Kubernetes、Istio、Helm、Prometheus、Flux、Gatekeeper、GKE。全部、さわる。
Kubernetesの基本からIstio・Helm・Prometheus・Flux・Gatekeeperなどの周辺ツール、GKEまでをハンズオン形式で概観します。
Table of contents
author: Shintaro
この記事の概要と想定読者
この記事ではKubernetesの基本的な仕組みと、それを取り巻く概念 (サービスメッシュやGitOpsなど) やツール (IstioやHelm、Prometheusなど)、そしてGKEを手を動かしながら学びます。基本的にはハンズオン形式でボトムアップに進めますが、概念的な解説との往復で手触り感を伴って理解が進むよう意識しています (完全に個人的な学習スタイルの好みです)。大枠としては以下の流れで進みます。
- Kubernetesの基本 (そもそもコンテナとは何なのかなどにも触れつつ概要レベルの解説をします)
- Kubernetesの仕組み (ローカルで動かして基本的な機能を確認します)
- サービスメッシュとIstioなど、Kubernetesに関連する用語とツールの関係性
- IstioやHelm、Prometheusなどのツール (ローカルで動かします)
- GKEをはじめとしたGoogle CloudマネージドのKubernetesと関連のサービス (動かします)
「Kubernetes入門」でググったりZennの記事を探してみても、「コントロールプレーン」や「Pod」などの用語にちょっとしたYAMLファイルが添えられた程度の解説か、ほぼハンズオンのみの記事が中心でした。具体と抽象を往復しつつ程よく手触り感が得られる、自分にとって簡単すぎず難しすぎない単独記事は見つけられませんでした。加えて、Istio / Helm / Prometheus / Flux / Gatekeeperといった周辺ツールやGKEなどのマネージドサービスまで含めて「1記事で全体を概観できる」記事も自分の探した範囲では見当たりませんでした。そこで、勉強がてら自分で書いてみました。想定読者は以下のような方 (=記事を書く前の自分です) です。
- 「コントロールプレーン」、「ノード」など、単語やアーキテクチャ図は何度か見たことはあるが、Kubernetesが結局なんなのかよくわかっていない方
- 手を動かしてKubernetesの手触り感を得たい方
- Kubernetesのみならず、関連する用語やツールまで概要レベルで理解したい方
なお、本記事のサンプル構成・コマンドは学習・検証目的であり、本番レベルではありません。本番採用にあたってはRBAC / NetworkPolicy / Secret管理 / HA / 監視・アラート / バックアップなど、本記事で省略している観点を別途検討する必要があります。
本記事の表記ルール
用語の使い分け
記事を書いていて自分でも混乱したので、言葉の使い方についても最初に定義しておきます。この記事ではKubernetesの公式ドキュメントに基づき、以下のように使い分けます。12345
| 用語 | 何を表現するか | 本記事での表記方針 |
|---|---|---|
| リソース | Pod / Service など API で扱う対象 | 原則この意味で使う。CPU / メモリ / requests / limits などを指すときは、必要に応じて計算リソースと明示する |
| コンポーネント | クラスタを構成する実装要素 (kube-apiserver / etcd / kube-scheduler / kubelet など) | コントロールプレーンやノード側の構成要素を指す語として使う |
| オブジェクト | クラスタの望ましい状態を表す永続エンティティ (Pod / Deployment など) | マニフェストで作成・管理する対象を指す語として使う |
コマンド出力結果など
この記事ではコマンドの出力結果も記載していきますが、その中のAGEやリソース名の末尾にランダム生成されるsuffixなどは文脈上で必要な場合を除いて、以下のようにxやaaaなどでダミー化します。
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# nginx-aaaaa 1/1 Running 0 xm
# nginx-bbbbb 1/1 Running 0 xm
# nginx-ccccc 1/1 Running 0 xmKubernetes の概要
まずKubernetesとは、コンテナ化されたアプリのデプロイやスケーリングなどを自動化する「コンテナオーケストレーションツール」です。他にもDocker SwarmやApache Mesosといったツールがありますが、Kubernetesがデファクトスタンダードです。3大クラウド (Google Cloud、AWS、Azure) ではKubernetesのマネージドサービスが提供されています。
KubernetesはGoogleのBorgやOmegaの知見をもとに開発され6、現在はOSSとしてCloud Native Computing Foundation (CNCF) によって管理されているGo製のツールです。ギリシャ語で「操舵手」や「パイロット」を意味していて7、そのため船の舵がアイコンになっています。
そもそもコンテナとは
Kubernetesは「コンテナをオーケストレーションするツール」ですが、そのオーケストレーション対象である「コンテナ」とは何なのかについても簡単に整理してみます。
一言で雑に表現すると、コンテナとはNamespace (名前空間) という仕組みで隔離されたLinuxのプロセスです8。Linux NamespaceにはMount、PID、Network、UTS、IPC、User、Cgroup、Timeの計8種類があり9、コンテナの隔離ではそのうちPID (プロセス)、Network (ネットワーク)、Mount (ファイルシステム) などが特に使われます。そして、Cgroupsという仕組みで各コンテナやプロセスに割り当てるCPU / メモリなどの計算リソースを制限します10。
ここで重要なのは、コンテナは完全に別のマシンや別のOSではないという点です。各コンテナからは自分専用のプロセス空間、ネットワーク、ファイルシステムが見えるため、小さな独立したマシンのように振る舞いますが、実際にはホストOSのカーネルを共有しています11。イメージとしては以下のような感じです。
flowchart TB
subgraph Host["Host マシン / Linux"]
direction TB
K["共有: カーネル"]
subgraph Containers[" "]
direction LR
A["コンテナ A<br/>PID namespace<br/>Net namespace<br/>Mount namespace<br/>cgroup"]
B["コンテナ B<br/>PID namespace<br/>Net namespace<br/>Mount namespace<br/>cgroup"]
end
K ~~~ A
K ~~~ B
end
classDef default fill:transparent,stroke:#6b7280
style Host fill:transparent,stroke:#6b7280
style Containers fill:transparent,stroke:transparent
style K fill:transparent,stroke:transparent
つまりコンテナは、「1台のLinuxの中で、見える範囲と使える計算リソースを強く絞った実行環境」と捉えるとイメージしやすいです。コンテナが比較的軽量で、同じホスト上に高密度で載せやすいのは、こうした仕組みによるものです。
「コンテナイメージをビルドする」とは
コンテナイメージは、Dockerfileの命令を順に積み上げて作る「読み取り専用の複数のファイルシステムレイヤーと、CmdやEnvなどの起動設定をまとめたもの」です。本筋からは少し外れる内容なので、興味のある方のみ以下を開いて読んでみてください。
コンテナイメージのビルドの仕組みを深掘り
まず結論ですが、コンテナイメージとは「コンテナを作るための元データ」です。正確には、読み取り専用の複数のファイルシステムレイヤーと、Cmd、Envなどの起動設定をまとめたものです1213。そしてビルドとは「Dockerfileに書かれた命令を上から順に実行し、ファイルシステムの変更差分と設定情報を積み上げてコンテナイメージを作る」ことです。(Linuxにおけるファイルシステムとは、データをディスク上で整理するルールのことで、/home/name/...のようにフォルダやファイルの階層構造そのものを指します)
以下のDockerfileを例として考えてみます。
FROM alpine:latest
COPY app.py /app/
ENV MY_APP_VERSION=1.0この例ではalpine:latestはすでに1つのコンテナイメージであり、このイメージを土台として、app/app.pyを追加する差分が新しいレイヤーとして積み上がります。ここでいう「レイヤー」とは、直前までのファイルシステムに対する変更差分のことです。一方、ENV MY_APP_VERSION=1.0はファイルを増やす命令ではなく、イメージの設定情報に環境変数を記録する命令です。
コンテナイメージは、このように複数の読み取り専用レイヤーと設定情報から構成されます。(コンテナを起動すると、これらの読み取り専用レイヤーの上に、そのコンテナ専用の書き込み可能なレイヤーも1枚追加されます1214)
上記のDockerfileをdocker build -t my-image:v1 .でビルドして、コンテナイメージの中身を確認してみます。docker image inspectを使うと、ビルドされたイメージの詳細情報を確認できます15。以下は今回の説明に関係する部分だけ抜粋したものです。
docker image inspect my-image:v1
# [
# {
# "Id": "sha256:xxx",
# "RootFS": {
# "Type": "layers",
# "Layers": [
# "sha256:989e799e634906e94dc9a5ee2ee26fc92ad260522990f26e707861a5f52bf64e", // Alpine 由来のレイヤー
# "sha256:3e0efc0c962cfdda31aab29a94db20c3b465be2147712937057b7d73607c796d" // COPY で追加されたレイヤー
# ]
# },
# "Metadata": {
# "LastTagTime": "2026-03-11T21:17:35.057209334+09:00"
# },
# "Config": {
# "Cmd": [
# "/bin/sh"
# ],
# "Entrypoint": null,
# "Env": [
# "PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
# "MY_APP_VERSION=1.0" // Dockerfile の "ENV MY_APP_VERSION=1.0" はここに記録される
# ],
# "Labels": null,
# "OnBuild": null,
# "User": "",
# "Volumes": null,
# "WorkingDir": "/"
# }
# }
# ]レイヤー情報はRootFS.Layersに、ENV MY_APP_VERSION=1.0はレイヤーではなくConfig.Envという設定値の1つに含まれていることがわかります。(あとで見ますが、RootFS.Layersに含まれる2つのうち、1つはベースイメージalpine:latestに含まれていたレイヤー、もう1つはCOPY app.py /app/で追加されたレイヤーです)
docker image save my-image:v1 -o my-image.tarで、コンテナイメージをtarアーカイブとして取り出せます16。以下のコマンドで中身を展開してみます。
tar -tf my-image.tar
# blobs/
# blobs/sha256/
# blobs/sha256/00734834cdc61051079b427c349dcc0d338e5af54d9235900868c25f00ed29f1
# blobs/sha256/17e5645281546e5b6cb336853a58c49a02df3612df77dba5aa003eeac0299cc1
# blobs/sha256/3e0efc0c962cfdda31aab29a94db20c3b465be2147712937057b7d73607c796d
# blobs/sha256/989e799e634906e94dc9a5ee2ee26fc92ad260522990f26e707861a5f52bf64e
# blobs/sha256/a3b70f309301534ce7c7fb5564a03c0a0f216aefd0e6856a7cb6d6cc6674b7c4
# blobs/sha256/cc63b61e69632ab13b5604dde713b9525759f87dc54faea6ef9e1abb9686dd55
# index.json
# manifest.json
# oci-layout
# repositoriesマニフェスト (manifest.json) やレイヤーのデータ (blobs/sha256/989e...、blobs/sha256/3e0e...) が含まれています。ここには、以下の2通りで1つのイメージが表現されています。
- Open Container Initiative (OCI)
- Docker互換用の補助情報
OCIはコンテナのイメージ形式や実行方法を標準化するための仕様群で、Linux Foundation傘下のプロジェクトです17。これは色々なツールで理解できるコンテナの共通語のようなものであり、DockerなどのツールはこのOCIの仕様に従うことで相互運用しやすくなっています。(上記出力内で言うと、oci-layoutやindex.jsonなどがOCI側の情報です。)
例としてmanifest.jsonをピックアップして中身を見てみます。これは上記2通りのうち、Docker互換用 (docker saveで使用される) のマニフェストです。
tar -xOf my-image.tar manifest.json | jq .
# [
# {
# "Config": "blobs/sha256/cc63b61e69632ab13b5604dde713b9525759f87dc54faea6ef9e1abb9686dd55",
# "RepoTags": [
# "my-image:v1"
# ],
# "Layers": [
# "blobs/sha256/989e799e634906e94dc9a5ee2ee26fc92ad260522990f26e707861a5f52bf64e",
# "blobs/sha256/3e0efc0c962cfdda31aab29a94db20c3b465be2147712937057b7d73607c796d"
# ],
# "LayerSources": {
# "sha256:3e0efc0c962cfdda31aab29a94db20c3b465be2147712937057b7d73607c796d": {
# "mediaType": "application/vnd.oci.image.layer.v1.tar",
# "size": 2048,
# "digest": "sha256:3e0efc0c962cfdda31aab29a94db20c3b465be2147712937057b7d73607c796d"
# },
# "sha256:989e799e634906e94dc9a5ee2ee26fc92ad260522990f26e707861a5f52bf64e": {
# "mediaType": "application/vnd.oci.image.layer.v1.tar",
# "size": 8724480,
# "digest": "sha256:989e799e634906e94dc9a5ee2ee26fc92ad260522990f26e707861a5f52bf64e"
# }
# }
# }
# ]最初に「コンテナイメージは複数の読み取り専用レイヤーから構成される」と説明しましたが、それを具体的に見てみます。上記出力のうち以下部分がalpine:latest由来のレイヤーと、COPY app.py /app/で追加されたレイヤーです。
# "Layers": [
# "blobs/sha256/989e799e634906e94dc9a5ee2ee26fc92ad260522990f26e707861a5f52bf64e",
# "blobs/sha256/3e0efc0c962cfdda31aab29a94db20c3b465be2147712937057b7d73607c796d"
# ],alpine:latest由来のレイヤー
tar -tf blobs/sha256/989e799e634906e94dc9a5ee2ee26fc92ad260522990f26e707861a5f52bf64e | head
# bin/
# bin/arch
# bin/ash
# bin/base64
# bin/bbconfig
# bin/busybox
# bin/cat
# bin/chattr
# bin/chgrp
# bin/chmodCOPY app.py /app/で追加されたレイヤー
tar -tf blobs/sha256/3e0efc0c962cfdda31aab29a94db20c3b465be2147712937057b7d73607c796d | head
# app/
# app/app.pyまとめると、Kubernetesはコンテナオーケストレーションツールです。コンテナとは隔離されたLinuxのプロセスであり、コンテナイメージをビルドすることはDockerfileの命令を順に適用して、レイヤーと設定情報を作ることです。コンテナイメージとは、それらの読み取り専用レイヤーと設定情報をまとめたものです。
Docker との関係
個人的に「コンテナといえばDocker」の印象が強かったので、ここではKubernetesとDockerの関係について簡単に紹介します。
まずDockerは「イメージのビルド / 管理、コンテナ実行、CLIなどをまとめて提供するツール」です。Dockerのようなツールがないと「そもそもコンテナとは」で紹介したLinuxプロセス / ネットワーク / マウントの分離、計算リソースの制限など、低レイヤーの操作をすべて人間がやる必要があります。Dockerはこれらをdocker runで高レベルに抽象化しています。通常、Kubernetesは複数のサーバー (物理マシンやVM。これを「ノード」と言います) を束ねて、1つの論理的な集合である「クラスタ」を作ります。しかし手元のPCでVMを3台も立ち上げるのは大変なので、ローカルでKubernetesを動かすときは、その再現にDockerが使われることがあります。(今回もDockerが使用されるkindというツールを使っていきます)
ただし基本的に、Kubernetesは開発者がdocker runを直接実行してコンテナを並べていく仕組みではありません。「どんなコンテナを、いくつ動かしたいか」を「マニフェスト」という設定ファイルとして定義し、Kubernetes (正確には、後述するkubeletというコンポーネント) がそれを解釈して各ノード上でコンテナを動かします。
まとめると、Dockerはビルド、CLI、API、イメージ管理、コンテナ実行をまとめた統合ツールである一方、Kubernetesは主にコンテナの配置、復旧、宣言的管理などを担当するオーケストレーションツールです。そのため、用途がそもそも違います。
なお、Kubernetesはオープンソースとして公開されていますが、それをベースに各社が独自機能を加えてパッケージングした「ディストリビューション」も存在します。代表的なのはRed HatによるOpenShift18 で、エンタープライズ向けの管理・セキュリティ機能などが組み込まれており、業務環境では候補に挙がることも多いと考えられます。ただし、本記事では扱いません。
まとめ
この章ではコンテナの仕組み、Kubernetesが「コンテナオーケストレーションツール」として何を解決するのかを概観しました。次章では、Kubernetesが必要になる具体的な背景をもう一段掘り下げます。
Kubernetes が必要な理由
ここまでKubernetes、コンテナ、Dockerあたりのキーワードについて触れてきました。では次に、Kubernetes (というより、コンテナオーケストレーション) が必要な理由について軽く見ていきます。(詳しくは、以下の神記事を読めば間違いないです)
ざっくりと上記の記事の理解をまとめます。本当に雑まとめですが、以下だと解釈しています。
- 以下2つの大きな流れの中でコンテナの需要が爆増
- OSレベルの仮想化 ⇒ コンテナによる仮想化
- モノリス ⇒ マイクロサービス
- アプリケーションで使うコンテナが増えすぎて管理・運用がツラくなる
コンテナが増えると、その運用が人間によって正確に回される前提になり、例えば以下のような点でツラくなりそうです。
- アプリケーションのデプロイのたびに複数のサーバー (VMや物理マシン) でコンテナの取得・停止・差し替えを繰り返すため、更新漏れで環境差分が起きやすい
- デプロイ後に不具合が起きた際のロールバックも手作業なので、時間がかかる
- コンテナが落ちた際は、どのサーバーで何が落ちたか
docker psやdocker logsで原因を確認 ⇒ 再起動する必要がある - 必要なコンテナ数や各サーバーに必要なCPU / メモリを人が見積もるため、過不足が出やすい
- 機能追加や障害のたびに「どのサーバーに配置するか」を判断する必要があり、運用が属人化しやすい
Kubernetesは上記のような課題を「複数サーバー上のコンテナ運用を、宣言した状態に自動で収束させる」ことによって解決しました。なお、この記事ではKubernetesがデファクトスタンダードになった理由や、他のコンテナオーケストレーションツールの紹介などはバッサリと割愛します。
まとめ
この章ではコンテナのスケール・更新・障害復旧を手作業で運用する難しさと、それを宣言的に扱うKubernetesの役割を整理しました。次章では実際にkindでローカルクラスタを作り、PodからGatewayまで基本リソースを順に動かしていきます。
ローカルで触る Kubernetes
早速ローカル環境で触りながらKubernetesを理解していきます。
前提
ローカルマシンでのKubernetes実行にはkindというツールを使用します (他にもminikube19 やK3s20 といったツールがあります)。kindはPodmanやnerdctlといったツールもproviderとして利用できますが、この記事では後続の手順でdockerコマンドも使用するため、Docker Engineを前提に進めます。21
また、Kubernetes APIとのやり取りにはkubectlという公式CLIを使います。
各種ツールのインストール
- docker: kindのproviderとして使用
- kind: ローカルKubernetesクラスタの作成に使用
- kubectl: クラスタの確認やマニフェストの適用に使用
インストール方法は色々ありますが、ここではWSL2上のUbuntu 24.04 LTSを前提に、公式ドキュメントに沿った方法で進めます。2223
Docker Engine
Docker Engineは公式のapt repositoryからインストールします。
sudo apt update
sudo apt install -y ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo \"${UBUNTU_CODENAME:-$VERSION_CODENAME}\") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo usermod -aG docker $USER
newgrp dockerkubectl
kubectlは公式バイナリをインストールします。この記事ではv1.35.1を使用します。
KUBECTL_VERSION=v1.35.1
curl -LO "https://dl.k8s.io/release/${KUBECTL_VERSION}/bin/linux/amd64/kubectl"
chmod +x kubectl
sudo mv kubectl /usr/local/bin/kubectlkind
kindは公式配布バイナリを使います。この記事ではv0.31.0を使用します。
KIND_VERSION=v0.31.0
curl -Lo ./kind "https://kind.sigs.k8s.io/dl/${KIND_VERSION}/kind-linux-amd64"
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind実行環境とバージョン確認
- 実行環境
C:\Users\xxx>wsl --version
# WSL バージョン: 2.6.1.0
# カーネル バージョン: 6.6.87.2-1
# WSLg バージョン: 1.0.66
# MSRDC バージョン: 1.2.6353
# Direct3D バージョン: 1.611.1-81528511
# DXCore バージョン: 10.0.26100.1-240331-1435.ge-release
# Windows バージョン: 10.0.26200.7840- 各種ツール
kubectl version --client
# Client Version: v1.35.1
# Kustomize Version: v5.7.1
kind version
# kind v0.31.0 go1.25.5 linux/amd64
docker version --format '{{.Client.Version}}'
# 28.4.0クラスタを作る
なにはともあれ、まずはクラスタを作っていきましょう。なお、以降の手順は~/k8s-labのような作業用ディレクトリを1つ作って、そこをカレントディレクトリにしている前提で進めます。記事を進める中で複数のYAMLファイルを同じディレクトリに作成していきます。
- クラスタの作成
# デフォルトではシングルノードのクラスタになるため、マルチノードの場合は明示
cat > kind-config.yaml <<'EOF'
