Google CloudとRAG | ~Vertex AIの便利なAPIたち~編
Google CloudとRAGについて勝手にシリーズ化して書いていく記事の第二弾です。
Table of contents
author: Shintaro
はじめに
前回の記事でも軽く紹介しましたが、
Google CloudではDIYでRAGをやる際に、各ステージで使えるAPIが公開されています。
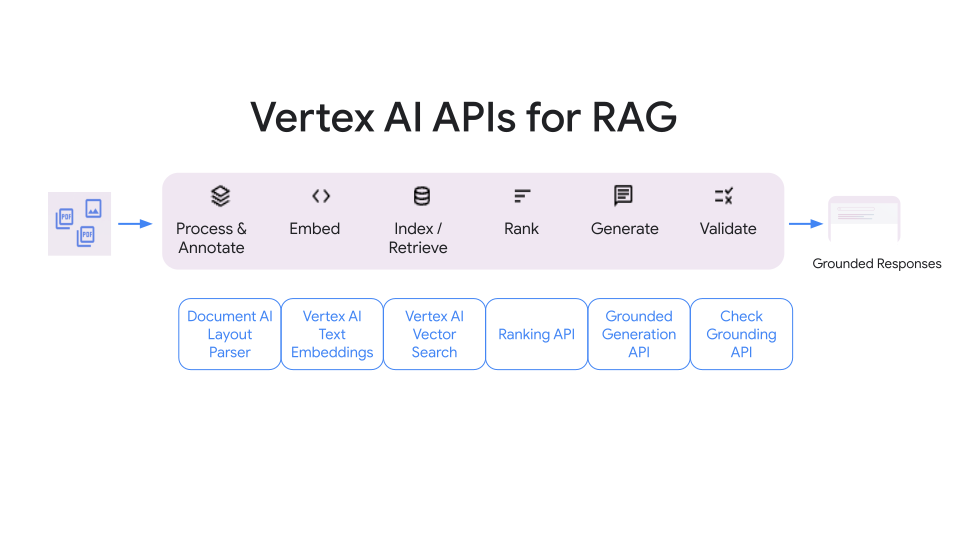
今回は、前回の記事では紹介しなかった以下のAPIを紹介していきます。
- The Document AI Layout Parser
- The ranking API
- The grounded generation API
- The check grounding API
The Document AI Layout Parser
The Document AI Layout ParserはPDFやパワーポイントなどのファイルをパース、チャンク化してくれます。
以下、特徴や注意点です。
- HTML、PDF、DOCX、PPTXに対応
- PPTXは2024/7/〇時点でプレビュー
- パラグラフ、表、リスト、タイトル、ヘッダー、フッターなどを識別可能
- 2タイプの処理方法
- Online processing
- どのファイルタイプでも、インプットは20MBまで
- PDFは15ページまで
- Batch processing
- PDFは40MBまで、500ページまで
- Online processing
- PDF内の埋め込み画像のテキストも識別
触ってみる
事前に、以下の準備が必要です。
- Document AIのプロセッサ作成
- プロセッサのタイプは「Layout Parser」である必要あり
- Cloud Storageのバケット作成
- そこにパースしたいPDFを入れておく
Document AIのプロセッサ作成の部分だけ紹介します。簡単です。
Document AIのプロセッサ作成
- Google Cloudのコンソール画面で、Document AIを検索。
- プロセッサギャラリーを開き、「Layout Parser」の「プロセッサを作成します」をクリック。
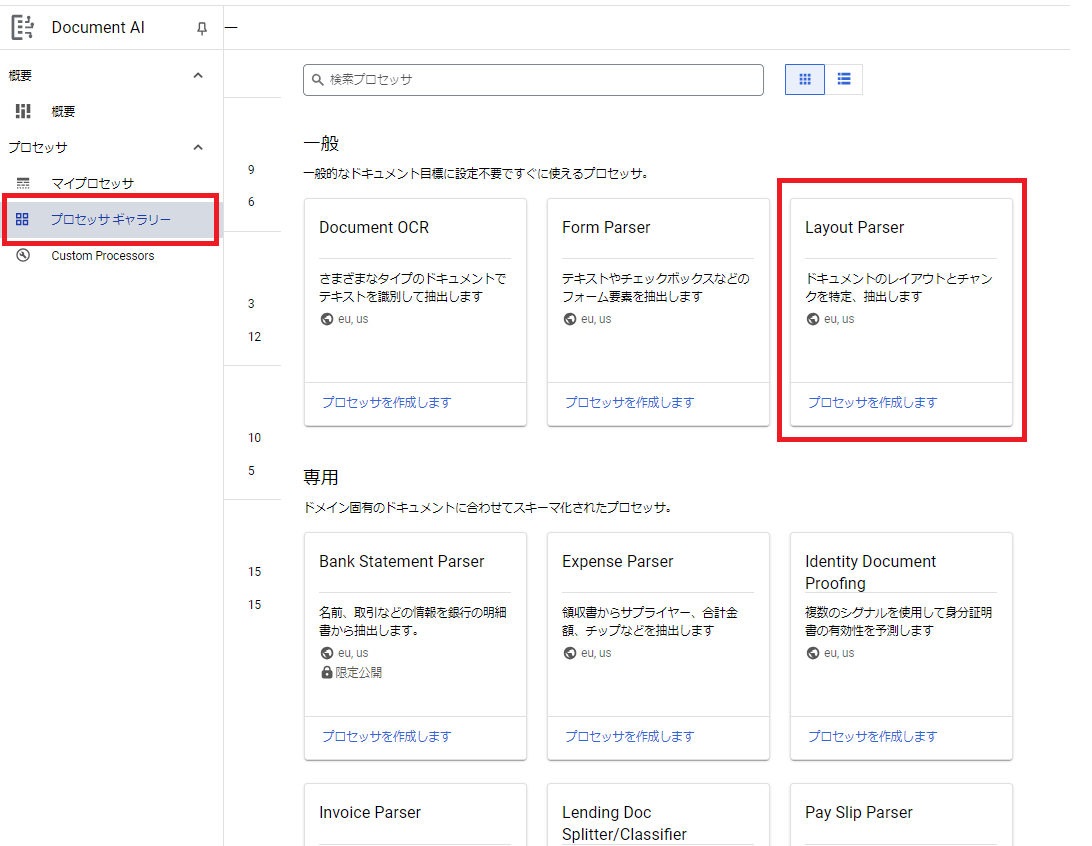
- 任意のプロセッサ名を入力。リージョンと暗号化はデフォルトのままにしておく。
- 作成をクリック。これで完了です。
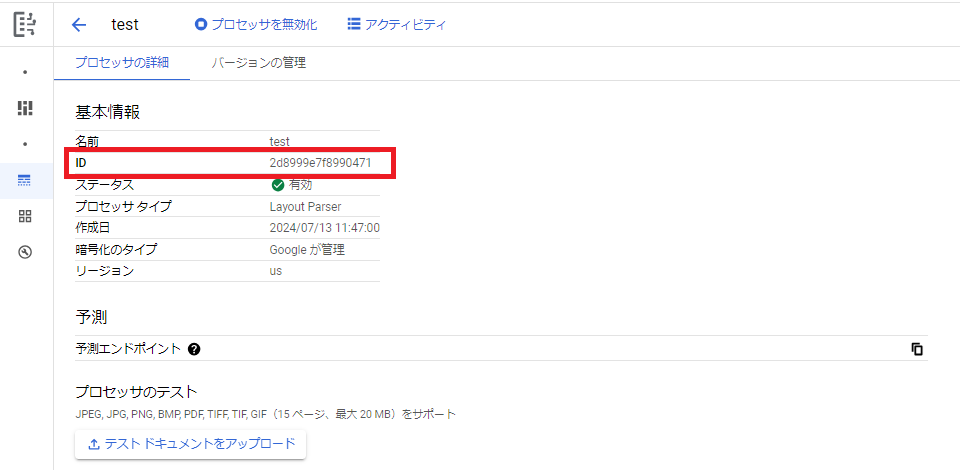
以降、Batch processingでPDFを処理しますが、
その際にプロセッサのIDを使用します。
サンプルコードと出力結果
ライブラリをインストールしておきます。
pip install --upgrade google-cloud-documentai google-cloud-storage以下はBatch processingのサンプルコードです。
import re
from typing import Optional
from google.api_core.client_options import ClientOptions
from google.api_core.exceptions import InternalServerError, RetryError
from google.cloud import documentai
from google.cloud import storage
def batch_process_documents(
project_id: str,
location: str,
processor_id: str,
gcs_output_uri: str,
processor_version_id: Optional[str] = None,
gcs_input_uri: Optional[str] = None,
input_mime_type: Optional[str] = None,
gcs_input_prefix: Optional[str] = None,
field_mask: Optional[str] = None,
timeout: int = 400,
) -> None:
# "us"以外のロケーションを使用する場合、`api_endpoint`の指定が必須
opts = ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com")
