなど、RAGの各ステージにおけるカスタマイズ性
-
LlamaIndexの方がもちろん高い
-
2024/7/16時点で、LlamaIndex on Vertex AIはチャンクサイズと、前後のチャンクのオーバーラップくらいしかカスタマイズできない
- カスタマイズができない分、構築はかなりラク
-
-
使用できるモデル
- LlamaIndexはOpenAIやAnthropic提供のもの含め、様々なモデルを使える
- LlamaIndex on Vertex AIは、Vertex AIのモデルに限定される
-
対応しているデータソース
- LlamaIndexはLlamaHubから様々なデータソースとのコネクタを使用できる
- LlamaIndex on Vertex AIはCloud Storage、Googleドライブ、単一ファイルのアップロードに限定される
Vertex AI Searchとの比較
-
RetrieveやIndexなど、RAGの各ステージにおけるカスタマイズ性
- 直近ではエンベディングのアップロードができるようになるなど、Vertex AI Searchの方がカスタマイズは高い
-
使用できるモデル
- LlamaIndex on Vertex AIはembeddingモデルもコントロールできる
-
対応しているデータソース
- Vertex AI Searchの方が様々なデータソースに対応している
触ってみた
以下2つの使い方をそれぞれ紹介していきます。
- Retriever単体
- Geminiのretrieval tool
共通で必要な準備からしていきます。
準備
- Cloud Storageのバケットを作成し、ファイルを格納
- AI事業者ガイドラインを、表紙含めて冒頭4ページだけ使います。
- ライブラリをインストール
pip install --upgrade google-cloud-aiplatformRetriever単体
チャンクされたドキュメントをとってくるためのものです。回答は生成しません。
先に解説しますと、corpusはインデックスのこと指します。
corporaはcorpusの複数形なので、複数のインデックスのことです。
import vertexai
from vertexai.preview import rag
from vertexai.preview.generative_models import GenerativeModel, Tool
project_id = "YOUR_PROJECT_ID"
display_name = "sample_corpus" # 任意の名前
paths = [
# "https://drive.google.com/file/d/123",
"gs://your_bucket/",
] # Cloud StorageもしくはGoogle Driveのリンクのみ対応
def main():
# Vertex AI APIの初期化
vertexai.init(project=project_id, location="us-central1")
# embeddingモデルの設定
embedding_model_config = rag.EmbeddingModelConfig(
publisher_model="publishers/google/models/textembedding-gecko-multilingual@001"
)
# corpus(インデックス)の作成
rag_corpus = rag.create_corpus(
display_name=display_name,
embedding_model_config=embedding_model_config,
)
# corpusへのファイルインポート(チャンク化、エンベディング、保存)
response = rag.import_files(
rag_corpus.name,
paths,
chunk_size=512, # Optional
chunk_overlap=100, # Optional
max_embedding_requests_per_min=900, # Optional
)
query = "Society5.0とはなんですか?"