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
EOF
kind create cluster --config kind-config.yaml
# Creating cluster "kind" ...
# ✓ Ensuring node image (kindest/node:v1.35.0) 🖼
# ✓ Preparing nodes 📦 📦 📦
# ✓ Writing configuration 📜
# ✓ Starting control-plane 🕹️
# ✓ Installing CNI 🔌
# ✓ Installing StorageClass 💾
# ✓ Joining worker nodes 🚜
# Set kubectl context to "kind-kind"
# You can now use your cluster with:
# kubectl cluster-info --context kind-kind
# Have a nice day! 👋- クラスタ内のノードの確認
kubectl get node -o wide
# NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
# kind-control-plane Ready control-plane xs v1.35.0 172.18.0.4 <none> Debian GNU/Linux 12 (bookworm) 6.6.87.2-microsoft-standard-WSL2 containerd://2.2.0
# kind-worker Ready <none> xs v1.35.0 172.18.0.5 <none> Debian GNU/Linux 12 (bookworm) 6.6.87.2-microsoft-standard-WSL2 containerd://2.2.0
# kind-worker2 Ready <none> xs v1.35.0 172.18.0.2 <none> Debian GNU/Linux 12 (bookworm) 6.6.87.2-microsoft-standard-WSL2 containerd://2.2.0コントロールプレーン ×1とワーカーノード ×2が作成されたことが確認できました。つまり、現在以下のような状態になっています。なお、ここからMermaidの図を多用していきますが、基本は無色にして、説明対象のコンポーネントだけ青くハイライトします。
flowchart LR
subgraph Cluster["クラスタ"]
subgraph ControlPlane["コントロールプレーン<br>(kind-control-plane)"]
direction TB
etcd["etcd"]
apiserver["kube-apiserver"]
scheduler["kube-scheduler"]
controller["kube-controller-manager"]
end
subgraph LeftWorker["ワーカーノード<br>(kind-worker2)"]
direction TB
kubeletLeft["kubelet"]
proxyLeft["kube-proxy"]
end
subgraph RightWorker["ワーカーノード<br>(kind-worker)"]
direction TB
kubeletRight["kubelet"]
proxyRight["kube-proxy"]
end
ControlPlane ~~~ LeftWorker
ControlPlane ~~~ RightWorker
end
classDef default fill:transparent,stroke:#6b7280
style Cluster fill:transparent,stroke:#6b7280
style ControlPlane fill:transparent,stroke:#6b7280
style LeftWorker fill:transparent,stroke:#6b7280
style RightWorker fill:transparent,stroke:#6b7280
kind の仕組み
これ以降kindのコマンドは出てこないため余談ですが、kindは kubernetes in dockerの略で、その名の通りKubernetesをDockerコンテナの中で動かす技術です。ローカルマシンでKubernetesをテストするために使います。
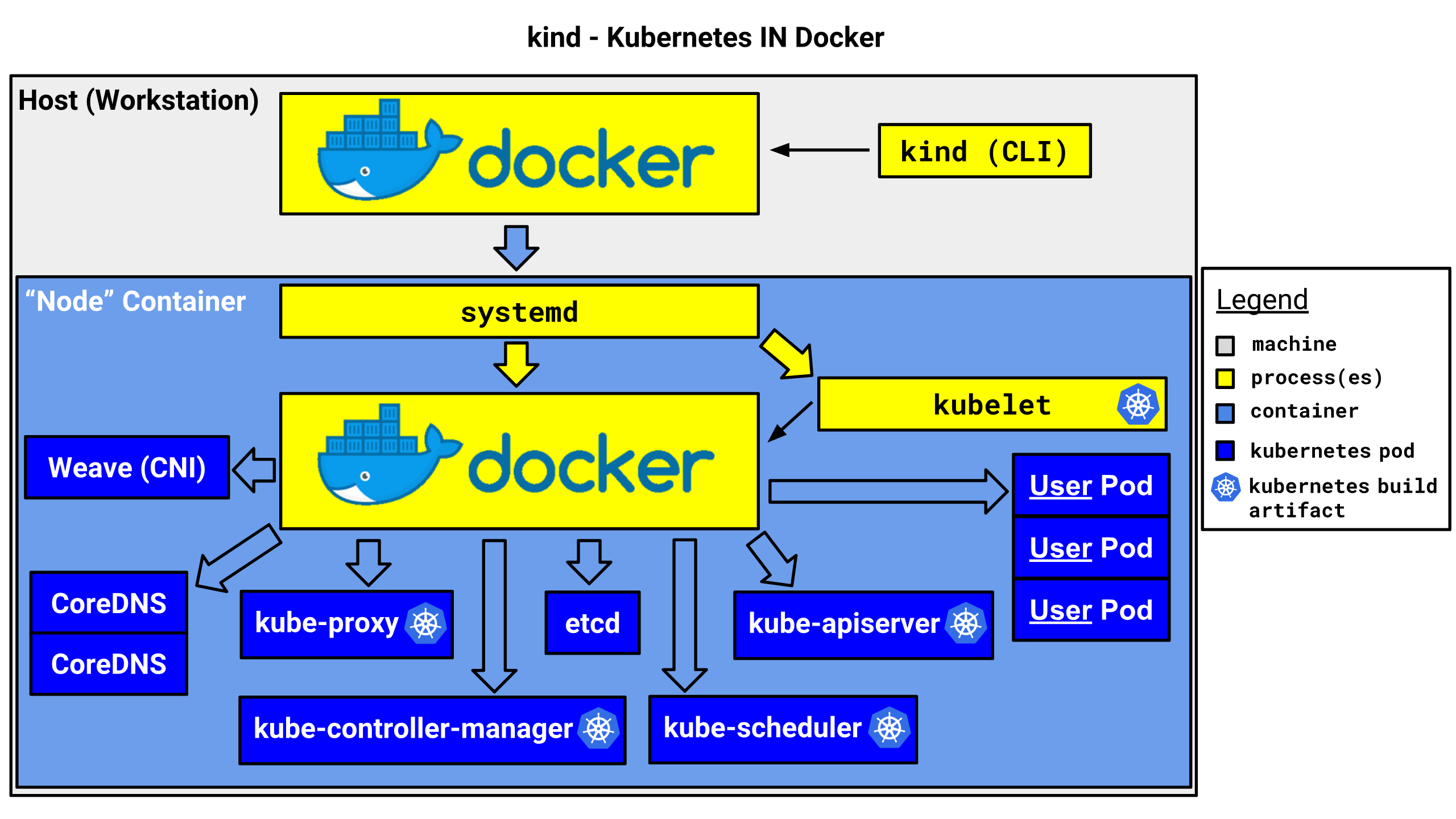
上記のkind create clusterのログにも出力されていますが、kindest/nodeというコンテナイメージでKubernetesのノードとして動くための土台を作っています。kindはこのコンテナの中でkubeadmというクラスタ初期化ツールを使用して各ノードを初期化しています。
kubectl と kube-apiserver
kubectl get node -o wideで、Kubernetesクラスタ内のノードに関する情報を確認しました。ここで出てくるのがkube-apiserverです。これがAPIサーバーとして動いており、kubectlなどの外部クライアントだけでなく、kube-controller-managerやkubeletなどの内部コンポーネントからのリクエストも受けます。(実際にクラスタの作成などを行うのは他コンポーネントですが、それは別途紹介します)
flowchart LR
kubectl["kubectl"]
subgraph Cluster["クラスタ"]
subgraph ControlPlane["コントロールプレーン<br>"]
direction TB
etcd["etcd"]
apiserver["kube-apiserver"]
scheduler["kube-scheduler"]
controller["kube-controller-manager"]
end
end
kubectl -->|API リクエスト| apiserver
classDef default fill:transparent,stroke:#6b7280
style Cluster fill:transparent,stroke:#6b7280
style ControlPlane fill:transparent,stroke:#6b7280
style kubectl fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
style apiserver fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
Pod を作る
途中から始めたい方は、サンプルリポジトリ
zenn-k8s-handsonをcloneしてmake ckpt-00を実行すると、この節の前提状態 (空のkindクラスタ) を再現できます。詳細は同リポジトリのREADMEを参照してください。
話を本筋に戻します。kind create clusterでKubernetesクラスタを作成しました。再掲ですが、現在は以下のようなコントロールプレーンとワーカーノードの状況になっています。
flowchart LR
subgraph Cluster["クラスタ"]
subgraph ControlPlane["コントロールプレーン<br>(kind-control-plane)"]
direction TB
etcd["etcd"]
apiserver["kube-apiserver"]
scheduler["kube-scheduler"]
controller["kube-controller-manager"]
end
subgraph LeftWorker["ワーカーノード<br>(kind-worker2)"]
direction TB
kubeletLeft["kubelet"]
proxyLeft["kube-proxy"]
end
subgraph RightWorker["ワーカーノード<br>(kind-worker)"]
direction TB
kubeletRight["kubelet"]
proxyRight["kube-proxy"]
end
ControlPlane ~~~ LeftWorker
ControlPlane ~~~ RightWorker
end
classDef default fill:transparent,stroke:#6b7280
style Cluster fill:transparent,stroke:#6b7280
style ControlPlane fill:transparent,stroke:#6b7280
style LeftWorker fill:transparent,stroke:#6b7280
style RightWorker fill:transparent,stroke:#6b7280
KubernetesではPodやServiceなどのリソースをYAMLのマニフェストで定義できます。kindで作成したクラスタのコントロールプレーンでも、kube-apiserverやetcdなどを起動するためのマニフェストがコンテナ内に置かれています。(詳しい役割や中身の説明は後ほどします)
docker exec -it kind-control-plane bash
root@kind-control-plane:/# ls etc/kubernetes/manifests/
# etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml各種コンポーネントのYAMLがそれぞれコントロールプレーンのコンテナ (kind-control-plane) 内のetc/kubernetes/manifests/に存在することがわかります。これらコンポーネントのマニフェストは、この段階で紹介するには比較的複雑なので割愛しますが、ひとまずKubernetesはマニフェストというYAMLファイルで構成を管理することの紹介でした。
ではマニフェストを書いて、実際にPodを作ってみます。改めてですがPodはKubernetesの最小実行単位です。青い部分を作っていきます。
flowchart LR
subgraph Node1["ワーカーノード<br>(kind-worker)"]
direction TB
kubelet1["kubelet"]
proxy1["kube-proxy"]
subgraph Pod["Pod: nginx"]
direction LR
container1_1["Container: nginx"]
end
kubelet1 ~~~ Pod
proxy1 ~~~ Pod
end
classDef default fill:transparent,stroke:#6b7280
style Node1 fill:transparent,stroke:#6b7280
style Pod fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
- マニフェストの作成
cat > pod-nginx.yaml <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
nodeSelector:
kubernetes.io/hostname: kind-worker
containers:
- name: nginx
image: nginx
EOF※kubernetes.io/hostnameの値はクラスタ作成時のノード名に依存するため、各自の環境ではkubectl get nodeで確認した名前を指定してください。kindではデフォルトでkind-worker、kind-worker2のように、クラスタ名 (デフォルトはkind) がノード名のプレフィックスになります。24
動きの理解を重視したいので、この記事ではマニフェストの中身にはあまり立ち入らず、最小限の解説に留めます。
kind: オブジェクトの種類です。Podや、これから説明していくReplicaSet、Deploymentなど指定します。spec: オブジェクトの「あるべき姿」です。例えばPodではspec.containers[].nameがコンテナ名、spec.containers[].imageが実行するイメージ名です。25
マニフェストをクラスタに適用し、Podを作成します。
kubectl apply -f pod-nginx.yaml
# pod/nginx created- 作成したPodの確認
kubectl get pod nginx -o wide
# NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
# nginx 1/1 Running 0 xs 10.244.0.10 kind-worker <none> <none>nginxという名前の単一Podがkind-workerノードで動作している状態 (STATUSがRunning) であることを示しています。Podの80番ポートをローカルの8080番に転送し、アクセスしてみます。
- ポートフォワードで待ち受け
kubectl port-forward pod/nginx 8080:80
# Forwarding from 127.0.0.1:8080 -> 80
# Forwarding from [::1]:8080 -> 80- 別ターミナルからアクセス
curl http://127.0.0.1:8080
# <!DOCTYPE html>
# <html>
# <head>
# <title>Welcome to nginx!</title>
# <style>
# html { color-scheme: light dark; }
# body { width: 35em; margin: 0 auto;
# font-family: Tahoma, Verdana, Arial, sans-serif; }
# </style>
# </head>
# <body>
# <h1>Welcome to nginx!</h1>
# <p>If you see this page, the nginx web server is successfully installed and
# working. Further configuration is required.</p>
# <p>For online documentation and support please refer to
# <a href="http://nginx.org/">nginx.org</a>.<br/>
# Commercial support is available at
# <a href="http://nginx.com/">nginx.com</a>.</p>
# <p><em>Thank you for using nginx.</em></p>
# </body>
# </html>nginxのイメージに入っているindex.htmlの内容が確認できました。
ひとまず最小実行単位であるPodを作ってみました。Podは以下のような役割を持っています。
- Kubernetesの最小実行単位であり、1つ以上のコンテナをまとめる
- 同一Pod内のコンテナはネットワーク名前空間やVolumeを共有する。26
- kubeadmでブートストラップされたクラスタ (kindなどのローカル環境を含む) では、kube-apiserverやkube-schedulerなどコントロールプレーンの主要コンポーネントはstatic Pod (kube-apiserverを介さず、ノード上の特定ディレクトリに置かれたマニフェストからkubeletが直接起動するPod) として動きます27。一方、GKEなどのマネージド環境ではコントロールプレーンはクラウドベンダーが管理するので、ユーザー Podとしては見えなくなっています
Podを直接管理することは基本的にありません。上位概念としてReplicaSetとDeploymentが存在し、それらを通じて間接的に管理されます。
flowchart TB
D["Deployment"]
RS["ReplicaSet"]
P1["Pod"]
P2["Pod"]
D --> RS
RS --> P1
RS --> P2
classDef default fill:transparent,stroke:#6b7280
そのため、ここで作ったPodはひとまず削除しておきます。
kubectl delete pod nginx
# pod "nginx" deleted from default namespaceReplicaSet を作る
次にReplicaSetを作ります。ReplicaSetは指定された数のPodを複製・実行するオブジェクトです。
flowchart TB
D["Deployment"]
RS["ReplicaSet"]
P1["Pod"]
P2["Pod"]
D --> RS
RS --> P1
RS --> P2
classDef default fill:transparent,stroke:#6b7280
style RS fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
前述の通り、あとで説明するDeploymentがReplicaSetを管理しているため、基本的にDeploymentの方を触ります。(とはいえ段階的な理解の促進のために、ReplicaSetも軽く触ります)
- マニフェストの作成
cat > replica-set.yaml <<'EOF'
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
EOFマニフェストの簡単な解説です。
spec.replicas: 作成したいPodの数です。spec.selector.matchLabels: このReplicaSetが管理対象とするPodです。上記の例でいうと、app: nginxというラベルがついたPodを管理対象とするということです。spec.template.metadata.labels: このReplicaSetが新規作成するPodに付与するラベルです。つまり、spec.selector.matchLabelsとセットで同じにする必要があり、「自分で作るPodを、自分の管理対象とする」ということになっています。spec.template.spec: ここはPodのマニフェストと同じです。コンテナイメージなどPodのあるべき姿を定義します。28
クラスタに適用します。
kubectl apply -f replica-set.yaml
# replicaset.apps/nginx created- 確認
# kubectl get rs でも可
kubectl get replicaset
# NAME DESIRED CURRENT READY AGE
# nginx 3 3 3 xsmetadata.nameに指定したnginxという名前のReplicaSetが作成されています。spec.replicasを3に指定したので、3つのPodが起動しています。(3つすべて起動する (READYが3になる) までには、少し時間がかかります)
- Podを直接確認
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# nginx-aaaaa 1/1 Running 0 xs
# nginx-bbbbb 1/1 Running 0 xs
# nginx-ccccc 1/1 Running 0 xsprefixにnginx-とつくPodが3つあることが確認できます。kubectl scaleでレプリカの数を増やしたりもできます。
kubectl scale --replicas=5 -f replica-set.yaml
# replicaset.apps/nginx scaled
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# nginx-ddddd 1/1 Running 0 xs
# nginx-aaaaa 1/1 Running 0 xm
# nginx-bbbbb 1/1 Running 0 xm
# nginx-ccccc 1/1 Running 0 xm
# nginx-eeeee 1/1 Running 0 xsPodの数が5に増えていることが確認できました。
改めてですが、このようにReplicaSetは指定個のPodを常に満たすようにする役割を持っています。人間が実際に触るのは次に紹介するDeploymentが基本であるため、削除しておきます。
kubectl delete replicaset nginx
# replicaset.apps "nginx" deleted from default namespaceDeployment を作る
DeploymentはReplicaSetを管理して、Podのローリングアップデートやロールバックなどを担います。