client = documentai.DocumentProcessorServiceClient(client_options=opts)
if gcs_input_uri:
# Cloud Storageの特定のURIを指定
gcs_document = documentai.GcsDocument(
gcs_uri=gcs_input_uri, mime_type=input_mime_type
)
# URI配下にあるドキュメントのリストを取得
gcs_documents = documentai.GcsDocuments(documents=[gcs_document])
input_config = documentai.BatchDocumentsInputConfig(gcs_documents=gcs_documents)
else:
# gcs_input_prefixでURIを指定した場合は、ディレクトリが対象になる
gcs_prefix = documentai.GcsPrefix(gcs_uri_prefix=gcs_input_prefix)
input_config = documentai.BatchDocumentsInputConfig(gcs_prefix=gcs_prefix)
# 出力先のURIを指定
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=gcs_output_uri, field_mask=field_mask
)
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
if processor_version_id:
# 以下はプロセッサバージョンの完全なリソース名のサンプル
# projects/{project_id}/locations/{location}/processors/{processor_id}/processorVersions/{processor_version_id}
name = client.processor_version_path(
project_id, location, processor_id, processor_version_id
)
else:
# 以下はプロセッサ名の完全なリソース名のサンプル
# projects/{project_id}/locations/{location}/processors/{processor_id}
name = client.processor_path(project_id, location, processor_id)
process_options = documentai.ProcessOptions(
layout_config=documentai.ProcessOptions.LayoutConfig(
chunking_config=documentai.ProcessOptions.LayoutConfig.ChunkingConfig(
chunk_size=40,
include_ancestor_headings=False,
)
)
)
request = documentai.BatchProcessRequest(
name=name,
input_documents=input_config,
document_output_config=output_config,
process_options=process_options,
)
# Batch processingはLong Running Operation (LRO)を返す
operation = client.batch_process_documents(request)
# 形式: projects/{project_id}/locations/{location}/operations/{operation_id}
try:
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result(timeout=timeout)
# タイムアウトの処理
except (RetryError, InternalServerError) as e:
print(e.message)
# 処理が完了したあと、
# 出力されるドキュメントの情報はoperation metadataから取得
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
storage_client = storage.Client()
print("Output files:")