# コンテキストの検索
response = rag.retrieval_query(
rag_resources=[
rag.RagResource(
rag_corpus=rag_corpus.name,
],
text=query,
similarity_top_k=2, # Optional
vector_distance_threshold=0.5, # Optional
)
print(response)以下のように出力されます。
similarity_top_kを2に指定したので、取ってきてくれるチャンクは2つです。
contexts {
contexts {
source_uri: "gs://llamaindex-test/AI事業者ガイドライン(テスト用スモール版).pdf"
text: "また近年台頭してきた対話型の生成 AI によ\r\nって「AI の民主化」が起こり、多くの人が「対話」 によって AI を様々な用途へ容易に活用できるようになった。これ\r\nにより、企業では、ビジネスプロセスに AI を組み込むだけではなく、AI が創出する価値を踏まえてビジネスモデル\r\n自体を再構築することにも取り組ん でいる。また、個人においても自らの知識を AI に反映させ、自身の生産性を\r\n拡大させる取組が加速している 。我が国では、従来から Society 5.0 として、サイバー空間とフィジカル空間を高\r\n度に融合させたシステム(CPS : サイバー・フィジカルシステム)による経済発展と社会的課題の解決を両立す\r\nる人間中心の社会という コンセプトを掲げてきた。このコンセプトを実現するにあたり、AI が社会に受け入れられ適\r\n正に利用されるため、2019 年 3 月に「人間中心の AI 社会原則」が策定された。一方で、AI 技術の利用範囲\r\n及び利用者の拡大に伴い、リスクも増大している。"
distance: 0.22105848934715033
}
contexts {
source_uri: "gs://llamaindex-test/AI事業者ガイドライン(テスト用スモール版).pdf"
text: "このような認識のもと、これまでに総務省主導で「国際的な議論のための AI 開発ガイドライン案」、「AI 利活\r\n用ガイドライン~AI 利活用のためのプラクティカルリファレンス~」及び経済産業省主導で「AI 原則実践のための\r\nガバナンス・ガイドライン Ver. 1.1」を策定・公表してきた。そして、このたび 3 つのガイ ドラインを統合・見直しし\r\nて、この数年でさらに発展した AI 技術の特徴及び国内外における AI の社会実装 に係る議論を反映し、事業\r\n者が AI の社会実装及びガバナンスを共に実践するためのガイドライン(非拘束的 なソフトロー)として新たに策3\r\n定した(「図 1."
distance: 0.30341481972702355
}
}以下のコードで作成済みのcorpusの名前などが取得できます。
project_id = "YOUR_PROJECT_ID"
def main():
vertexai.init(project=project_id, location="us-central1")
corpora = rag.list_corpora()
print(corpora)以下が出力結果の例です。
ListRagCorporaPager<rag_corpora {
name: "projects/{project_id}/locations/us-central1/ragCorpora/1234567891011121314"
display_name: "test_corpus"
rag_embedding_model_config {
vertex_prediction_endpoint {
endpoint: "projects/{project_id}/locations/us-central1/publishers/google/models/textembedding-gecko-multilingual@001"
}
}
create_time {
seconds: 1720859931
nanos: 913186000
}
update_time {
seconds: 1720859931
nanos: 913186000
}
}nameの以下が呼び出す際に必要なcorpus_nameです。
"projects/{project_id}/locations/us-central1/ragCorpora/1234567891011121314"Geminiのretrieval tool
GeminiにToolとして持たせ、Groundingされた回答を生成させます。
import vertexai
from vertexai.preview import rag
from vertexai.preview.generative_models import GenerativeModel, Tool
project_id = "YOUR_PROJECT_ID"
display_name = "sample_corpus" # 任意の名前
corpus_name = f"projects/{project_id}/locations/us-central1/ragCorpora/1234567891011121314"
paths = [
"gs://your_bucket/",
]
def main():
rag_retrieval_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_resources=[
rag.RagResource(
rag_corpus=corpus_name, # 現在は1つのcorpusのみ指定可能
)
],
similarity_top_k=2, # Optional
vector_distance_threshold=0.5, # Optional
),
)
)
rag_model = GenerativeModel(
model_name="gemini-1.5-flash-001", tools=[rag_retrieval_tool]
)
response = rag_model.generate_content(query)
print(response.text)出力は以下の通りです。
Society5.0は、サイバー空間とフィジカル空間を高度に融合させたシステム(CPS)による経済発展と社会的課題の解決を両立する人間中心の社会というコンセプトです。corpusの削除
作成したcorpusを削除します。
project_id = "YOUR_PROJECT_ID"
corpus_name = (
f"projects/{project_id}/locations/us-central1/ragCorpora/1234567891011121314"
)
def main():
vertexai.init(project=project_id, location="us-central1")
rag.delete_corpus(name=corpus_name)
corpora = rag.list_corpora()
print(corpora)
# 空のListRagCorporaPagerが出力されば、すべて削除されている
# ListRagCorporaPager<>
まとめ
LlamaIndex on Vertex AIを使うと、
Cloud StorageやGoogleドライブにあるデータでお手軽にRAGができることがわかりました。
精度の検証が必要ですが、
簡単に構築できるので検証でサクッとRAGを試したい場合などには使えるそうだと感じました。
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。