flowchart TB
D["Deployment"]
RS["ReplicaSet"]
P1["Pod"]
P2["Pod"]
D --> RS
RS --> P1
RS --> P2
classDef default fill:transparent,stroke:#6b7280
style D fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
早速マニフェストを作っていきます。
cat > deployment.yaml <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 50%
maxUnavailable: 0%
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
EOFReplicaSetのマニフェストを再掲しますが、DeploymentはReplicaSetを拡張している感じです。そのため、差分に絞って解説します。
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginxspec.strategy.rollingUpdate.maxSurge:spec.replicasの数に対して更新中に追加で作って良いPod数 (パーセンテージでも指定可) です。spec.strategy.rollingUpdate.maxUnavailable:spec.replicasの数に対して更新中に一時的に利用不可になって良いPod数 (同じくパーセンテージでも指定可) です。
つまり上記の例ではmaxSurgeは50%、spec.replicasは2であるため、その150% である3までは更新中にPodを増やしても良く、またmaxUnavailableは0% なので、常に2つのPodを維持するという設定になっています。なお、maxSurgeとmaxUnavailableのデフォルトはどちらも25% で、両方を同時に0にはできません。
spec.strategy.typeはRollingUpdateとRecreateが選択可能で、デフォルトはRollingUpdateです。RollingUpdateは上記で紹介したように段階的なアップデートを行います。Recreateは更新前に古いPodをすべて停止してから新しいPodを作ります。(一時的に停止時間が発生します。つまりデータの書き込みや互換性の問題で新旧Podの同時稼働が許容できない場合などはRecreateを選択する必要があります)29
- クラスタへの適用
kubectl apply -f deployment.yaml
# deployment.apps/nginx created- 作成したDeploymentの確認
# kubectl get deploy でも可
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# nginx 2/2 2 2 xsnginxという名前のDeploymentが確認できました。spec.replicasを2に設定したため、Podが2つ作成されています。
- Podを直接確認
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# nginx-aaaaaaaaaa-aaaaa 1/1 Running 0 xm
# nginx-aaaaaaaaaa-bbbbb 1/1 Running 0 xm次に、ロールアウトとロールバックを確認してみます。以下のコマンドでDeploymentの状態をwatchします。
kubectl get deployment nginx -n default -w
# NAME READY UP-TO-DATE AVAILABLE AGE
# nginx 2/2 2 2 xmREADYが2/2となっており、これは2つのPodが稼働していることを示します。ではnginxのイメージを暗黙のlatestからバージョン1.29を明示するように変更してみましょう。別ターミナルで以下のコマンドを実行します。
kubectl set image deployment/nginx nginx=nginx:1.29 -n default
# deployment.apps/nginx image updated最初のターミナルに戻ると、以下のようにPodが切り替わっている様子が確認できます。
kubectl get deployment nginx -n default -w
# NAME READY UP-TO-DATE AVAILABLE AGE
# nginx 2/2 2 2 xh
# nginx 2/2 2 2 xh
# nginx 2/2 2 2 xh
# nginx 2/2 0 2 xh
# nginx 2/2 1 2 xh
# nginx 3/2 1 3 xh
# nginx 2/2 1 2 xh
# nginx 2/2 2 2 xh
# nginx 2/2 2 2 xh
# nginx 3/2 2 3 xh
# nginx 2/2 2 2 xh
# nginx 2/2 2 2 xhREADYが3/2になっているタイミングがあります。これはマニフェストの説明と重複しますが、maxSurgeを50% に指定 = Podの数が150% の3まで増えることを許容したために起きた動きです。(AVAILABLE= 利用可能なPodの数も2を維持していることがわかります)
ReplicaSetやPodのレベルでもこの動きは確認可能です。(興味のある方はkubectl get pod -n default -w --show-labelsなどで試してみてください)
以下のようにしてロールバックもできます。(ログは各自確認してみてください)
kubectl rollout undo deployment/nginx -n default
# deployment.apps/nginx rolled backReconciliation Loop を体感する
ここでは、Kubernetesの特徴の1つであるReconciliation Loopを確認します。
その前に、Kubernetesクラスタの状態がどこに保存されるかについて触れておきます。保存を担っているのは (基本的に) etcd30 というkey-value型データストアのコンポーネントです。
flowchart TB
kubectl["kubectl"]
subgraph Cluster["クラスタ"]
subgraph ControlPlane["コントロールプレーン<br>"]
direction TB
etcd["etcd"]
apiserver["kube-apiserver"]
scheduler["kube-scheduler"]
controller["kube-controller-manager"]
end
end
kubectl -->|API リクエスト| apiserver
apiserver -->|状態の保存| etcd
classDef default fill:transparent,stroke:#6b7280
style Cluster fill:transparent,stroke:#6b7280
style ControlPlane fill:transparent,stroke:#6b7280
style etcd fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
このetcdには以下のような情報が保存されています。
- Deployment、PodなどのKubernetesオブジェクトの情報
- Podの配置情報 (どのノードに紐づくかなど)
Kubernetesでは、クラスタの状態がkube-apiserver経由で上記のetcdに保存されます。controllerやkube-scheduler、kubeletなど (後述します) は、そのetcdに保存されている「マニフェストに定義された理想の状態 (desired state)」と「現在 (実際) の状態 (current state)」の差分を見て、desired stateの方に収束させます。
まず動きの確認をしてみます。Deploymentを作って、Podを削除します。
# Pod が常に 2 つは維持されるように設定
kubectl create deployment web --image=nginx --replicas=2
# Pod のステータスを表示
kubectl get pods -w
# NAME READY STATUS RESTARTS AGE
# web-aaaaaaaaaa-aaaaa 1/1 Running 0 xs
# web-aaaaaaaaaa-bbbbb 1/1 Running 0 xs- 別ターミナルでPodを削除
kubectl delete pod -l app=web- 最初のターミナルを確認
kubectl get pods -w
# NAME READY STATUS RESTARTS AGE
# web-aaaaaaaaaa-aaaaa 1/1 Running 0 xs
# web-aaaaaaaaaa-bbbbb 1/1 Running 0 xs
# web-aaaaaaaaaa-aaaaa 1/1 Terminating 0 ys
# web-aaaaaaaaaa-bbbbb 1/1 Terminating 0 ys
# web-aaaaaaaaaa-ccccc 0/1 Pending 0 0s
# web-aaaaaaaaaa-aaaaa 1/1 Terminating 0 ys
# web-aaaaaaaaaa-ccccc 0/1 Pending 0 0s
# web-aaaaaaaaaa-ddddd 0/1 Pending 0 0s
# web-aaaaaaaaaa-ddddd 0/1 Pending 0 0s
# web-aaaaaaaaaa-bbbbb 1/1 Terminating 0 ys
# web-aaaaaaaaaa-ccccc 0/1 ContainerCreating 0 0s
# web-aaaaaaaaaa-ddddd 0/1 ContainerCreating 0 0s
# web-aaaaaaaaaa-bbbbb 0/1 Completed 0 ys
# web-aaaaaaaaaa-aaaaa 0/1 Completed 0 ys
# web-aaaaaaaaaa-bbbbb 0/1 Completed 0 ys
# web-aaaaaaaaaa-bbbbb 0/1 Completed 0 ys
# web-aaaaaaaaaa-aaaaa 0/1 Completed 0 ys
# web-aaaaaaaaaa-aaaaa 0/1 Completed 0 ys
# web-aaaaaaaaaa-ccccc 1/1 Running 0 xs
# web-aaaaaaaaaa-ddddd 1/1 Running 0 xs削除はRunning ⇒ Terminating ⇒ Completed、作成はPending ⇒ ContainerCreating ⇒ RunningとSTATUSがそれぞれ変化しています。つまり、もともとあったPodは削除され、新しいPodが作成された結果、最終的にPodが2つに戻っていることが確認できます。(STATUSの遷移はあくまで今回の例です。詳細は公式ドキュメント31を確認してください)
この裏ではkube-controller-manager内で動く各種controllerと、kube-scheduler、kubeletが以下のような役割で連携しています。32
- Podオブジェクトの不足分補充: 主にReplicaSet controller (kube-controller-manager内)
- ノードへの割り当て: kube-scheduler
- ノード上でのコンテナ起動 / 状態報告: kubelet
flowchart LR
subgraph Cluster["クラスタ"]
subgraph ControlPlane["コントロールプレーン<br>(kind-control-plane)"]
direction TB
etcd["etcd"]
apiserver["kube-apiserver"]
scheduler["kube-scheduler"]
controller["kube-controller-manager"]
end
subgraph Node1["ワーカーノード"]
direction TB
kubelet1["kubelet"]
proxy1["kube-proxy"]
subgraph Pod1["Pod: web-*"]
direction LR
container1_1["Container: nginx"]
end
subgraph Pod2["Pod: web-*"]
direction LR
container2_1["Container: nginx"]
end
kubelet1 ~~~ Pod1
proxy1 ~~~ Pod1
kubelet1 ~~~ Pod2
proxy1 ~~~ Pod2
end
ControlPlane ~~~ Node1
end
classDef default fill:transparent,stroke:#6b7280
style Cluster fill:transparent,stroke:#6b7280
style ControlPlane fill:transparent,stroke:#6b7280
style Node1 fill:transparent,stroke:#6b7280
style Pod1 fill:transparent,stroke:#6b7280
style Pod2 fill:transparent,stroke:#6b7280
style scheduler fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
style controller fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
style kubelet1 fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
「ReplicaSet controller」という言葉が出てきましたが、controllerは特定のリソースを監視し、現在の状態をdesired stateに近づけるための常駐プロセス / ロジックです。ReplicaSet controller以外にも、Deployment controllerやnode controllerなどが存在します。kube-controller-managerは、それらのbuilt-in controllerをまとめて動かすという役割です。32
改めてですが、先ほどコマンドで確認した「Deployment配下のPodが2つ消えた時」の連携フローは以下のようになります。
kubectl delete podでPodの削除を要求- ReplicaSet controller(kube-controller-manager内)がdesiredとactualの差分を検知
- ReplicaSet controllerが不足分のPodを新しく作成
- kube-schedulerがそのPodの配置先ノードを決定
- 割り当て先ノードのkubeletがコンテナを起動し、状態をkube-apiserverに反映
- 新しいPodがReadyになると、希望レプリカ数に戻る
sequenceDiagram
autonumber
participant U as kubectl
participant API as kube-apiserver
participant RSC as ReplicaSet controller
participant SCH as kube-scheduler
participant K as kubelet (割り当て先 node)
U->>API: Pod を削除
API-->>RSC: Watch でレプリカ不足を検知
Note right of RSC: ReplicaSet controller は kube-controller-manager 内で動作
RSC->>API: 代替 Pod を作成
API-->>SCH: 未割り当て Pod を検知
SCH->>API: 配置先 node を決定
API-->>K: Pod 定義を反映
K->>K: イメージ取得・コンテナ起動
K->>API: Pod Running / Ready
Deploymentが管理するのはReplicaSetであるため、Deployment controllerは前面に出てこず、主役はReplicaSet controllerです3334。
確認用に作ったweb Deploymentはここで削除しておきます。
kubectl delete deployment web
# deployment.apps "web" deletedここまでで、Pod、ReplicaSet、Deploymentは以下のような役割分担でレイヤーが分離されていることを確認してきました。
- PodはKubernetesの最小単位であり、1つ以上のコンテナをグルーピングする
- ReplicaSetは指定数のPodを常に満たすように維持する
- DeploymentはReplicaSetのローリングアップデート / ロールバック / 履歴管理などの更新戦略を管理する
flowchart TB
D["Deployment"]
RS["ReplicaSet"]
P1["Pod"]
P2["Pod"]
D --> RS
RS --> P1
RS --> P2
classDef default fill:transparent,stroke:#6b7280
Service を作る
Serviceは、変動するPodに対する安定した接続先と、L4の負荷分散を提供します。
クラスタ内のすべてのPodはそれぞれ独自のIPアドレスを持っており、それを使ってアプリケーションに直接アクセスできます。しかしDeploymentによる更新や障害復旧ではPodが置き換わることがあり、個々のIPアドレスを接続先として前提にはできません。そこでServiceがPod群への安定した接続先の役割を担います。
flowchart LR
podA["Pod-A"] --> svc["Service<br/>10.1.0.2"]
subgraph backends[" "]
direction TB
podB1["Pod-B"]
podB2["Pod-C"]
podB3["Pod-D"]
end
svc --> podB1
svc --> podB2
svc --> podB3
classDef default fill:transparent,stroke:#6b7280
style backends fill:transparent,stroke:transparent
ServiceはClusterIP、NodePort、LoadBalancer、ExternalNameの4種類です。typeフィールドの値で指定し、省略した場合のデフォルトはClusterIPです。ClusterIP、NodePort、LoadBalancerはPod群の公開方法の違いで、ExternalNameは少し性質の異なる特殊なServiceです。今回は記事の流れの都合上、ClusterIPのみ紹介します。35
なお、spec.clusterIP: Noneを指定する「ヘッドレスサービス」もあり、これはtypeとは別軸の概念です。通常のServiceが仮想IP (ClusterIP) を持ちロードバランスを介してPodに振り分けるのに対し、ヘッドレスサービスは仮想IPを持たず、DNS名を引くと配下のPodのIPが直接 (複数のAレコードとして) 返ってきます。StatefulSetで個々のPodを区別して接続したい場合や、クライアント側でロードバランスを行いたい場合などに使われます。36
まず前提として、Serviceがトラフィックを転送する先のPodが必要ですが、先ほど作ったものが残っている場合はそのまま使います。(作っていない方は Deployment を作るの手順で作ってください)
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# nginx 2/2 2 2 23hsこのDeploymentのPodを選択するServiceを作ります。
cat > service.yaml <<'EOF'
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
type: ClusterIP
selector:
app: nginx
ports:
- port: 80
targetPort: 80
EOFspec.selectorは、Service転送先のPodの条件です。これはDeploymentが作成するPodのラベル (spec.template.metadata.labels) と一致させます。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
strategy:
...