# One process per Input Document
for process in list(metadata.individual_process_statuses):
# output_gcs_destinationの形式: gs://BUCKET/PREFIX/OPERATION_NUMBER/INPUT_FILE_NUMBER/
# Cloud Storage APIではバケット名とURI prefixが別々に求められる
matches = re.match(r"gs://(.*?)/(.*)", process.output_gcs_destination)
if not matches:
print(
"Could not parse output GCS destination:",
process.output_gcs_destination,
)
continue
output_bucket, output_prefix = matches.groups()
# 出力先のバケットからドキュメントオブジェクトのリストを取得
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# Document AIはソースファイルごとにJSON形式で出力する
for blob in output_blobs:
# JSON形式でのCloud Storageへの出力のみ対応
if blob.content_type != "application/json":
print(
f"Skipping non-supported file: {blob.name} - Mimetype: {blob.content_type}"
)
continue
# bytesオブジェクトとしてJSONファイルをダウンロードし、Documentオブジェクトに変換
print(f"Fetching {blob.name}")
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
# Documentオブジェクトが対応している属性は以下を参照:
# https://cloud.google.com/python/docs/reference/documentai/latest/google.cloud.documentai_v1.types.Document
# Document AIが読み取ったテキストの出力
print("Document Layout Blocks")
for block in document.document_layout.blocks:
print(block)
# 指定した大きさでチャンクされたテキストの出力
print("Document Chunks")
for chunk in document.chunked_document.chunks:
print(chunk.content) # これをベクトル化すれば良い
def main():
project_id = "YOUR_PROJECT_ID"
location = "us" # "us" or "eu"のみ対応
processor_id = "YOUR_PROCESSOR_ID" # 事前にプロセッサを作成しておく必要あり
input_mime_type = "application/pdf" # 参照: https://cloud.google.com/document-ai/docs/file-types for supported file types
gcs_input_prefix = (
"YOUR_GCS_INPUT_PREFIX" # 形式: gs://bucket/director
)
gcs_output_uri = "YOUR_GCS_INPUT_PREFIX" # `/`で終える必要あり。 形式: gs://bucket/directory/subdirectory/
batch_process_documents(
project_id=project_id,
location=location,
processor_id=processor_id,
gcs_output_uri=gcs_output_uri,
input_mime_type=input_mime_type,
gcs_input_prefix=gcs_input_prefix,
)
if __name__ == "__main__":
main()出力結果をそれぞれ紹介していきます。
なお、読み込ませたファイルは経済産業省のAI事業者ガイドラインです。