template:
metadata:
labels:
app: nginx # Pod のラベル。これを用いて Service の転送先として指定する
spec:
...また、先ほどServiceにはClusterIPやNodePortなど4種類あるとお伝えしましたが、spec.typeを指定しないとデフォルトでClusterIPになります。
- クラスタへの適用
kubectl apply -f service.yaml
# service/nginx created- 作成したServiceの確認
# kubectl get svc でも可
kubectl get service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# kubernetes ClusterIP 10.96.0.1 <none> 443/TCP xm
# nginx ClusterIP 10.96.205.113 <none> 80/TCP xskubernetes Service と kube-apiserver の関係
明示的に作ったnginx以外にkubernetesというServiceが存在します。これはクラスタ内からKubernetes APIのサーバー (= kube-apiserver) に到達するための固定エンドポイントで、今回触っているkindのローカル環境だとバックエンドにkube-apiserverのPodが存在します。(例えばGKEではGoogle Cloudが管理するコントロールプレーンのエンドポイントになります)
つまり今回のkindの環境においてkube-apiserverはPodであり、Service (kubernetes) がそのフロントに立っているということです。
厳密には、
default/kubernetesServiceは通常のServiceと異なりselectorを持たず、kube-apiserver自身がエンドポイントを直接登録する特殊なServiceです (pkg/controlplane/reconcilers)。本記事では「Serviceの前段にkube-apiserver Podがある」というイメージのまま読み進めて問題ないです。
flowchart LR
subgraph Cluster["クラスタ"]
subgraph ControlPlane["コントロールプレーン<br>(kind-control-plane)"]
direction TB
etcd["etcd"]
apiserver["kube-apiserver"]
scheduler["kube-scheduler"]
controller["kube-controller-manager"]
end
subgraph LeftWorker["ワーカーノード<br>(kind-worker2)"]
direction TB
kubeletLeft["kubelet"]
proxyLeft["kube-proxy"]
end
subgraph RightWorker["ワーカーノード<br>(kind-worker)"]
direction TB
kubeletRight["kubelet"]
proxyRight["kube-proxy"]
end
ControlPlane ~~~ LeftWorker
ControlPlane ~~~ RightWorker
end
classDef default fill:transparent,stroke:#6b7280
style Cluster fill:transparent,stroke:#6b7280
style ControlPlane fill:transparent,stroke:#6b7280
style LeftWorker fill:transparent,stroke:#6b7280
style RightWorker fill:transparent,stroke:#6b7280
style apiserver fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
その点についてちょっとだけ深掘りしてみます。kubernetes Serviceのマニフェストを見てみましょう。
kubectl -n default get service kubernetes -o yaml
# apiVersion: v1
# kind: Service
# metadata:
# ...
# spec:
# clusterIP: 10.96.0.1
# clusterIPs:
# - 10.96.0.1
# internalTrafficPolicy: Cluster
# ipFamilies:
# - IPv4
# ipFamilyPolicy: SingleStack
# ports: # ここに注目
# - name: https
# port: 443
# protocol: TCP
# targetPort: 6443
# sessionAffinity: None
# type: ClusterIP
# status:
# loadBalancer: {}spec.ports[]が、Serviceが公開するポートの定義です。このkubernetes Serviceは443/TCPへのアクセスを受け、バックエンドの6443に転送することを期待した設定になっています。転送先のバックエンドの設定も確認してみます。
kubectl get endpointslice -n default -l kubernetes.io/service-name=kubernetes -o yaml
# apiVersion: v1
# items:
# - addressType: IPv4
# apiVersion: discovery.k8s.io/v1
# endpoints:
# - addresses:
# - 172.18.0.5 # バックエンドの IP アドレス
# conditions:
# ready: true
# kind: EndpointSlice
# metadata:
# creationTimestamp: "<TIMESTAMP>"
# generation: 3
# labels:
# kubernetes.io/service-name: kubernetes
# name: kubernetes
# namespace: default
# resourceVersion: "<RESOURCE_VERSION>"
# uid: <UID>
# ports:
# - name: https
# port: 6443
# protocol: TCP
# kind: List
# metadata:
# resourceVersion: ""items[].endpoints[].addresses[]がバックエンドのIPアドレスです。この環境ではkube-apiserverのPodを指しています。実際にPodを見てみます。
$ kubectl -n kube-system get pod -l component=kube-apiserver -o wide
# NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
# kube-apiserver-kind-control-plane 1/1 Running 0 xm 172.18.0.5 kind-control-plane <none> <none>kube-apiserver-kind-control-planeというPodが1つ存在することが確認できました。まとめると、今回のkindの環境においてはkube-apiserverは以下のようになっているということです。
flowchart LR
podA["Pod-X"] --> svc["Service(kubernetes)<br/>10.96.0.1:443"]
subgraph backends[" "]
direction TB
podB1["kube-apiserverのPod<br/>(kube-apiserver-kind-control-plane)<br/>172.18.0.5:6443"]
end
svc --> podB1
classDef default fill:transparent,stroke:#6b7280
style backends fill:transparent,stroke:transparent
クラスタ内から Service を経由して Pod に疎通する
話を本筋に戻して、先ほど作ったnginx Serviceにクラスタ内から通信してみましょう。alpineという名前のPodを作って、コンテナに入ります。
kubectl run alpine -it --rm --image alpine -- ash
# All commands and output from this session will be recorded in container logs, including credentials and sensitive information passed through the command prompt.
# If you don't see a command prompt, try pressing enter.
# / #別ターミナルから確認するとalpineのPodが確認できます。
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# alpine 1/1 Running 0 xs
# nginx-aaaaaaaaaa-ccccc 1/1 Running 0 xm
# nginx-aaaaaaaaaa-ddddd 1/1 Running 0 xmKubernetesクラスタでは通常CoreDNS (Kubernetesと同様にCNCFで管理されるOSS37) がDNSサーバーとして動作しており、PodからのDNS問い合わせに応答します。
実際にドメイン名からIPアドレスを引いてみましょう。
/ # nslookup nginx
# Server: 10.96.0.10
# Address: 10.96.0.10:53
# ** server can't find nginx.cluster.local: NXDOMAIN
# Name: nginx.default.svc.cluster.local
# Address: 10.96.120.128
# ** server can't find nginx.cluster.local: NXDOMAIN
# ** server can't find nginx.svc.cluster.local: NXDOMAIN
# ** server can't find nginx.svc.cluster.local: NXDOMAIN10.96.120.128が返ってきていることがわかります。これが先ほど作ったnginx Service (ClusterIP) です。
kubectl get service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# kubernetes ClusterIP 10.96.0.1 <none> 443/TCP xm
# # ↓これ
# nginx ClusterIP 10.96.120.128 <none> 80/TCP xsnslookupで指定したnginxは、FQDNではなく短縮名 (相対名) です。alpine PodはdefaultのNamespaceに存在するため、/etc/resolv.confのsearchの順に試され、nginx.default.svc.cluster.localが解決されます。ここでいうNamespaceとはLinuxのNamespaceではなく、リソースを論理的に分割するためのKubernetesの機能です。
kubectl exec alpine -- cat /etc/resolv.conf
# search default.svc.cluster.local svc.cluster.local cluster.local
# nameserver 10.96.0.10
# options ndots:5上記のようにalpine PodのDNSリゾルバを確認してみると10.96.0.10にDNS問い合わせをする設定になっています。なお、10.96.0.10はkind / kubeadmのデフォルトService CIDR (10.96.0.0/12) におけるCoreDNSのClusterIPで、クラスタのService CIDR設定によって変わります。38
また、前述のCoreDNSのPod前段にはkube-dnsというServiceがあり、それはkube-systemという別のNamespaceに存在します。(kube-systemはシステムコンポーネントを配置するNamespaceで、運用や権限管理に使用するようなコンポーネントをアプリ用ワークロードと分離することなどに使われます)
# -n で Namespace を指定
kubectl -n kube-system get service kube-dns
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP xh図で流れをまとめると、nslookup nginxでは裏で以下が行われていたということです。
flowchart TD
subgraph NS_DEFAULT["Namespace: default"]
A["Pod: alpine"]
S["Service: nginx<br/>ClusterIP: 10.96.120.128:80"]
N1["Pod: nginx-*"]
N2["Pod: nginx-*"]
S --> N1
S --> N2
end
subgraph NS_KSYS["Namespace: kube-system"]
D["Service: kube-dns<br/>ClusterIP: 10.96.0.10:53"]
C1["Pod: coredns-*"]
C2["Pod: coredns-*"]
D --> C1
D --> C2
end
subgraph CP["Control Plane"]
API["kube-apiserver"]
end
A -- "1: nslookup nginx<br/>DNS query" --> D
C1 -. "Service/Endpoint情報をwatch" .-> API
C2 -. "Service/Endpoint情報をwatch" .-> API
C1 -- "2: Aレコード応答<br/>nginx.default.svc.cluster.local<br/>= 10.96.120.128" --> A
A -- "3: wget nginx:80" --> S
classDef default fill:transparent,stroke:#6b7280
style NS_DEFAULT fill:transparent,stroke:#6b7280
style NS_KSYS fill:transparent,stroke:#6b7280
style CP fill:transparent,stroke:#6b7280
このような仕組みに基づいてwget nginxでService経由の疎通確認ができるようになっています。
/ # wget -O - nginx
# Connecting to nginx (10.96.120.128:80)
# writing to stdout
# <!DOCTYPE html>
# <html>
# <head>
# <title>Welcome to nginx!</title>
# ...
# </html>
# - 100% |****************************************************| 615 0:00:00 ETA
# written to stdoutnginxのイメージに入っているindex.htmlの内容が確認できました。
確認が終わったら、alpineのシェルを終了します。--rmを付けて起動しているため、Podも自動で削除されます。
/ # exitこのようにServiceの中でもClusterIPはPodのIPアドレスを抽象化し、安定した接続先を提供する役割を持っています。
ここまで紹介してきませんでしたが、kubectl get allとするとService、Deployment、ReplicaSet、Podが一覧で取得できます。(Deploymentがロールアウトの履歴を保持するため、DESIREDが0であるReplicaSetも表示されます)
kubectl get all
# NAME READY STATUS RESTARTS AGE
# pod/nginx-aaaaaaaaaa-ccccc 1/1 Running 0 xm
# pod/nginx-aaaaaaaaaa-ddddd 1/1 Running 0 xm
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP xh
# service/nginx ClusterIP 10.96.120.128 <none> 80/TCP xm
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/nginx 2/2 2 2 xh
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/nginx-aaaaaaaaaa 2 2 2 xh
# replicaset.apps/nginx-bbbbbbbbbb 0 0 0 xhGateway を作る
途中から始めたい方は、サンプルリポジトリ
zenn-k8s-handsonをcloneしてmake ckpt-05を実行すると、この節の前提状態 (kindクラスタ +nginxのDeployment / Service) を再現できます。
Gateway APIはKubernetesのL4/L7ルーティングを定義するAPI群です39。先ほどまで紹介してきたServiceは、Podの集合に対する安定した接続先を提供するAPIで、今回紹介するGateway APIの転送先にもなります。ServiceもLoadBalancerやNodePortによって外部公開できますが、その責務は基本的に「どのPod群に届けるか」を表すことです。これに対してGateway APIは、その手前で「どこで受けて、どのルールで、どのServiceに流すか」を定義します。
この章ではGateway APIのHTTP/HTTPSのL7ルーティングに絞って解説していきます。(Ingress APIは新機能の追加が止まっており (frozen)、Kubernetesプロジェクトとしては新規実装にはGateway APIの使用が推奨されています40)
まず今回使用するリソースについて紹介します。(これがすべてではなく、他にもあります4142)
- GatewayClass: Gatewayを処理する実装 (controller) の定義
- Gateway: どこで受けるか (リスナーやポート) の定義
- HTTPRoute: 転送ルールの定義
Kubernetesクラスタがリクエストを受ける際の流れとして、概念レベルでシンプルに表現すると以下のようになります。
flowchart LR C([client]) G[Gateway] R[HTTPRoute] S[Service] P1[Pod] P2[Pod] C -. "HTTP(S) request" .-> G G --> R R -- "Routing rule" --> S S --> P1 S --> P2 classDef default fill:transparent,stroke:#6b7280
Gateway APIのリソースは、通信の入口と転送ルールを宣言する設定です。controller (常駐型のプロセス) がGatewayClass / Gateway / HTTPRouteと参照先のServiceなどを監視し、待ち受けポート、ホストやパスのマッチ条件、転送先Serviceといった内容を実装側のデータプレーン (後述します) に反映します。
ここでは実際にGateway APIの各種リソースとロードバランサ (以後、LBと省略します) を作って、クラスタ外部からの通信を確認していきます。最終的に以下図の構成を作ります。(技術的な詳細を省略した概念的な図です)
flowchart TD
C[Client] --> EGP["External Gateway<br/>(LB + Data Plane)"]
GC[Gateway Controller]
subgraph INSIDE["Kubernetes Cluster"]
GW["Gateway"]
GWC[GatewayClass]
HR1["HTTPRoute"]
HR2["HTTPRoute"]
N1["Pod: nginx-*"]
N2["Pod: nginx-*"]
E1["Pod: echo-*"]
E2["Pod: echo-*"]
end
HR1 -. attaches to .-> GW
HR2 -. attaches to .-> GW
GC -. provisions/programs .-> EGP
GWC -. selects controller .-> GC
GW -. configured by .-> GC
EGP -->|Host nginx.local| N1
EGP -->|Host nginx.local| N2
EGP -->|Host echo.local| E1
EGP -->|Host echo.local| E2
classDef default fill:transparent,stroke:#6b7280
style INSIDE fill:transparent,stroke:#6b7280
Gateway APIという「外部向けの受け口」を実際に動かすためにはLBの実装が必要です。kindはローカル検証向けであるためLBの実装を持っておらず、今回はその役割を担うcloud-provider-kindというcontrollerを追加します。
前述のように、Gateway APIの各リソースはあくまで宣言であり、仕様のようなものです。cloud-provider-kindはcontrollerとして各リソースをwatchし、以下を用意することで外部から通信を受けられる状態にします。
- 外部受け口に相当するトンネル / ポートマッピング (LBに相当)
- EnvoyというL7ルーティングを行うプロキシツール43のコンテナ
- GatewayClassなどのKubernetesリソース
つまりは図の以下のあたりを用意してくれるということです。
flowchart TD
C[Client] --> EGP["External Gateway<br/>(LB + Data Plane)"]
GC[Gateway Controller]
subgraph INSIDE["Kubernetes Cluster"]
GW["Gateway"]
GWC[GatewayClass]
HR1["HTTPRoute"]
HR2["HTTPRoute"]
N1["Pod: nginx-*"]
N2["Pod: nginx-*"]
E1["Pod: echo-*"]
E2["Pod: echo-*"]
end
HR1 -. attaches to .-> GW
HR2 -. attaches to .-> GW
GC -. provisions/programs .-> EGP
GWC -. selects controller .-> GC
GW -. configured by .-> GC
EGP -->|Host nginx.local| N1
EGP -->|Host nginx.local| N2
EGP -->|Host echo.local| E1
EGP -->|Host echo.local| E2
classDef default fill:transparent,stroke:#6b7280
style INSIDE fill:transparent,stroke:#6b7280
style EGP fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
style GC fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
style GWC fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
なおEnvoyやkube-proxyなど通信を処理・転送する実行系のコンポーネントを「データプレーン」と呼ぶことが一般的なようで、上記の図中などでは既に登場していますが、この記事でも以後Envoyが絡むところでデータプレーンという表現を使っていきます。
cloud-provider-kind の起動と GatewayClass の確認
早速cloud-provider-kindを起動します。なお、cloud-provider-kind v0.10.0とkind v0.31.0 / Kubernetes v1.35の組み合わせで動作確認しています。
docker rm -f cloud-provider-kind 2>/dev/null || true
docker run -d --name cloud-provider-kind --rm \
--network host \
--cap-add NET_ADMIN \
-v /var/run/docker.sock:/var/run/docker.sock \
registry.k8s.io/cloud-provider-kind/cloud-controller-manager:v0.10.0個人的にはややこしく感じた部分ですが、この1つのコンテナを動かすだけで、裏では先ほど紹介したEnvoyコンテナの起動やGatewayClassの作成などが行われています4445。
動いていることを確認します。
docker ps --filter name=cloud-provider-kind
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# xxxxxxxxxxxx registry.k8s.io/cloud-provider-kind/cloud-controller-manager:v0.10.0 "/bin/cloud-provider…" xs ago Up xs cloud-provider-kind次に、GatewayClassを確認します。前述のように、起動したcloud-provider-kindが自動で同名のGatewayClassを作成してくれています。
kubectl get gatewayclass
# NAME CONTROLLER ACCEPTED AGE
# cloud-provider-kind kind.sigs.k8s.io/gateway-controller True xhマニフェストも見てみます。
kubectl get gatewayclass -o yaml
# apiVersion: v1
# items:
# - apiVersion: gateway.networking.k8s.io/v1
# kind: GatewayClass
# metadata:
# creationTimestamp: "<TIMESTAMP>"
# generation: 1
# name: cloud-provider-kind
# resourceVersion: "<RESOURCE_VERSION>"
# uid: <UID>
# spec:
# controllerName: kind.sigs.k8s.io/gateway-controller # Gateway を処理する controller
# description: cloud-provider-kind gateway API
# status:
# conditions:
# - lastTransitionTime: "<TIMESTAMP>"
# message: GatewayClass is accepted by this controller.
# observedGeneration: 1
# reason: Accepted
# status: "True"
# type: Accepted # 処理される前提が整っている
# kind: List
# metadata:
# resourceVersion: ""GatewayClassは「どの実装 (controller) がGatewayを処理するかを表すクラス」と紹介しました。上記マニフェストでいうと、items.spec.controllerNameのkind.sigs.k8s.io/gateway-controllerがGatewayを処理するcontrollerであるということです。ただしcontrollerは常駐型のプロセスであり、「controller」というリソースが存在してその名前を示しているわけではありません。これはむしろ、そのプロセスを照合するためのIDのような意味合いが強いです。
また、status.conditions.typeがAcceptedになっており、これは既にcontrollerがこのGatewayClassを認識し、処理される前提が整っていることを示しています。
flowchart TD
C[Client] --> EGP["External Gateway<br/>(LB + Data Plane)"]
GC[Gateway Controller]
subgraph INSIDE["Kubernetes Cluster"]
GW["Gateway"]
GWC[GatewayClass]
HR1["HTTPRoute"]
HR2["HTTPRoute"]
N1["Pod: nginx-*"]
N2["Pod: nginx-*"]
E1["Pod: echo-*"]
E2["Pod: echo-*"]
end
HR1 -. attaches to .-> GW
HR2 -. attaches to .-> GW
GC -. provisions/programs .-> EGP
GWC -. selects controller .-> GC
GW -. configured by .-> GC
EGP -->|Host nginx.local| N1
EGP -->|Host nginx.local| N2
EGP -->|Host echo.local| E1
EGP -->|Host echo.local| E2
classDef default fill:transparent,stroke:#6b7280
style INSIDE fill:transparent,stroke:#6b7280
style GC fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
style GWC fill:#006cff88,fill-opacity:0.53,stroke:#006cff88,stroke-width:2px
echo の Service と Deployment を追加する
次に、L7レイヤーでのルーティングを確認するため、ServiceとDeploymentを新しく追加します。(nginxの一式も前章で作成済みのものをそのまま使う想定です)
cat > deploy-svc.yaml <<'EOF'
apiVersion: v1
kind: Service
metadata:
name: echo
spec:
type: ClusterIP
selector:
app: echo
ports:
- port: 80
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo
spec:
replicas: 2
selector:
matchLabels:
app: echo
template:
metadata:
labels:
app: echo
spec:
containers:
- name: echo
image: registry.k8s.io/echoserver:1.10
ports:
- containerPort: 8080
EOF今更ですが、Kubernetesのマニフェストは1ファイル1リソースではなく、1ファイルに複数リソースの定義ができます。(同一マニフェスト内ではServiceを先に書くことが推奨されています46)
- クラスタへの適用
kubectl apply -f deploy-svc.yaml
# deployment.apps/echo created
# service/echo created現時点で、以下のようになっている想定です。(echoという名前のServiceとDeploymentを作りました)
kubectl get deployment,service
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/echo 2/2 2 2 xh
# deployment.apps/nginx 2/2 2 2 xh
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/echo ClusterIP 10.96.27.137 <none> 80/TCP xh
# service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP xh
# service/nginx ClusterIP 10.96.120.128 <none> 80/TCP xhGateway と HTTPRoute を作成して外部から疎通させる
次に、GatewayとHTTPRouteを作ります。前述のようにGatewayは受け口としてのリスナーやポートを、HTTPRouteは転送ルールを定義します。
- マニフェスト作成
cat > gateway-routing.yaml <<'EOF'
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: web-gateway
spec:
gatewayClassName: cloud-provider-kind
listeners:
- name: http
protocol: HTTP
port: 80
allowedRoutes:
namespaces:
from: Same
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: web-route-nginx
spec:
parentRefs:
- name: web-gateway
hostnames:
- nginx.local
rules:
- matches:
- path:
type: PathPrefix
value: /
backendRefs:
- name: nginx
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: web-route-echo
spec:
parentRefs:
- name: web-gateway
hostnames:
- echo.local
rules:
- matches:
- path:
type: PathPrefix
value: /
backendRefs:
- name: echo
port: 80
EOF- クラスタへの適用
kubectl apply -f gateway-routing.yaml
# gateway.gateway.networking.k8s.io/web-gateway created
# httproute.gateway.networking.k8s.io/web-route-nginx created
# httproute.gateway.networking.k8s.io/web-route-echo created- 作成したリソースの確認
kubectl get gateway,httproute
# NAME CLASS ADDRESS PROGRAMMED AGE
# gateway.gateway.networking.k8s.io/web-gateway cloud-provider-kind 172.18.0.3 True xs
# NAME HOSTNAMES AGE
# httproute.gateway.networking.k8s.io/web-route-echo ["echo.local"] xs
# httproute.gateway.networking.k8s.io/web-route-nginx ["nginx.local"] xsGatewayのPROGRAMMEDがTrueであり、ADDRESSが付与されていれば、外部から到達できる受け口が構成済みです。
echoの方を例に、HTTPRouteも確認してみます。
kubectl describe httproute web-route-echo
# Name: web-route-echo
# Namespace: default
# Labels: <none>
# Annotations: <none>
# API Version: gateway.networking.k8s.io/v1
# Kind: HTTPRoute
# Metadata:
# Creation Timestamp: <TIMESTAMP>
# Generation: 1
# Resource Version: <RESOURCE_VERSION>
# UID: <UID>
# Spec:
# Hostnames:
# echo.local
# Parent Refs:
# Group: gateway.networking.k8s.io
# Kind: Gateway
# Name: web-gateway
# Rules:
# Backend Refs:
# Group:
# Kind: Service
# Name: echo
# Port: 80
# Weight: 1
# Matches:
# Path:
# Type: PathPrefix
# Value: /
# Status:
# Parents:
# Conditions:
# Last Transition Time: <TIMESTAMP>
# Message: Route is accepted.
# Observed Generation: 1
# Reason: Accepted
# Status: True
# Type: Accepted
# Last Transition Time: <TIMESTAMP>
# Message: All references resolved
# Observed Generation: 1
# Reason: ResolvedRefs
# Status: True
# Type: ResolvedRefs
# Controller Name: kind.sigs.k8s.io/gateway-controller
# Parent Ref:
# Group: gateway.networking.k8s.io
# Kind: Gateway
# Name: web-gateway
# Events: <none>status.parents[].conditions[].TypeがAccepted、ResolvedRefsになっていますが、これは先ほど作成したHTTPRouteがバックエンド (echo Service) の参照解決に成功していることを意味しています。(ここがBackendNotFoundになっている場合は、Service名やポート番号の参照先が誤っている可能性が高いです)
実際にリクエストを送ってみます。
GW_IP=$(kubectl get gateway web-gateway -o jsonpath='{.status.addresses[0].value}')
echo "$GW_IP"
# kubectl get gateway の ADDRESS で表示された 172.18.0.3
curl -s -H 'Host: nginx.local' "http://${GW_IP}/" | head
curl -s -H 'Host: echo.local' "http://${GW_IP}/"nginx.localでnginxのHTML、echo.localでechoのレスポンスが返れば成功です。
cloud-provider-kindで付与されたGatewayのADDRESSは、利用環境によってはそのままホストから到達できない場合があります。私のWSL2環境ではネットワーク経路の問題によるものか、curl http://${GW_IP}が失敗することがありました。その場合は以下のようにGateway用に作成されたEnvoyコンテナ内から疎通確認するのが確実です。Gateway関連リソースを作成してからEnvoyコンテナが起動するまで数秒〜数十秒かかる場合があります。
docker ps --filter 'name=kindccm-gw'でコンテナが起動していることを確認してから以下を実行してください。GW_C=$(docker ps --filter 'name=kindccm-gw' --format '{{.Names}}') docker exec "$GW_C" bash -lc ' exec 3<>/dev/tcp/127.0.0.1/80 printf "GET / HTTP/1.1\r\nHost: nginx.local\r\nConnection: close\r\n\r\n" >&3 cat <&3 | head -n 20 '
これでExternal Gateway ⇒ nginx / echo Podの流れで、クラスタ外部からPodまで到達できることが確認できました。
構成の振り返りと EndpointSlice
改めて、ここまでで確認した構成です。(:の後に記載しているのが作成してきたリソース名です)
flowchart TD
C[Client] --> EGP["External Gateway<br/>(LB + Data Plane):<br/>kindccm-gw-*<br/>(Envoy container)"]
GC[Gateway Controller:<br/>cloud-provider-kind]
subgraph INSIDE["Kubernetes Cluster"]
GW["Gateway:<br/>web-gateway"]
GWC[GatewayClass:<br/>cloud-provider-kind]
HR1["HTTPRoute:<br/>web-route-nginx"]
HR2["HTTPRoute:<br/>web-route-echo"]
N1["Pod: nginx-*"]
N2["Pod: nginx-*"]
E1["Pod: echo-*"]
E2["Pod: echo-*"]
end
HR1 -. attaches to .-> GW
HR2 -. attaches to .-> GW
GC -. provisions/programs .-> EGP
GWC -. selects controller .-> GC
GW -. configured by .-> GC
EGP -->|Host nginx.local| N1
EGP -->|Host nginx.local| N2
EGP -->|Host echo.local| E1
EGP -->|Host echo.local| E2
classDef default fill:transparent,stroke:#6b7280
style INSIDE fill:transparent,stroke:#6b7280
上記の図は、説明の簡略化のために技術的に割愛している部分がいくつかありました。本当は以下のようになっています。
flowchart TD
C[Client]
CPK["Gateway controller:<br/>cloud-provider-kind"]
GDP["External Gateway<br/>(LB + Data Plane):<br/>kindccm-gw-*<br/>(Envoy container)"]
subgraph INSIDE["Kubernetes Cluster"]
KAS[kube-apiserver]
GWC["GatewayClass:<br/>cloud-provider-kind"]
GW["Gateway:<br/>web-gateway"]
HR1["HTTPRoute:<br/>web-route-nginx"]
HR2["HTTPRoute:<br/>web-route-echo"]
SVCN["Service:<br/>nginx"]
SVCE["Service:<br/>echo"]
EPSN["EndpointSlice:<br/>nginx"]
EPSE["EndpointSlice:<br/>echo"]
N1["Pod: nginx-*"]
N2["Pod: nginx-*"]
E1["Pod: echo-*"]
E2["Pod: echo-*"]
end
C --> GDP
GWC -. controllerName .-> CPK
GW -. gatewayClassName .-> GWC
HR1 -. parentRefs .-> GW
HR2 -. parentRefs .-> GW
HR1 -->|backendRef| SVCN
HR2 -->|backendRef| SVCE
SVCN --> EPSN
SVCE --> EPSE
EPSN --> N1
EPSN --> N2
EPSE --> E1
EPSE --> E2
CPK -. watches GatewayClass/Gateway/HTTPRoute/Service/EndpointSlice via API .-> KAS
CPK -. programs dataplane with xDS .-> GDP
GDP -->|Host nginx.local via EndpointSlice| N1
GDP -->|Host nginx.local via...| N2
GDP -->|Host echo.local via EndpointSlice| E1
GDP -->|Host echo.local via...| E2
classDef default fill:transparent,stroke:#6b7280
style INSIDE fill:transparent,stroke:#6b7280
Gateway controllerは各リソースではなくkube-apiserverをwatchしており、Gateway、Service、EndpointSliceの状態をデータプレーンに反映しています。
EndpointSliceはServiceのバックエンド (PodのIPアドレス・ポート番号・Ready状態など) を保持するAPIリソースであり、これを見れば、どのPodに通信を流せるか確認できます。(EndpointSliceはv1.21でGAとなった、Endpoints (v1) の後継APIです。Kubernetesのバージョン1.33でEndpointsが公式にdeprecated扱いとなりましたが、削除予定はなく、現状は読み書き時に警告が出ます47)
以下のコマンドで、EndpointSlice経由でService配下のPodのIPアドレスを確認できます。
kubectl get endpointslice -l kubernetes.io/service-name=nginx -o wide
# NAME ADDRESSTYPE PORTS ENDPOINTS AGE
# nginx-xxxxx IPv4 80 10.244.1.2,10.244.2.2 xh
kubectl get endpointslice -l kubernetes.io/service-name=echo -o wide
# NAME ADDRESSTYPE PORTS ENDPOINTS AGE
# echo-yyyyy IPv4 8080 10.244.2.3,10.244.1.2 xh最後に、今回の流れを簡潔にまとめると次の通りです。
cloud-provider-kindを起動する- GatewayClassが自動作成される
- Gatewayで受け口 (ポート / リスナー) を定義する
- HTTPRouteでHost / Path毎のバックエンドを定義する
- Gatewayの
ADDRESSあてにHostヘッダ付きでリクエストし、到達を確認する
これでL7ルーティングを宣言、外部公開し、状態 (status) で検証するというGateway APIの基本サイクルを一通り確認できました。
クリーンアップ
ここで作ったもののうち、後続の章でもそのまま使うのはecho / nginxのDeploymentとServiceです。一方で、Gateway APIの確認のために作ったGateway、HTTPRoute、そしてcloud-provider-kind、cloud-provider-kindが自動作成したGatewayClassはこの先では基本的に使いません。以降も使うecho / nginxは残しつつ、Gateway API固有のものだけ削除しておきます。
kubectl delete httproute web-route-nginx web-route-echo
kubectl delete gateway web-gateway
docker rm -f cloud-provider-kind
kubectl delete gatewayclass cloud-provider-kind※GatewayClassはcloud-provider-kindが起動したままだと再作成される可能性があるため、上記のように先にコンテナを落としてから実行するのが安全です。
これでGatewayを作る章は終わりです。GatewayClass / Gateway / HTTPRouteによるL7ルーティングを宣言し、GatewayのADDRESS経由でPodまで外部から到達できることまで確認しました。
まとめ
この章ではkind上でPod / ReplicaSet / Deployment / Service / Gatewayを一通り動かし、Reconciliation Loopの挙動も確認しました。次章では、これらの上に乗るIstio・Helm・Prometheusなどの周辺ツールが何を担うのか、概念レベルで整理します。
Kubernetes 周辺用語とツール
Kubernetesについて調べていると、「サービスメッシュ」「Istio」「GitOps」といった言葉を目にすることがあります。最初のうちはそれが設計上の概念なのか、具体的なツールなのか、あるいはどの領域の話なのかわからずツラいです。この章では、そうしたKubernetes周辺の用語について、まずは全体の中での位置づけをつかめるようになることを意識して、概要レベルで整理していきます。
サービスメッシュと Istio、Envoy
サービスメッシュは、マイクロサービス間通信の制御をアプリケーション自身ではなくインフラ側で横断的に扱う仕組みです。Kubernetesクラスタ内のPodに、通信を担うコンテナ (サイドカーと表現されることがあります) を追加し、すべてのネットワークトラフィックをインターセプトするのが代表的な方法です。(以下の図のようにサービス間の相互通信が網 (=メッシュ) のように張り巡らされることからサービスメッシュと呼ばれます)
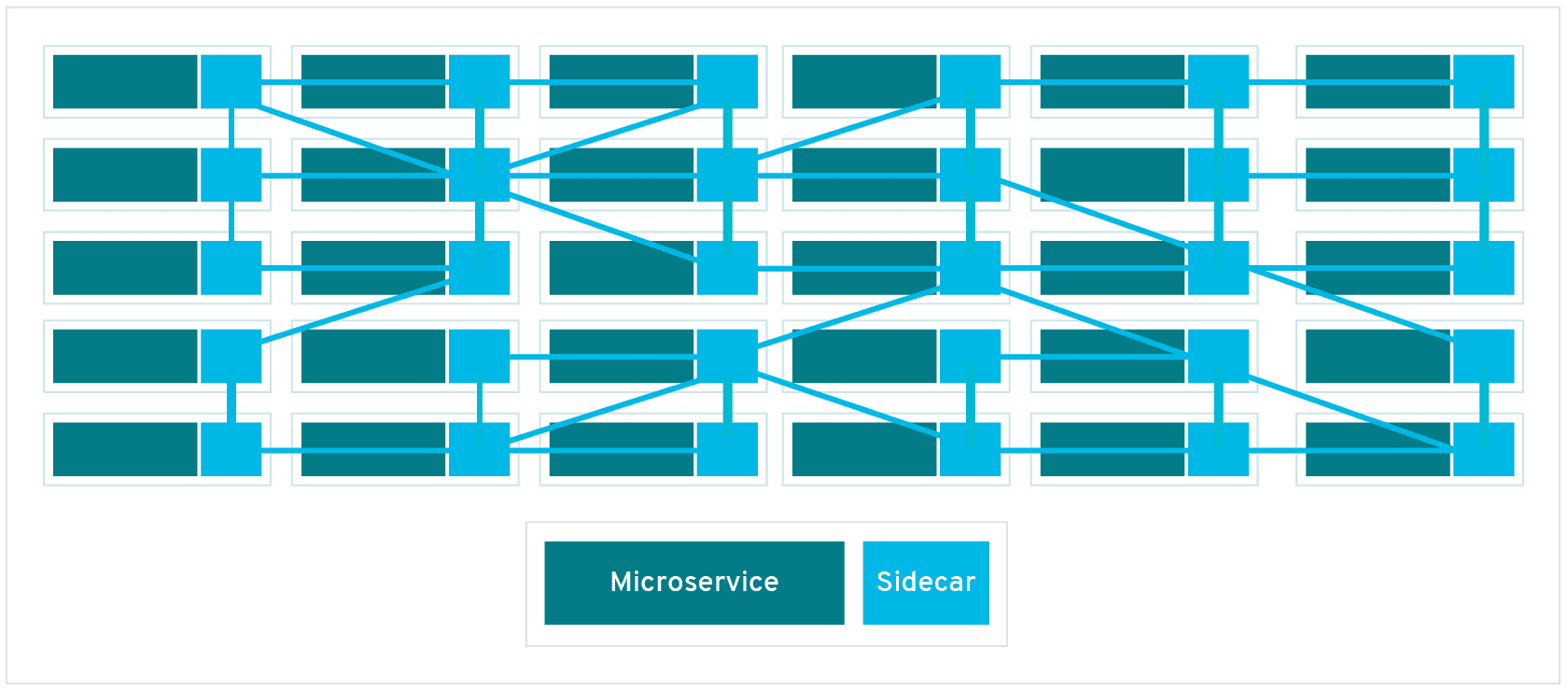
このサイドカーはプロキシとしてサービス間の通信を透過的に処理し、トラフィックの管理 / 分散、暗号化、認証、モニタリング、ロギングなど、様々な機能を提供します。
サービスメッシュを実装する代表的なOSSとしてIstioがあります。コントロールプレーンとデータプレーンという2つのプレーンから成るアーキテクチャになっています。
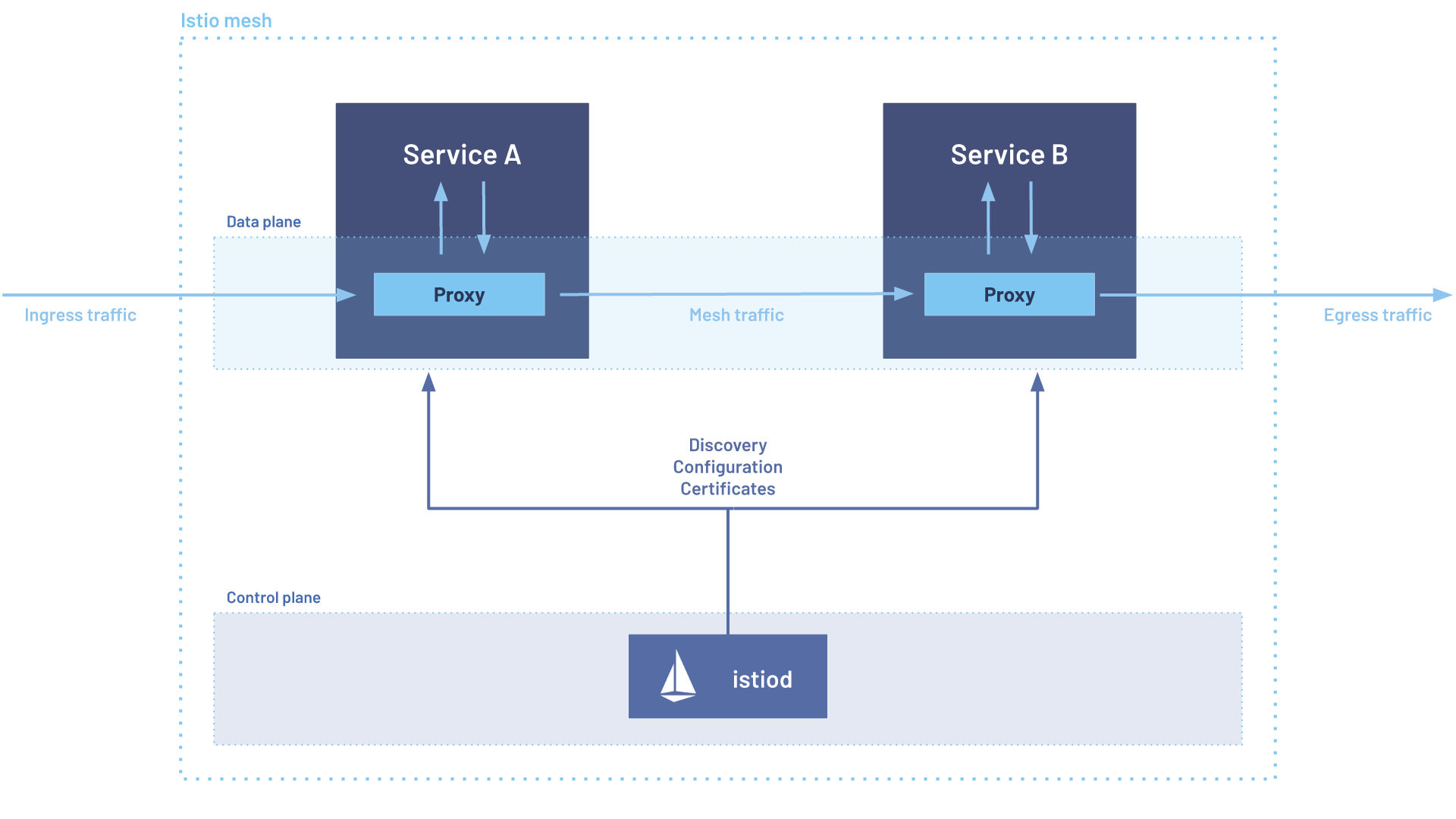
今回紹介するサイドカー形式のIstioではEnvoyがデータプレーンを担います。コントロールプレーンでは、各Podでサイドカーとして動くEnvoyの設定などを行います。なお、Istioではambient modeという各Podにサイドカーを入れないパターンもあります。48
Google CloudではCloud Service Mesh49 というサービスがあり、Istioベースのマネージドなサービスメッシュとして存在します。Cloud Service Mesh で紹介します。
監視、サービスディスカバリと Prometheus、Grafana
Kubernetesはクラスタ自体はもちろんのこと、それを構成するノードやPod、コンテナなど、監視対象が多岐にわたります。さらに、スケールやローリングアップデートなどで、Podの名前やIPアドレスも頻繁に入れ替わります。
ここで重要になるのが「サービスディスカバリ」です。サービスディスカバリは「いま監視すべき対象はどれか」を自動で見つけ続ける仕組みで、上述のように動的なKubernetesの環境では必須の考え方です。(Podに変化が起きるたびに手動で設定更新をするのは非現実的です)
Prometheusは、このサービスディスカバリをKubernetesと組み合わせて実現できる、CNCFにホストされたOSSです50。Prometheusは従来型の「ホストに監視エージェントを追加してメトリクスを監視基盤にPushする方式」とは異なり、Prometheusのサーバー自身が監視対象のメトリクス情報を定期的に取得するPull型です。これによってPod、ノード、Serviceなどの情報を自動的に検出・追従でき、設定を監視側で一元的に管理しやすいのが特徴です。
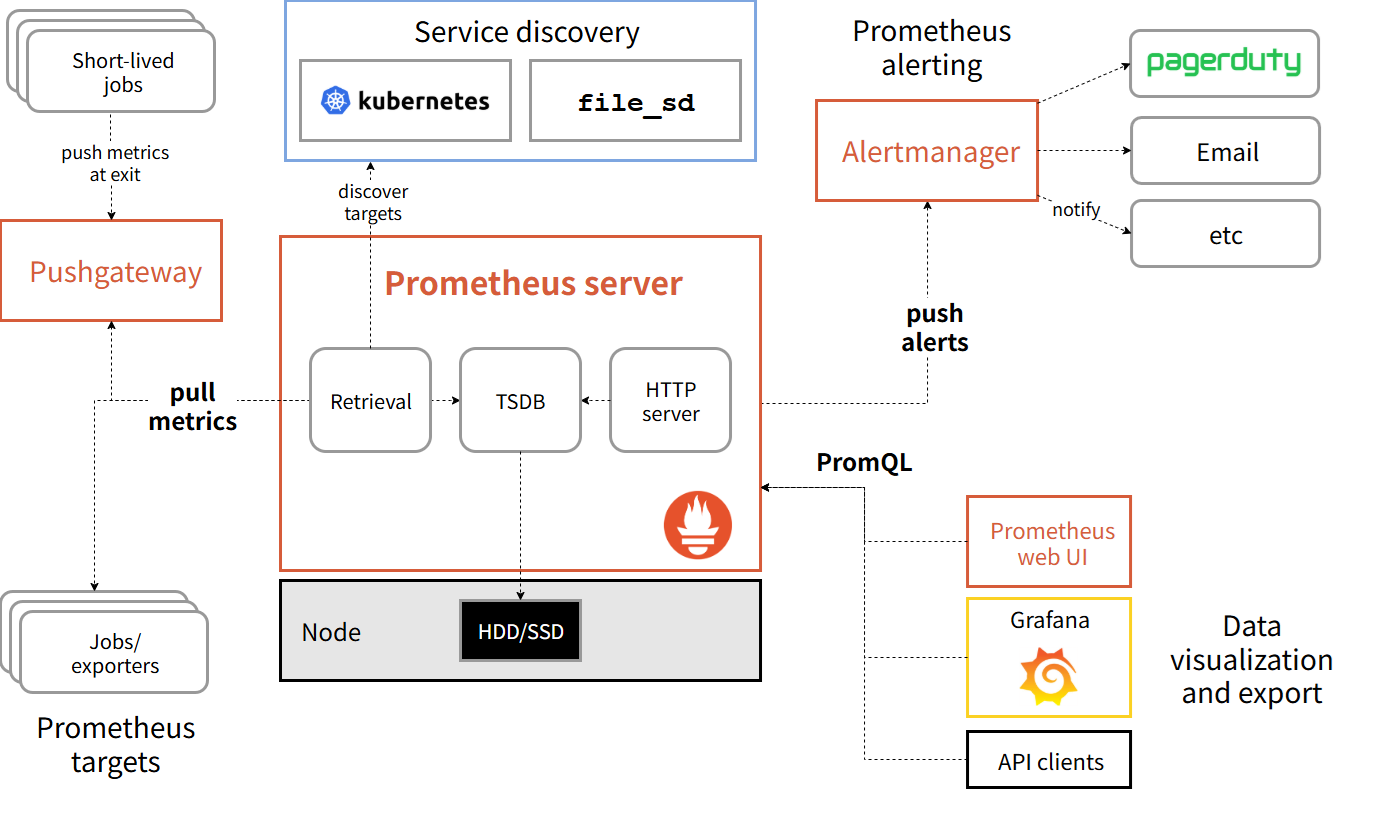