# print("Document Layout Blocks")
# for block in document.document_layout.blocks:
# print(block)
# ↑の部分の出力結果
text_block {
text: "AI 事業者ガイドライン"
type_: "paragraph"
}
block_id: "1"
page_span {
page_start: 1
page_end: 1
}
text_block {
text: "(第1.0版)"
type_: "paragraph"
}
block_id: "2"
page_span {
page_start: 1
page_end: 1
}
text_block {
text: "令和6年4月19日"
type_: "paragraph"
}
block_id: "3"
page_span {
page_start: 1
page_end: 1
}
text_block {
text: "総務省"
type_: "paragraph"
}
block_id: "4"
page_span {
page_start: 1
page_end: 1
}
text_block {
text: "経済産業省"
type_: "paragraph"
}
block_id: "5"
page_span {
page_start: 1
page_end: 1
}
text_block {
text: "目次"
type_: "heading-1"
blocks {
table_block {
body_rows {
cells {
blocks {
text_block {
text: "はじめに.."
type_: "paragraph"
}
block_id: "8"
page_span {
page_start: 2
page_end: 2
}
}
row_span: 1
col_span: 1
}
cells {
blocks {
text_block {
text: "2"
type_: "paragraph"
}
block_id: "9"
page_span {
page_start: 2
page_end: 2
}
}
row_span: 1
col_span: 1
}
}
...ヘッダーである「目次」を認識してくれています。
次に、chunkの出力結果です。
# print("Document Chunks")
# for chunk in document.chunked_document.chunks:
# print(chunk.content)
# ↑の部分の出力結果
chunk_id: "c1"
content: "AI 事業者ガイドライン(第1.0版)令和6年4月19日総務省経済産業省"
page_span {
page_start: 1
page_end: 1
}
chunk_id: "c2"
content: "# 目次"
page_span {
page_start: 2
page_end: 3
}
chunk_id: "c3"
content: "\n| はじめに.. | 2 |\n|-|-|\n| 第1部 AIとは | ...8 |\n| 第2部 AIにより目指すべき社会及び各主体が取り組む事項 | 10 |\n| A. 基本理念 | 10 |\n| B. 原則... | 11 |\n| C. 共通の指針 | 12 |\n| D. 高度な AI システムに関係する事業者に共通の指針 | 22 |\n| E. AI ガバナンスの構築... | |\n\n"
page_span {
page_start: 2
page_end: 2
}
chunk_id: "c4"
content: "24\n\n| はじめに.. | 2 |\n|-|-|\n| 第3部 AI開発者に関する事項.. | 26 |\n| 第4部 AI 提供者に関する事項.. | 31 |\n| 第5部 AI利用者に関する事項.... | 34 |\n1\n"
page_span {
page_start: 2
page_end: 2
}
chunk_id: "c5"
content: "# はじめに\n\nAI 関連技術は日々発展をみせ、AIの利用機会...(中略)我が国は2016年4月のG7 香川・高松情報通信大臣会合における AI 開発原則に向けた提案を先駆け とし、G7・G20、OECD 等の国際機関での議論をリードし、多くの貢献をしてきた。一方、AIに関する原則の具 体的な実践を進めていくにあたっては、"
page_span {
page_start: 3
page_end: 4
}
chunk_id: "c6"
content: "• 少子高齢化に伴う労働力の低下等の社会課題の解決手段として、AIの活用が期待されていること ・ 法律の整備・施行が...(中略)√利活用にて留意することが期待される「AI利活用原則」 とその解説を取りまとめAI原則実践のためのガバナンス・ガイドライン√AIの社会実装の促進に必要なAI原則の実践を支援 すべく、AI事業者が実施すべき行動目標、仮想的な ・実践例等を提示...土台"
page_span {
page_start: 3
page_end: 4
}
chunk_id: "c7"
content: "新規策定統合・見直し考慮諸外国の動向 新技術の台頭AI事業者 ガイドライン図1. 本ガイドラインの位置づけAI の利用は、その分野とその利用形態によっては、社会に対して大きなリスクを生じさせ、そのリスクに伴う社 会的な軋轢により、...(中略)検討体制は、今後の状況に合わせ て適宜見直しを行う。・AI ネットワーク社会推進会議 https://www.soumu.go.jp/main_sosiki/kenkyu/ai_network/index.html・AI 事業者ガイドライン検討会 https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/index.html3"
page_span {
page_start: 4
page_end: 4
}4ページにわたる内容が7つのチャンクに分割されました。
チャンクサイズは以下の箇所でコントロールできます。
process_options = documentai.ProcessOptions(
layout_config=documentai.ProcessOptions.LayoutConfig(
chunking_config=documentai.ProcessOptions.LayoutConfig.ChunkingConfig(
chunk_size=50,
include_ancestor_headings=False, # チャンク化されたそれぞれのテキストにヘッダーを含ませるか否か
)
)
)chunk_sizeで指定する数字は文字数ではありませんが、
それがどういったルールなのか明言されておらず、わかりませんでした。
chunk_sizeを50にすると今回使用した日本語のドキュメントで1,000文字程度が出力されました。
RAGにおいては、このチャンク化したテキストをエンベディングしていきます。
おまけとして、表がある以下のようなページも読ませてみました。
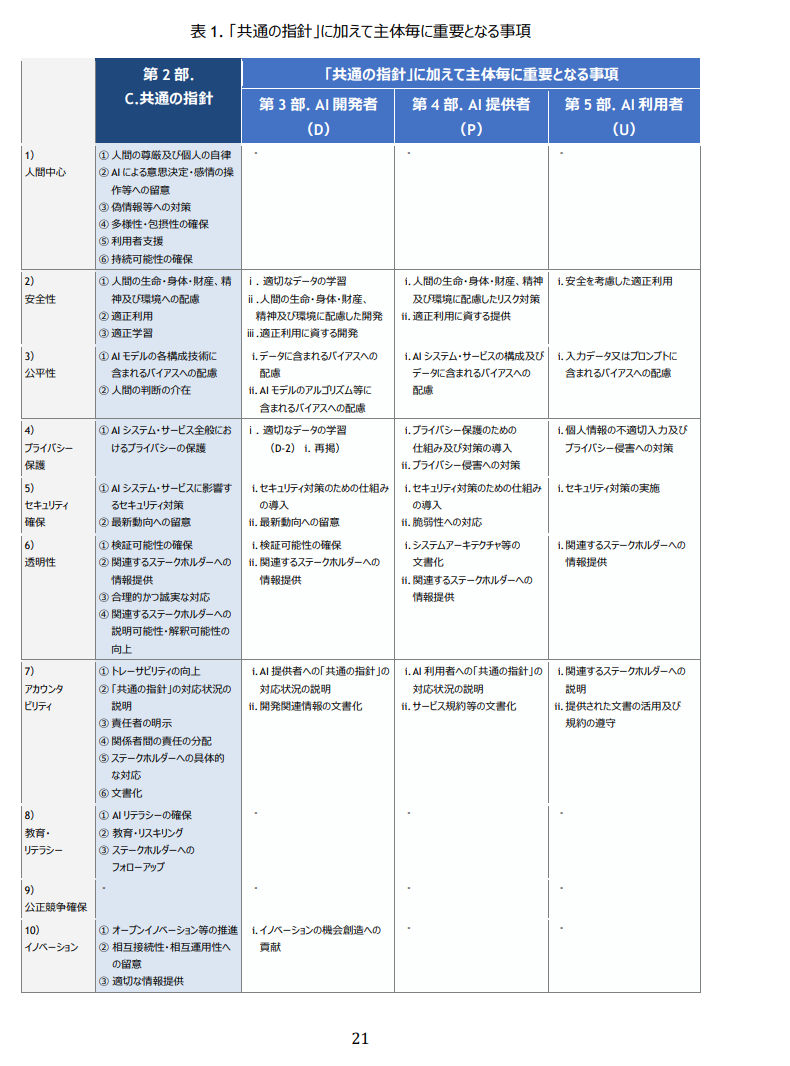
以下、chunkの出力結果です。
表 1. 「共通の指針」に加えて主体毎に重要となる事項、・ⅰ
| | 第2部. | 「共通の指針 | 」に加えて主体毎に重要 | となる事項 |
|-|-|-|-|-|
| | C.共通の指針 | 第3部. AI 開発者 | 第4部. AI 提供者 | 第5部. AI 利用者 |
| | | (D) | (P) | (U) |
| | 第2部. | 「共通の指針 | 」に加えて主体毎に重要 | となる事項 |
|-|-|-|-|-|
| 1) | ① 人間の尊厳及び個人の自律 | | | |
| 人間中心 | ② AI による意思決定・感情の操 作等への留意 ③ 偽情報等への対策 ④多様性・包摂性の確保 ⑤ 利用者支援 ⑥ 持続可能性の確保 | | | |
| | 第2部. | 「共通の指針 | 」に加えて主体毎に重要 | となる事項 |
|-|-|-|-|-|
| 2) 安全性 3) 公平性 | ① 人間の生命・身体・財産、精 神及び環境への配慮 ②適正利用 ③適正学習 ① AI モデルの各構成技術に 含まれるバイアスへの配慮 ② 人間の判断の介在 | |
i.適切なデータの学習 ii. 人間の生命・身体・財産 精神及び環境に配慮した開発 iii. 適正利用に資する開発 i. データに含まれるバイアスへの 配慮 ii. AI モデルのアルゴリズム等に 含まれ るバイアスへの配慮| i. 人間の生命・身体・財産、精神 及び環境に配慮したリスク対策 ii. 適正利用に資する提供 i. Al システム・サービスの構成及び データに含まれるバイアスへの 配慮 | i. 安全を考慮した適正利用 i. 入力データ又はプロンプトに 含まれるバイアスへの配慮 | 4) プライバシー | ① AI システム・サービス全般にお けるプライバシーの保護 | |かなり不完全ですが、表形式っぽくしようと頑張ってくれた痕跡があります。