また、Prometheusなどの監視ツールに保存された時系列データをダッシュボードで可視化できるGrafanaというツールも存在します51。
先ほど紹介したIstioと同じく、Managed Service for PrometheusというマネージドなPrometheusがGoogle Cloudで提供されています52。Managed Service for Prometheus で紹介します。
マニフェスト管理と Helm、Kustomize
マニフェストをkubectlを使って個別に手動管理していると、Kubernetesの利用が拡大していったときに以下のような課題が出てきます。
- 環境ごとに手作業が必要で、管理が大変
- バージョン管理が大変
- 変更やレビュー、ロールバックなど、運用の負荷が高い
- 同じKubernetesクラスタの環境を他でも再利用したい
そういった文脈で出てくるツールがHelmとKustomizeです。
Helm
HelmはKubernetesのパッケージマネージャーです。「Chart」という形式でKubernetesアプリケーション (DeploymentやServiceなどのリソース) を再利用可能なパッケージとして扱い、クラスタへの導入・更新・ロールバックを容易にします。また、以下のようなシーンで、その配布・導入を担います。
- OSS / ベンダーが「このアプリをKubernetesに入れたい人」向けに配る
- 社内Platformチームが「社内標準のアプリ構成」を各チームに配る
- 同じアプリを設定違いで複数クラスタに展開する
「OSS / ベンダーが「このアプリをKubernetesに入れたい人」向けに配る」については、雑に表現するとJavaScriptのnpm install xx、Goのgo install xxの要領で、helm install xxするようなイメージです。実際はより複雑で、Helmで外部ツールを入れる場合、以下の手順を踏みます。
- Chart保管場所 (Repository) をローカルの設定ファイルに追加 (
helm repo add) - 追加したRepositoryから、Chart一覧やバージョン情報などを取得してローカルにキャッシュ (
helm repo update) - Chartを取得・展開し、クラスタの実体に反映 (
helm install)
例えば、先ほど紹介したサービスメッシュのツールであるIstioは以下のようにインストールして使用します53。(後ほどハンズオンの章でインストール手順含めで紹介するため、コマンド実行は不要です。あくまで手順のイメージの紹介と捉えてください)
# Istio の Repository URL をローカルの設定ファイルに追加
helm repo add istio https://istio-release.storage.googleapis.com/charts
# Istio の Repository から、Chart 一覧やバージョン情報などを取得してローカルにキャッシュ
helm repo updateローカルに追加されたそれぞれのファイルを簡単に見てみます。
- それぞれの場所を確認
helm env | grep -E 'HELM_REPOSITORY_(CONFIG|CACHE)'
# HELM_REPOSITORY_CACHE="/home/xxx/.cache/helm/repository"
# HELM_REPOSITORY_CONFIG="/home/xxx/.config/helm/repositories.yaml"helm repo add istio https://istio-release.storage.googleapis.com/chartsでIstioのRepositoryのURLを追加した設定ファイル
cat ~/.config/helm/repositories.yaml
# apiVersion: ""
# generated: "0001-01-01T00:00:00Z"
# repositories:
# - caFile: ""
# certFile: ""
# insecure_skip_tls_verify: false
# keyFile: ""
# name: istio
# pass_credentials_all: false
# password: ""
# url: https://istio-release.storage.googleapis.com/charts
# username: ""helm repo updateでローカルキャッシュした、IstioのRepositoryで配布されるChartの一覧やバージョン情報
$ head -n 40 ~/.cache/helm/repository/istio-index.yaml
# apiVersion: v1
# entries:
# ambient:
# - apiVersion: v2
# appVersion: 1.29.0
# created: "2026-02-16T18:39:04.801438006Z"
# dependencies:
# - name: base
# repository: file://../../charts/base
# version: 1.29.0
# - name: cni
# repository: file://../../charts/istio-cni
# version: 1.29.0
# - condition: istiod.enabled
# name: istiod
# repository: file://../../charts/istio-control/istio-discovery
# version: 1.29.0
# - name: ztunnel
# repository: file://../../charts/ztunnel
# version: 1.29.0
# description: Helm umbrella chart for ambient
# digest: <DIGEST>
# icon: https://istio.io/latest/favicons/android-192x192.png
# keywords:
# - istio-cni
# - istio
# - ambient
# kubeVersion: '>= 1.23.0-0'
# name: ambient
# sources:
# - https://github.com/istio/istio
# type: application
# urls:
# - https://istio-release.storage.googleapis.com/charts/samples/ambient-1.29.0.tgz
# version: 1.29.0
# - apiVersion: v2
# appVersion: 1.29.0-rc.3
# created: "2026-02-11T11:21:17.292156895Z"
# dependencies:
# - name: baseこれらのChartをクラスタにインストールします。
# クラスタにインストール
helm install istio-base istio/base --namespace istio-system --create-namespaceistio-base: インストール実体につける任意の管理名 (helm upgrade/delete/statusなどに使用する)istio/base: インストールするパッケージ名--namespace istio-system: インストール先のNamespace
Helmではこのような流れでパッケージを取得し、クラスタに適用していきます。
Kustomize
Kustomizeはマニフェストの差分を管理するKubernetesネイティブなツールで、kubectlからデフォルトで使用できます。Kustomizeは「完成済みの既存マニフェストに対してパッチを当てる」のようなニュアンスがあり、環境差を分離しやすくなります。例えば以下のようにして環境差を管理します。
kustomize/
├─ base/
│ ├─ deployment.yaml
│ └─ kustomization.yaml
└─ overlays/
└─ dev/
├─ kustomization.yaml
└─ patch-deployment.yaml
└─ stg/
├─ kustomization.yaml
└─ patch-deployment.yaml「完成済みの既存マニフェストに対してパッチを当てる」のようなニュアンスとお伝えしましたが、具体的には「base/が完成済みのマニフェスト、overlays/でパッチを当てる」という構成です。
例えば以下のbase/deployment.yamlはKustomize関係なくDeploymentのマニフェストとして成立しています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: app
image: ghcr.io/example/myapp:1.0.0
env:
- name: LOG_LEVEL
value: infobase/kustomization.yamlでbaseで扱うパッチ対象のマニフェストを宣言します。
resources:
- deployment.yamloverlays/dev/kustomization.yamlで、どのbaseを取り込むか、どのパッチを当てるかを宣言します。
resources:
- ../../base
patches:
- path: patch-deployment.yamlそしてoverlays/dev/patch-deployment.yamlでDeploymentに対する差分そのものを記述します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 1
template:
spec:
containers:
- name: app
image: ghcr.io/example/myapp:1.0.0-dev
env:
- name: LOG_LEVEL
value: debugこのようにして、既存の完成形マニフェストに対するアドオンで環境差異を管理できるのがKustomizeの特徴の1つです。
Helm と Kustomize は競合する存在ではなく、併用する
どちらのツールも「適用可能なKubernetesマニフェストを作る」という観点では役割が重複していて、例えば環境差異を管理するだけならどちらかを使えば良いです。(おそらく、それだけならKustomizeの方が学習コストも低く、手軽ではあります)
ただし先ほどもHelmの紹介でお伝えしたように、外部ツールの導入方法としてHelmは有力な選択肢で、配布・更新・ロールバックをまとめて扱いたい場面でよく使われます。つまり以下のような役割分担での併用が起き得るということです。
- Helm: アプリを配る / 入れる
- Kustomize: 同じ構成を環境ごとにズラす
マニフェスト管理の観点のみでの比較であれば、以下の記事がわかりやすかったです。
https://zenn.dev/yokoo_an209/articles/6d23ee506bc007
GitOps と Argo CD、Flux
GitOpsは、誤解を恐れず簡潔に表現すると、インフラのデプロイ方法についてのトピックです。根本として押さえておくべきなのは「Push型か、Pull型か」です。
- CIOps: CIツールがKubernetesクラスタ外部からPush型でデプロイする
- GitOps: Gitなどのバージョン管理システムをSource of Truth (SoT) として、クラスタ内部からPull型で同期、デプロイする
※CIOpsという言葉はGitOpsとの対比で使われることはありますが、OpenGitOps (CNCFのワーキンググループ54) や各ツールの公式ドキュメントで広く標準用語として扱われているわけではなさそうなので、本記事ではPush型CDを指す便宜的な表現として使います。
GitOpsは単に「Gitを使ってデプロイすること」ではなく、OpenGitOpsでは「宣言的に記述されたdesired stateをバージョン管理されたSoTに置き、ソフトウェアエージェントが自動的に取得して、実際の状態と継続的にreconcileする」という考え方として整理されています55。CNCF Glossary (CNCFが管理するクラウド技術に関する用語集) でも、GitOpsは「Gitなどのバージョン管理システムに定義されたdesired stateとactual stateを継続的に比較・調整するプラクティス」として説明されています。56
mainブランチへのマージや特定ブランチへのプッシュなど、git pushを起点としてGitHub Actionsなどのワークフローでクラスタのデプロイ (kubectl applyやhelm upgrade) まで実行されるCDは、Push型としてCIOpsに分類されます。CIOpsでは、CI実行基盤が本番クラスタを変更できる権限を持つことになります。GitHub ActionsのOIDCやGoogle CloudのWorkload Identity Federationを使えば長期鍵を置かずに認証できますが、発行元リポジトリやブランチなどの条件設定が広すぎると、意図しないワークフローから権限を使われるリスクがあります。5758
flowchart LR
Dev[開発者] -->|git push| Repo[Git Repository]
Repo -->|トリガー| CI[CI/CD]
CI -->|Pushで適用| Cluster[Kubernetes Cluster]
classDef default fill:transparent,stroke:#6b7280
GitOpsは、Kubernetesクラスタ (正確にはその内部で動くcontroller) がリポジトリの変更をPullします。そのため、デプロイに必要な権限をクラスタ外部のCI基盤から分離できます。
flowchart LR
Dev[開発者] -->|git push| Repo[Git Repository]
Cluster[Kubernetes Cluster] -->|Pullで同期| Repo
Controller[GitOps Controller] --- Cluster
classDef default fill:transparent,stroke:#6b7280
また、GitHub Actionsのワークフローなどによる標準的なCD (=CIOps) では、このワークフロー以外から適用された変更のドリフト検知 / 自動修復は、デプロイを担うワークフローの標準的な責務には含まれません。例えばクラスタに対する直接のkubectl applyによる変更は、基本的に次のデプロイまで検知・修正されないということです。GitOpsでは、KubernetesのReconciliation Loopの考え方を取り入れ、Gitなどに置かれたdesired stateと実クラスタとの差分をcontrollerが継続的に確認し、同期します。(同期は必ずしも自動とは限らず、場合によっては手動にしておくこともあります)
GitOpsを推すようなことばかり書いてしまいましたが、CIOpsはデプロイ手順の柔軟性や、Kubernetesを含めたデプロイフローを1つのCI/CDで管理できる点など、シンプルさでは優位です。そのため、環境やクラスタ、サービスの増加で差分管理がツラくなってきたタイミングや、組織としてアプリとインフラ / プラットフォーム / SREなどでチームが分かれるタイミングで検討すると良さそうだと感じました。
Kubernetes環境でGitOpsを実現するツールとしての有名どころがArgo CDとFluxです。(Spinnakerというツールもありますが、これはKubernetes特化ではありません)
マニフェストへの制約と Gatekeeper、Kyverno
Kubernetesの設定はマニフェストの記述によって行われます。つまり、クラスタに適用されるマニフェストの内容に制約を設けることは、セキュリティやガバナンスにおける重要な一側面です。前提として、Kubernetesクラスタに対するCREATEやUPDATE系の変更が適用されるまでには以下のような流れをたどります。59
- kube-apiserverでAPIリクエストを受ける
- 認証 / 認可
- 事前設定したルールに基づきオブジェクトを変更
- オブジェクトとAPIスキーマの一致 (Kubernetesのオブジェクトとして正しいか) を検証
- 事前設定したルールに基づきオブジェクトを検証
- 上記すべてが通過した場合のみetcdに保存
- APIレスポンス
図で表現すると以下の通りです。(未解説の単語を多数出していますが、話の筋には影響しないのでひとまず割愛します)
flowchart TD
A[API リクエスト] --> B[認証]
B --> C["認可<br/>(RBAC etc.)"]