もう少しシンプルな構造の表であれば、うまくいくケースもある可能性があります。
The ranking API
一般的なRAGでは、ドキュメント(チャンク / コンテキスト)をベクトル検索で取得しますが、
The ranking APIは、その取得してきたドキュメントを並び替えるために使います。
触ってみる
まず、ライブラリをインストールしておきます。
pip install google-cloud-discoveryengineサンプルコードと出力結果
from google.cloud import discoveryengine_v1alpha as discoveryengine
project_id = "YOUR_PROJECT_ID"
def main():
client = discoveryengine.RankServiceClient()
# The full resource name of the ranking config.
# Format: projects/{project_id}/locations/{location}/rankingConfigs/default_ranking_config
ranking_config = client.ranking_config_path(
project=project_id,
location="global",
ranking_config="default_ranking_config",
)
request = discoveryengine.RankRequest(
ranking_config=ranking_config,
model="semantic-ranker-512@latest",
top_n=10,
query="What is Google Gemini?",
records=[
discoveryengine.RankingRecord(
id="1",
title="Gemini",
content="The Gemini zodiac symbol often depicts two figures standing side-by-side.",
),
discoveryengine.RankingRecord(
id="2",
title="Gemini",
content="Gemini is a cutting edge large language model created by Google.",
),
discoveryengine.RankingRecord(
id="3",
title="Gemini Constellation",
content="Gemini is a constellation that can be seen in the night sky.",
),
],
)
response = client.rank(request=request)
# Handle the response
print(response)
if __name__ == "__main__":
main()以下、簡単な解説です。
- クエリとドキュメントのセットを渡して、ドキュメントを並び替えている。
- インプットの要素として、idとtitle、contentが必要。
- titleかcontentのどちらかは無くても良いが、それもスコアに影響を与える。
print(response)の結果は以下の通りです。
records {
id: "2"
title: "Gemini"
content: "Gemini is a cutting edge large language model created by Google."
score: 0.73
}
records {
id: "3"
title: "Gemini Constellation"
content: "Gemini is a constellation that can be seen in the night sky."
score: 0.25
}
records {
id: "1"
title: "Gemini"
content: "The Gemini zodiac symbol often depicts two figures standing side-by-side."
score: 0.21
}What is Google Gemini?という質問に対し、
Gemini is a cutting edge large language model created by Google.
が最も類似度が高いという結果になりました。
リランキングを入れると必ず精度が良くなるわけではなく、
データセットや使用するリランカーによってはむしろ性能が低下することもあるようなので、
導入の可否については検証する必要があります。
The grounded generation API
The grounded generation APIは、
Vertex AI SearchのデータストアやGoogle検索、任意のテキストとGeminiをGroundingさせられます。
PaLM2やGeminiではGroundingが実装済みでしたが、
それがVertex AI Agent Builderの方にも実装されたイメージでしょうか。
ドキュメントが更新されてないだけの可能性もありますが、Geminiの方の対応モデルがGemini 1.0 Proのみなのに対し、
こちらはGemini 1.5 ProやFlashにも対応しています。
2024/7/12時点でPreview with allowlistのため、まださわれません。 検証でき次第、随時追記していきます。
The check grounding API
The check grounding APIは、LLMからの回答とコンテキストを比較して、
コンテキストに則った回答がされているかチェックします。
RAGASのContext Precisionに近い感じの、簡単な評価用のAPIです。
触ってみる
早速ですが触ってみます。
サンプルコードと出力結果
from google.cloud import discoveryengine_v1alpha as discoveryengine
project_id = "YOUR_PROJECT_ID"
client = discoveryengine.GroundedGenerationServiceClient()
# The full resource name of the grounding config.
# Format: projects/{project_id}/locations/{location}/groundingConfigs/default_grounding_config
grounding_config = client.grounding_config_path(
project=project_id,
location="global",
grounding_config="default_grounding_config",
)
request = discoveryengine.CheckGroundingRequest(
grounding_config=grounding_config,
answer_candidate="Titanic was directed by James Cameron. It was released in 1997.",
facts=[
discoveryengine.GroundingFact(
fact_text=(
"Titanic is a 1997 American epic romantic disaster movie. It was directed, written,"
" and co-produced by James Cameron. The movie is about the 1912 sinking of the"
" RMS Titanic. It stars Kate Winslet and Leonardo DiCaprio. The movie was released"
" on December 19, 1997. It received positive critical reviews. The movie won 11 Academy"
" Awards, and was nominated for fourteen total Academy Awards."
),
attributes={"author": "Simple Wikipedia"},
),
discoveryengine.GroundingFact(
fact_text=(
'James Cameron\'s "Titanic" is an epic, action-packed romance'
"set against the ill-fated maiden voyage of the R.M.S. Titanic;"
"the pride and joy of the White Star Line and, at the time,"
"the largest moving object ever built. "
'She was the most luxurious liner of her era -- the "ship of dreams" -- '
"which ultimately carried over 1,500 people to their death in the "
"ice cold waters of the North Atlantic in the early hours of April 15, 1912."
),
attributes={"author": "Simple Wikipedia"},
),
],
grounding_spec=discoveryengine.CheckGroundingSpec(citation_threshold=0.6),
)
response = client.check_grounding(request=request)
# Handle the response
print(response)
print(response)の出力結果は以下です。
それぞれパラメータの解説も載せています。
# スコアが高いほど、コンテキスト(チャンク)によって回答が支持されていることを示す。
support_score: 1
cited_chunks {
# Retrieveされてきたコンテキスト(チャンク)。最大で1万文字(1K)
chunk_text: "Titanic is a 1997 American epic romantic disaster movie. It was directed, written, and co-produced by James Cameron. The movie is about the 1912 sinking of the RMS Titanic. It stars Kate Winslet and Leonardo DiCaprio. The movie was released on December 19, 1997. It received positive critical reviews. The movie won 11 Academy Awards, and was nominated for fourteen total Academy Awards."