C --> D["オブジェクト変更<br/>(LimitRangeなどbuilt-inのもの)"]
D --> DQ{"変更webhookが設定されていて条件と一致するか"}
DQ -->|Yes| DW["変更Webhook(s)の呼び出し<br/>(例: Gatekeeper/Kyverno)"]
DQ -->|No| E
DW --> E["オブジェクトスキーマ検証<br/>(組み込みOpenAPI/CRDスキーマ)"]
E --> V["オブジェクト検証<br/>(LimitRanger/PSA/VAPなどbuilt-inのもの)"]
V --> VQ{"オブジェクト検証 webhookが設定されていて条件と一致するか"}
VQ -->|Yes| VW["検証webhook(s)の呼び出し<br/>(例: Gatekeeper/Kyverno)"]
VQ -->|No| F
VW --> F["etcdに永続化<br/>(すべて成功した場合のみ)"]
F --> G[API レスポンス]
classDef default fill:transparent,stroke:#6b7280
※後ほど紹介するツールであるGatekeeperはv3.10から変更 (Mutation) もstableに昇格しており60、実運用では検証 (Validating) が中心と考えられますがMutatingのところにも記載しています。
以上の流れを簡単にまとめると、Kubernetesクラスタに変更が適用される (etcdに保存される) までには、ルールに基づいてマニフェストの変更 (Mutating) と検証 (Validating) が実施できるので、意図せぬ変更が適用されないように、その2フェーズで制約を設けましょうということです。例えば、以下のようなシーンでマニフェストへの制約を加えたくなります。
- 特定Namespaceのリソースには特定のラベルを必須で付与したいが、手動だと漏れがあるので自動化したい
- 信頼できる特定のコンテナレジストリのみ使用できるようにしたい
- 機密データを扱う特定Namespaceでは、特定グループに属する開発者のみPodの作成や更新、コンテナへの接続ができるようにしたい
- Ingressのホスト名が他のチームと重複していたら作成を拒否したい
- 特権モードで動作するコンテナを作成できないようにしたい
これらはKubernetesのbuilt-in機能 (LimitRange61 やPSA62、VAP63 など) で対応できるものもありますが、できないものもあります。そういった場合に外部ツールを使います。その有名どころがGatekeeperやKyvernoといったツールです。
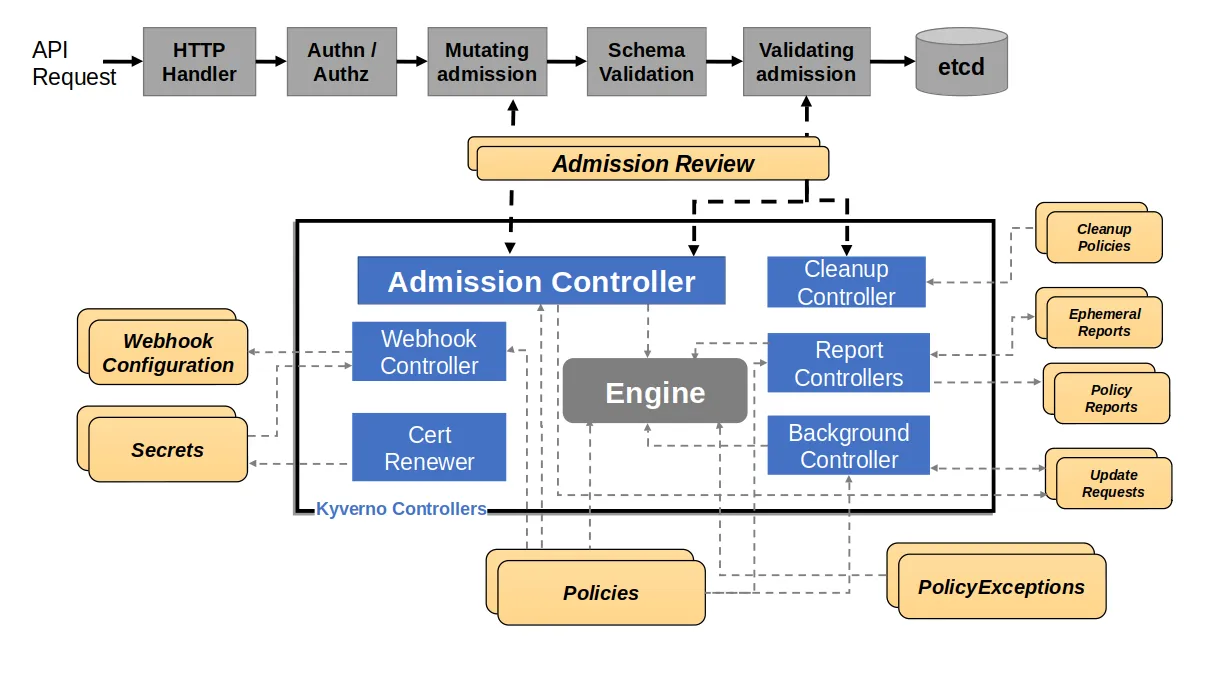
こういったツールはクラスタ内部にWebhookのサーバーを立て、オブジェクト変更や検証のタイミングでクラスタから呼び出すように設定して使います。例えば以下は、Kyvernoのアーキテクチャです。
ここまで、サービスメッシュ (Istio / Cloud Service Mesh / Envoy)、監視 (Prometheus / Grafana / Managed Service for Prometheus)、マニフェスト管理 (Helm / Kustomize)、GitOps (Flux / Argo CD)、マニフェストへの制約 (Admission Controller / Gatekeeper / Kyverno) の5つの領域を概観してきました。次の章では、これらをkind上で実際にHelm ⇒ Istio ⇒ Prometheus ⇒ Kustomize ⇒ Flux ⇒ Gatekeeperの順に導入・動作確認していきます。
Helm/Istio/Prometheus/Kustomize/Gatekeeper/Flux を kind で動かす
先ほど紹介してきた各種ツールをkindでローカルで試していきましょう。ローカルで触る Kubernetesで作成・使用してきたクラスタや各種リソースをそのまま使っていきます。
前提
各種ツールのインストール
この章では、前半で導入済みのDocker、kind、kubectlに加えて、以下のツールを使用します。
- helm: Helm Chartの取得とインストールに使用
- flux: Fluxのbootstrapや同期状態の確認に使用
- istioctl: Istioの状態確認に使用
インストール方法は色々ありますが、ここでは公式ドキュメントに沿った方法で進めます。646566
Helm
Helmは公式インストールスクリプトを使います。
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-4
chmod 700 get_helm.sh
./get_helm.shFlux CLI
Flux CLIは公式インストーラを使います。
curl -s https://fluxcd.io/install.sh | sudo bashistioctl
istioctlは公式のインストールスクリプトを使います。この記事では後続の手順でIstio 1.29.0を使うため、ここでもそのバージョンを揃えておきます。なお、シェルがBashである前提で~/.bashrcを更新しています。
ISTIO_VERSION=1.29.0
curl -sL https://istio.io/downloadIstioctl | ISTIO_VERSION=${ISTIO_VERSION} sh -
# istioctl が `$HOME/.istioctl/bin` 配下に展開されていることを確認
ls $HOME/.istioctl/bin
grep -qxF 'export PATH="$HOME/.istioctl/bin:$PATH"' ~/.bashrc || \
echo 'export PATH="$HOME/.istioctl/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcツールのバージョン
- 以下バージョンがこの章の前提です。
kubectl version --client
# Client Version: v1.35.1
# Kustomize Version: v5.7.1
kind version
# kind v0.31.0 go1.25.5 linux/amd64
docker version --format '{{.Client.Version}}'
# 28.4.0
helm version
# version.BuildInfo{Version:"v4.1.1", GitCommit:"<GIT_COMMIT>", GitTreeState:"clean", GoVersion:"go1.25.7", KubeClientVersion:"v1.35"}
flux --version
# flux version 2.8.3
istioctl version --remote=false
# client version: 1.29.0クラスタの状態
- 以下の状態がこの章の前提です。
kubectl get deployment,service,pod
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/echo 2/2 2 2 xh
# deployment.apps/nginx 2/2 2 2 xh
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/echo ClusterIP 10.96.27.137 <none> 80/TCP xh
# service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP xh
# service/nginx ClusterIP 10.96.120.128 <none> 80/TCP xh
# NAME READY STATUS RESTARTS AGE
# pod/echo-dddddddddd-ccccc 1/1 Running 0 xh
# pod/echo-dddddddddd-ddddd 1/1 Running 0 xh
# pod/nginx-aaaaaaaaaa-ccccc 1/1 Running 0 xh
# pod/nginx-aaaaaaaaaa-ddddd 1/1 Running 0 xhIstio によるサービスメッシュ
途中から始めたい方は、サンプルリポジトリ
zenn-k8s-handsonをcloneしてmake ckpt-10を実行すると、この章のクラスタ前提状態 (kindクラスタ +nginx/echoのDeployment / Service) を再現できます。なお、この章で使うCLI (helm / flux / istioctl) は本章冒頭の前提節を先に確認してインストールしてください。
まず、おさらいです。
- サービスメッシュはマイクロサービス間の通信制御を、アプリケーション自身ではなくインフラ側で横断的に担うレイヤー
- 通信を担うコンテナ (=サイドカー) をPodに追加し、ネットワークトラフィックをインターセプトする方法が代表的
- サイドカーはトラフィックの管理 / 分散、暗号化、認証、モニタリング、ロギングなど、様々な機能を提供する
この章ではIstioでサービスメッシュを導入して「トラフィックの管理 / 分散」をピックアップして紹介します。
istio-base / istiod を Helm でクラスタに導入する
まずHelmを用いてIstioをクラスタに反映していきます。これもおさらいですが、HelmはKubernetesのパッケージマネージャーです。Chartという形式でKubernetesアプリケーションを再利用可能なパッケージとして扱い、クラスタへの導入・更新・ロールバックを容易にします。また、以下の手順でクラスタに反映します。(詳しくはマニフェスト管理と Helm、Kustomizeの章を確認してください)
- Chart保管場所 (Repository) をローカルの設定ファイルに追加
- 追加したRepositoryから、Chart一覧やバージョン情報などを取得してローカルにキャッシュ
- Chartを取得・展開し、クラスタの実体に反映
ではさっそくIstioをクラスタに反映していきます。
# Istio の Repository URL をローカルの設定ファイルに追加
helm repo add istio https://istio-release.storage.googleapis.com/charts
# Istio の Repository から、Chart 一覧やバージョン情報などを取得してローカルにキャッシュ
helm repo update
# ローカルにキャッシュされた Istio のバージョン確認
helm search repo istio/istiod --versions | head -n 5
# NAME CHART VERSION APP VERSION DESCRIPTION
# istio/istiod 1.29.0 1.29.0 Helm chart for istio control plane
# istio/istiod 1.28.4 1.28.4 Helm chart for istio control plane
# istio/istiod 1.28.3 1.28.3 Helm chart for istio control plane
# istio/istiod 1.28.2 1.28.2 Helm chart for istio control plane再現性を担保するため、バージョンを固定しておきます。
ISTIO_VERSION=1.29.0まずはIstioの基盤となるistio/baseというChartをupgrade --installコマンドでクラスタに反映します。upgrade --installはクラスタに既にChartが存在すれば更新、なければ新規作成するコマンドです。
# istio-system という Namespace を新規作成して Chart を反映
helm upgrade --install istio-base istio/base \
-n istio-system --create-namespace \
--set defaultRevision=default \
--version ${ISTIO_VERSION} --wait
# Release "istio-base" does not exist. Installing it now.
# NAME: istio-base
# LAST DEPLOYED: <DATETIME>
# NAMESPACE: istio-system
# STATUS: deployed
# REVISION: 1
# DESCRIPTION: Install complete
# TEST SUITE: None
# NOTES:
# Istio base successfully installed!
# To learn more about the release, try:
# $ helm status istio-base -n istio-system
# $ helm get all istio-base -n istio-systemこういった外部パッケージを使用する際などに出てくるのがCustom Resource Definition (CRD) で、これはKubernetes APIに新しいリソースの型を追加する仕組みです。例えば、DeploymentやServiceなど、ローカルで触る Kubernetesで紹介してきたリソースはKubernetes組み込みですが、それ以外のリソースを追加したい場合に使用されます。(実はGateway を作るで紹介したGatewayも組み込みではなくカスタムリソースです)
istio/baseで追加したCRDは、後ほど紹介しますがVirtualService、DestinationRule、Gatewayなどです。これらを先に追加しておかないと、実体のインストールができません。
次に、istiodというコントロールプレーンを追加します。
helm upgrade --install istiod istio/istiod \
-n istio-system \
--version ${ISTIO_VERSION} \
--wait
# Release "istiod" does not exist. Installing it now.
# NAME: istiod
# LAST DEPLOYED: <DATETIME>
# NAMESPACE: istio-system
# STATUS: deployed
# REVISION: 1
# DESCRIPTION: Install complete
# TEST SUITE: None
# NOTES:
# "istiod" successfully installed!
# To learn more about the release, try:
# $ helm status istiod -n istio-system
# $ helm get all istiod -n istio-system
# Next steps:
# * Deploy a Gateway: https://istio.io/latest/docs/setup/additional-setup/gateway/
# * Try out our tasks to get started on common configurations:
# * https://istio.io/latest/docs/tasks/traffic-management
# * https://istio.io/latest/docs/tasks/security/
# * https://istio.io/latest/docs/tasks/policy-enforcement/
# * Review the list of actively supported releases, CVE publications and our hardening guide:
# * https://istio.io/latest/docs/releases/supported-releases/
# * https://istio.io/latest/news/security/
# * https://istio.io/latest/docs/ops/best-practices/security/
# For further documentation see https://istio.io website上記コマンドで、以下画像におけるコントロールプレーンのistiodを追加したということです。(istiodについては後ほど簡単に説明します)
コントロールプレーンのPodが存在しているか確認します。
kubectl get pod -n istio-system
# NAME READY STATUS RESTARTS AGE
# istiod-gggggggggg-aaaaa 1/1 Running 0 xmistiod-...という名前のPodが確認できました。
サイドカー注入を有効化して既存 Pod を更新する
次に、defaultのNamespaceに作成されるPodにIstioのサイドカーコンテナが自動で注入 (Istio公式でInjectionという表現が使われています) されるようにistio-injection=enabledというラベルを付けます。67