# 取得もとのコンテキスト(チャンク)のインデックス。つまり、当該コンテキストがGroundingFactsとして何番目に渡されたか
source: "0"
}
cited_chunks {
chunk_text: "James Cameron\'s \"Titanic\" is an epic, action-packed romanceset against the ill-fated maiden voyage of the R.M.S. Titanic;the pride and joy of the White Star Line and, at the time,the largest moving object ever built. She was the most luxurious liner of her era -- the \"ship of dreams\" -- which ultimately carried over 1,500 people to their death in the ice cold waters of the North Atlantic in the early hours of April 15, 1912."
source: "1"
}
claims {
# clam_text(分割された回答)に対するchunk_textの開始のポジション。bytesで計算されている。
start_pos: 0
# clam_text(分割された回答)に対するchunk_textの終了のポジション。bytesで計算されている。
end_pos: 38
# 回答(の候補)が分割されたもの。”.”と他は何で分割されるか不明。
claim_text: "Titanic was directed by James Cameron."
# 回答と紐づくcited_chunksへの引用。回答がそのchunksに支持されていることを示している。
citation_indices: 0
citation_indices: 1
# 該当のclaim_textはGroundingによるチェックが必要か否か。不要だと判断された場合はfalseになり、citation_indicesは返されない
grounding_check_required: true
}
claims {
start_pos: 39
end_pos: 63
claim_text: "It was released in 1997."
citation_indices: 0
grounding_check_required: true
}おまけ LlamaIndexで使ってみる
ライブラリをインストールします。
pip install llama-index python-dotenvOpenAIのAPIキーのご準備いただき、dataフォルダの中に任意のPDFなどを入れてください。
import os
import dotenv
import openai
from google.cloud import discoveryengine_v1alpha as discoveryengine
from llama_index.core import (
SimpleDirectoryReader,
StorageContext,
VectorStoreIndex,
load_index_from_storage,
)
dotenv.load_dotenv()
project_id = "YOUR_PROJECT_ID"
openai.api_key = os.getenv("OPENAI_API_KEY")
def main():
# check if storage already exists
persist_dir = "./index_storage"
if not os.path.exists(persist_dir):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=persist_dir)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
query = "AI利用者がAIシステム・サービスを利用する際に重要なことは何ですか?日本語で回答お願いします。"
response = query_engine.query(query)
response_str = str(response)
num_nodes = len(response.source_nodes)
context = [response.source_nodes[i].text for i in range(num_nodes)]
client = discoveryengine.GroundedGenerationServiceClient()
# The full resource name of the grounding config.
# Format: projects/{project_id}/locations/{location}/groundingConfigs/default_grounding_config
grounding_config = client.grounding_config_path(
project=project_id,
location="global",
grounding_config="default_grounding_config",
)
facts = [discoveryengine.GroundingFact(fact_text=item) for item in context]
request = discoveryengine.CheckGroundingRequest(
grounding_config=grounding_config,
answer_candidate=response_str,
facts=facts,
grounding_spec=discoveryengine.CheckGroundingSpec(citation_threshold=0.1),
)
response = client.check_grounding(request=request)
# Handle the response
print(response)
if __name__ == "__main__":
main()
以下のように出力されます。
support_score: 0.991926193
cited_chunks {
chunk_text: "34 \n 第5部 AI利用者に関する事項 \n \nAI利用者は、 AI提供者から安全安心で信頼できる AIシステム・サービスの提供を受け、 AI提供者が意図し\nた範囲内で継続的に適正利用及び必要に応じて AIシステムの運用を行うことが重要である。 ...(中略) AIシステム・サービスへ個人情報を不適切に入力することがないよう注意を払う(「4 )プライバ\nシー保護」) \n AIシステム・サービスにおけるプライバシー侵害に関して適宜情報収集し、防止を検討する\n(「4)プライバシー保護」) \n \n U-5)i."
source: "0"
}
claims {
start_pos: 0
end_pos: 280
claim_text: "AI利用者がAIシステム・サービスを利用する際に重要なことは、安全を考慮した適正利用、入力データ又はプロンプトに含まれるバイアスへの配慮、個人情報の不適切入力及びプライバシー侵害への対策です。"
citation_indices: 0
grounding_check_required: true
}まとめ
Google Cloud Next ‘24のタイミングでVertex AI Agent Builderに追加された4つのAPIについて紹介しました。
SlackやSalesforceなどサードパーティーのアプリもデータストアとして設定できるようになることが予定されているなど、
Vertex AI Agent Builderはこれからもどんどん便利になっていきそうですね。
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。