kubectl label namespace default istio-injection=enabled --overwrite
# namespace/default labeled既存のPodには自動でサイドカーが注入されないため、再作成します。
kubectl rollout restart deployment/echo deployment/nginx -n default
kubectl rollout status deployment/echo -n default
kubectl rollout status deployment/nginx -n default
# deployment.apps/echo restarted
# deployment.apps/nginx restarted
# Waiting for deployment "echo" rollout to finish: 1 out of 2 new replicas have been updated...
# Waiting for deployment "echo" rollout to finish: 1 out of 2 new replicas have been updated...
# Waiting for deployment "echo" rollout to finish: 1 out of 2 new replicas have been updated...
# Waiting for deployment "echo" rollout to finish: 1 old replicas are pending termination...
# Waiting for deployment "echo" rollout to finish: 1 old replicas are pending termination...
# deployment "echo" successfully rolled out
# Waiting for deployment "nginx" rollout to finish: 1 old replicas are pending termination...
# Waiting for deployment "nginx" rollout to finish: 1 old replicas are pending termination...
# deployment "nginx" successfully rolled outPodにサイドカーが注入されたか確認します。
kubectl get pod -n default -l app=echo \
-o jsonpath='{range .items[*]}{.metadata.name}{" => init:"}{.spec.initContainers[*].name}{" / app:"}{.spec.containers[*].name}{"\n"}{end}'
kubectl get pod -n default -l app=nginx \
-o jsonpath='{range .items[*]}{.metadata.name}{" => init:"}{.spec.initContainers[*].name}{" / app:"}{.spec.containers[*].name}{"\n"}{end}'
# echo-eeeeeeeeee-aaaaa => init:istio-init istio-proxy / app:echo
# echo-eeeeeeeeee-bbbbb => init:istio-init istio-proxy / app:echo
# nginx-ffffffffff-aaaaa => init:istio-init istio-proxy / app:nginx
# nginx-ffffffffff-bbbbb => init:istio-init istio-proxy / app:nginxistio-proxyというコンテナがそれぞれのPodに存在することが確認できました。これが注入されたサイドカーです。※今回の環境ではistio-proxyはinitContainersとして確認できましたが、クラスタによってはcontainers側に表示される場合もあります。差異がある場合はkubectl describe pod -l app=echoなどで確認してください。
istioctl と xDS でメッシュの状態を確認する
IstioのCLIツールであるistioctlでメッシュ全体の状況を確認します。未インストールの場合は、この章の前提を先に実施してください。
istioctl proxy-status
# NAME CLUSTER ISTIOD VERSION SUBSCRIBED TYPES
# echo-eeeeeeeeee-aaaaa.default Kubernetes istiod-gggggggggg-aaaaa 1.29.0 4 (CDS,LDS,EDS,RDS)
# echo-eeeeeeeeee-bbbbb.default Kubernetes istiod-gggggggggg-aaaaa 1.29.0 4 (CDS,LDS,EDS,RDS)
# nginx-ffffffffff-aaaaa.default Kubernetes istiod-gggggggggg-aaaaa 1.29.0 4 (CDS,LDS,EDS,RDS)
# nginx-ffffffffff-bbbbb.default Kubernetes istiod-gggggggggg-aaaaa 1.29.0 4 (CDS,LDS,EDS,RDS)これは、echo、nginxのサイドカーがistiod-gggggggggg-aaaaaという名前のistiodに接続していて、4種類のxDSリソース (CDS、LDS、EDS、RDS) を購読していることを表しています。
xDSは、istiodが各サイドカーにいるEnvoyに設定を配るための制御用API群の総称で、「どの宛先に流すか」「どのリスナー / ルート / エンドポイントを使うか」をEnvoyに配ります。上記で見えていたのは以下です。(xDSのDSはDiscovery Serviceの略です68)
- CDS: Cluster Discovery Service
- LDS: Listener Discovery Service
- EDS: Endpoint Discovery Service
- RDS: Route Discovery Service
istiodはこれらの制御用APIを用いてServiceやPod、Istioのカスタムリソース (VirtualService、DestinationRule、Gateway) などをwatchします。そしてEnvoyが理解できるxDSの設定に変換したうえで各Proxyに配ったり、mTLS用の証明書を配ったりを担当しています69。詳細は割愛しますが、kubectl logs -n istio-system deployment/istiod --tail=30などのコマンドでistiodのログが出力できます。
Ingress Gateway と VirtualService で外部公開する
次に、外部からのアクセス用にGatewayを作ります。Gateway を作るではGateway、GatewayClass、HTTPRouteを作りましたが、前述のようにIstioでは専用のAPIが存在します。役割としては似ているため、そこまで詳細に解説しません。まずはGateway関連のChartを適用します。
helm upgrade --install istio-ingressgateway istio/gateway \
-n istio-ingress --create-namespace \
--version ${ISTIO_VERSION}
# Release "istio-ingressgateway" does not exist. Installing it now.
# NAME: istio-ingressgateway
# LAST DEPLOYED: <DATETIME>
# NAMESPACE: istio-ingress
# STATUS: deployed
# REVISION: 1
# DESCRIPTION: Install complete
# TEST SUITE: None
# NOTES:
# "istio-ingressgateway" successfully installed!
# To learn more about the release, try:
# $ helm status istio-ingressgateway -n istio-ingress
# $ helm get all istio-ingressgateway -n istio-ingress
# Next steps:
# * Deploy an HTTP Gateway: https://istio.io/latest/docs/tasks/traffic-management/ingress/ingress-control/
# * Deploy an HTTPS Gateway: https://istio.io/latest/docs/tasks/traffic-management/ingress/secure-ingress/以下のDeployment、Service、Podが作成されます。
kubectl get deployment,service,pod -n istio-ingress
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/istio-ingressgateway 1/1 1 1 xm
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/istio-ingressgateway LoadBalancer 10.96.110.245 <pending> 15021:30896/TCP,80:31151/TCP,443:32709/TCP xm
# NAME READY STATUS RESTARTS AGE
# pod/istio-ingressgateway-hhhhhhhhh-aaaaa 1/1 Running 0 xm次にGatewayとVirtualServiceのリソースを作ります。Gatewayは通信を受けるポートと扱うホストの定義70、VirtualServiceは入ってきたリクエストをどこに流すかのルール71です。上記Chartで適用したのがDeploymentなどの実体であり、その設定やルールを定義するイメージです。
cat > gateway-basic.yaml <<'EOF'
apiVersion: networking.istio.io/v1
kind: Gateway
metadata:
name: web-gateway
namespace: default
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: web-route
namespace: default
spec:
hosts:
- "*"
gateways:
- web-gateway
http:
- match:
- uri:
prefix: /nginx
rewrite:
uri: /
route:
- destination:
host: nginx.default.svc.cluster.local
port:
number: 80
- match:
- uri:
prefix: /echo
rewrite:
uri: /
route:
- destination:
host: echo.default.svc.cluster.local
port:
number: 80
EOFクラスタに適用します。
kubectl apply -f gateway-basic.yaml
# gateway.networking.istio.io/web-gateway created
# virtualservice.networking.istio.io/web-route created外部から叩けるか確認してみましょう。
kubectl -n istio-ingress port-forward service/istio-ingressgateway 18080:80
# Forwarding from 127.0.0.1:18080 -> 80
# Forwarding from [::1]:18080 -> 80別ターミナルから以下を実行して、中身が見えることを確認します。
curl -s http://localhost:18080/nginx | head
curl -s http://localhost:18080/echo | head改めてメッシュの状態を確認してみます。
istioctl proxy-status
# NAME CLUSTER ISTIOD VERSION SUBSCRIBED TYPES
# echo-eeeeeeeeee-aaaaa.default Kubernetes istiod-gggggggggg-aaaaa 1.29.0 4 (CDS,LDS,EDS,RDS)
# echo-eeeeeeeeee-bbbbb.default Kubernetes istiod-gggggggggg-aaaaa 1.29.0 4 (CDS,LDS,EDS,RDS)
# istio-ingressgateway-hhhhhhhhh-aaaaa.istio-ingress Kubernetes istiod-gggggggggg-aaaaa 1.29.0 4 (CDS,LDS,EDS,RDS)
# nginx-ffffffffff-aaaaa.default Kubernetes istiod-gggggggggg-aaaaa 1.29.0 4 (CDS,LDS,EDS,RDS)
# nginx-ffffffffff-bbbbb.default Kubernetes istiod-gggggggggg-aaaaa 1.29.0 4 (CDS,LDS,EDS,RDS)先ほどistio/gatewayで追加したPod (istio-ingressgateway-...) もIstioに認識されていることがわかります。
DestinationRule と subset で重み付きルーティングする
次にDestinationRuleというリソースを追加して、重み付きのルーティングを設定してみます。今回はversionがv1とv2のDeploymentを作り、v1に90%、v2に10% というルールのルーティングを試します。説明のわかりやすさのため、Gateway以外の一式を新規で作ります。
cat > echo-split.yaml <<'EOF'
apiVersion: v1
kind: Service
metadata:
name: echo-split
namespace: default
spec:
type: ClusterIP
selector:
app: echo-split
ports:
- name: http
port: 80
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-split-v1
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: echo-split
version: v1
template:
metadata:
labels:
app: echo-split
version: v1
spec:
containers:
- name: echo
image: hashicorp/http-echo:1.0.0
args: ["-listen=:8080", "-text=v1"]
ports:
- containerPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-split-v2
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: echo-split
version: v2
template:
metadata:
labels:
app: echo-split
version: v2
spec:
containers:
- name: echo
image: hashicorp/http-echo:1.0.0
args: ["-listen=:8080", "-text=v2"]
ports:
- containerPort: 8080
---
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: echo-split
namespace: default
spec:
host: echo-split.default.svc.cluster.local
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
---
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: echo-split-mesh
namespace: default
spec:
hosts:
- echo-split
- echo-split.default.svc.cluster.local
http:
- route:
- destination:
host: echo-split.default.svc.cluster.local
subset: v1
port:
number: 80
weight: 90
- destination:
host: echo-split.default.svc.cluster.local
subset: v2
port:
number: 80
weight: 10
---
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: echo-split-gateway
namespace: default
spec:
hosts:
- "*"
gateways:
- web-gateway
http:
- match:
- uri:
prefix: /split
route:
- destination:
host: echo-split.default.svc.cluster.local
subset: v1
port:
number: 80
weight: 90
- destination:
host: echo-split.default.svc.cluster.local
subset: v2
port:
number: 80
weight: 10
EOFDestinationRuleは「特定の宛先Serviceに対して、どう接続するか」を定義するリソースです72。VirtualServiceが「どこへ流すか」を決めるのに対しDestinationRuleは「その宛先の中身をどう扱うか」を決めるイメージです。今回の例で具体的にすると以下です。
- DestinationRule:
echo-splitというhostの中にversion=v1とversion=v2のsubsetがあると定義する - VirtualService: DestinationRuleの設定をもとに
echo-splitServiceへの通信をversion=v1に90、version=v2には10というルールで振り分けると定義する
DestinationRuleでは、1つのhost配下にあるエンドポイント群 (≠ Pod群) を、ラベルで分類された「名前付きの部分集合」としてsubsetと呼びます。hostが「どのサービスか」、subsetが「そのサービスの中のどのバージョンか」です。例えば今回はhost: echo-split.default.svc.cluster.localに対して、version=v1なPod群をsubset: v1、version=v2なPod群をsubset: v2と名付けています。
では上記のマニフェストを適用します。
kubectl apply -f echo-split.yaml
# service/echo-split created
# deployment.apps/echo-split-v1 created
# deployment.apps/echo-split-v2 created
# destinationrule.networking.istio.io/echo-split created
# virtualservice.networking.istio.io/echo-split-mesh created
# virtualservice.networking.istio.io/echo-split-gateway createdVirtualServiceを2つ作っていますが、これはメッシュ内部とクラスタ外部、それぞれからのルーティングを設定しているためです。というのも今回作っている環境には、大きく分けて以下の2系統のEnvoyが存在しています。
- 各Podにつくサイドカー用
- クラスタ外部からのリクエストを最初に受けるIngress Gateway用
IstioではVirtualServiceのgatewaysフィールドで「このルーティングルールをどのEnvoyに適用するか」を切り替えます。gatewaysを省略したecho-split-meshのVirtualServiceはメッシュ内のサイドカーに適用され、gateways: ["web-gateway"]を指定したecho-split-gatewayの方はIngress Gateway (istio/gatewayで追加されたService / Deployment / Podの一式) に適用されます。つまり、以下2つのルールということです。
- メッシュ内から
echo-splitを呼ぶためのルール - クラスタ外部から
/splitを呼ぶためのルール
...
---
# gateways 未指定のメッシュ内用ルール
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: echo-split-mesh
namespace: default
spec:
hosts:
- echo-split
- echo-split.default.svc.cluster.local
...
---
# gateways を指定した外部用ルール
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: echo-split-gateway
namespace: default
spec:
hosts:
- "*"
gateways:
- web-gateway
http:
- match:
- uri:
prefix: /split
...なお、技術的には1つのVirtualServiceにmeshとweb-gatewayの両方を書いてまとめることもできますが、説明用として「内部通信用のルール」と「入口用のルール」の違いをわかりやすくするため、あえて2つに分けました。
ではこのルーティングが適用されているか確認してみましょう。まずはメッシュ内から叩くための一時的なクライアントPodを作ります。
kubectl run curl -n default \
--image=curlimages/curl:8.7.1 \
--restart=Never \
--command -- sleep 3600クライアントPodが使える状態か確認します。
# pod/curl condition met が返ってくれば OK
kubectl wait --for=condition=Ready pod/curl -n default --timeout=120s作成したクライアントPodからメッシュ内通信を確認します。
for i in $(seq 1 20); do
kubectl exec -n default curl -- curl -s http://echo-split
done | sort | uniq -c
# 18 v1
# 2 v2次にIngress Gateway経由の確認です。(kubectl -n istio-ingress port-forward service/istio-ingressgateway 18080:80未実行の場合は再度実行してください)
for i in $(seq 1 20); do
curl -s http://localhost:18080/split
done | sort | uniq -c
# 19 v1
# 1 v2数字は実行のたびに変わりますが、おおむね9:1でルーティングされていることが確認できました。
検証用に作成した一時的なクライアントPodは不要なので削除しておきます。
kubectl delete pod curl -n defaultこの章で作った構成のまとめ
この章ではIstioを導入し、「トラフィックの管理 / 分散」にフォーカスしてサービスメッシュを実装してみました。図で視覚的に表すと、最終的に以下の状態になっています。(nginx-...のPodの部分などを一部省略しています)
flowchart TD
EXT["Client"] --> IGSVC
subgraph CLUSTER["Kubernetes Cluster"]
subgraph NS_ISTIO_SYSTEM["Namespace: istio-system"]
ISTIOD["Pod: istiod-*"]
end
subgraph NS_ISTIO_INGRESS["Namespace: istio-ingress"]
IGSVC["Service: istio-ingressgateway"]
IGPOD["Pod: istio-ingressgateway-*<br/>Envoy"]
IGSVC --> IGPOD
end
subgraph NS_DEFAULT["Namespace: default"]
GW["Gateway: web-gateway"]
VSWEB["VirtualService: web-route"]
VSGW["VirtualService: echo-split-gateway"]
VSMESH["VirtualService: echo-split-mesh"]
DR["DestinationRule: echo-split<br/>subsets: v1 / v2"]
APPSVC["Service: nginx / echo"]
SPLITSVC["Service: echo-split"]
APPPODS["Pod 群: nginx-* / echo-*<br/>app + istio-proxy"]
V1POD["Pod: echo-split-v1-*<br/>app + istio-proxy"]
V2POD["Pod: echo-split-v2-*<br/>app + istio-proxy"]
APPSVC --> APPPODS
SPLITSVC --> V1POD
SPLITSVC --> V2POD
end
GW -. "selector: istio=ingressgateway" .-> IGPOD
VSWEB -. "gateways: web-gateway" .-> GW
VSGW -. "gateways: web-gateway" .-> GW
IGPOD -->|/nginx, /echo| VSWEB
IGPOD -->|/split| VSGW
VSWEB --> APPSVC
VSGW -->|90 / 10| SPLITSVC
APPPODS -->|mesh 内通信| VSMESH
VSMESH -->|90 / 10| SPLITSVC
DR -. "v1 / v2 subset" .-> SPLITSVC
ISTIOD -. "xDS / 証明書配布" .-> IGPOD
ISTIOD -. "xDS / 証明書配布" .-> APPPODS
ISTIOD -. "xDS / 証明書配布" .-> V1POD
ISTIOD -. "xDS / 証明書配布" .-> V2POD
end
classDef default fill:transparent,stroke:#6b7280
style CLUSTER fill:transparent,stroke:#6b7280
style NS_ISTIO_SYSTEM fill:transparent,stroke:#6b7280
style NS_ISTIO_INGRESS fill:transparent,stroke:#6b7280
style NS_DEFAULT fill:transparent,stroke:#6b7280
Prometheus での監視
途中から始めたい方は、サンプルリポジトリ
zenn-k8s-handsonをcloneしてmake ckpt-20を実行すると、この節の前提状態 (Istio一式 + Gateway / VirtualService / DestinationRule +echo-splitv1/v2まで導入済み) を再現できます。
前の章ではIstioのVirtualServiceとDestinationRuleを使って、echo-splitへの通信をv1に90%、v2に10% で振り分けました。ここでは、その「通信が制御できていること」をレスポンスの見た目だけでなく、メトリクスでも確認してみます。
Prometheusは、監視対象から定期的にメトリクスを取得して保存するPull型の監視ツールです。Kubernetesと組み合わせると、いま存在しているPodやServiceを自動で見つけながらメトリクスを収集できます。
今回は学習用として、Istio公式が配布しているPrometheusのサンプル構成をそのまま使います。(これはデモ用途の最小構成であり、本番運用向けではないです73)
Prometheus を導入してターゲットを確認する
まずはPrometheusをクラスタに反映します。
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.29/samples/addons/prometheus.yaml
# serviceaccount/prometheus created
# configmap/prometheus created
# clusterrole.rbac.authorization.k8s.io/prometheus created
# clusterrolebinding.rbac.authorization.k8s.io/prometheus created
# service/prometheus created
# deployment.apps/prometheus created作成されたPodを確認してみます。(必要に応じてkubectl rollout status deployment/prometheus -n istio-systemで反映を待ってください)
kubectl get pod -n istio-system
# NAME READY STATUS RESTARTS AGE
# istiod-gggggggggg-aaaaa 1/1 Running 0 xh
# prometheus-iiiiiiiiii-aaaaa 2/2 Running 0 xsprometheus-...というPodが1つ起動し、その中にコンテナが2つあることが確認できました。ローカルから画面を確認できるようにポートフォワードします。
kubectl -n istio-system port-forward service/prometheus 9090:9090
# Forwarding from 127.0.0.1:9090 -> 9090
# Forwarding from [::1]:9090 -> 9090ブラウザでhttp://localhost:9090を開いてください。以下のような画面が表示されれば問題ありません。これがPrometheusの画面です。
 Prometheus のトップ画面
Prometheus のトップ画面
Prometheusの画面では監視対象のステータスや収集しているメトリクスの一覧が確認できます。まずは画面上部のタブからStatus > Target Healthを確認します。(Target = 監視対象です)
 Target Health の画面
Target Health の画面
この画面ではkube-apiserverやノード、Podなど、Prometheusが監視している各種ターゲットのエンドポイントが一覧表示されます。簡単に解説すると、表示されている情報は以下のような意味を持っています。
Endpoint: 対象のエンドポイントLabels: スクレイプ対象のラベルLast scrape: 最終スクレイプ時刻や、スクレイプにかかった時間などState: ステータス (UPかDOWN)
※Prometheusにおいて「スクレイプ」という言葉は、各サービスからメトリクスをPullすることを表現します。
kubernetes-podsでPrometheusが監視対象としているPodの一覧が確認できます。Labelsを見てみると、app="echo-split"やapp=echo、下の方までいくとapp=istiodなど、これまで作ってきたPodの名前が存在することがわかります。StateがUPになっていれば、監視対象を見つけて正常にスクレイプできているという状態です。
サービスディスカバリで監視対象が決まる仕組み
先に結論を書くと、Prometheusはkube-apiserverにPodなど各種リソースの情報を問い合わせ、その結果をrelabel_configsでフィルタリングして残ったものを監視対象として保存しています。以下では、この流れをConfigMapの中身から具体的に見ていきます。
Prometheusは監視対象を以下のように把握して、情報を保存します。(初出の言葉は追って解説します)
- ConfigMapに記述された
kubernetes_sd_configsに基づき、kube-apiserverに対して対象リソースの情報を問い合わせ - kube-apiserverから取得した情報に対し、
relabel_configsの条件を適用し、実際に監視する対象をフィルタリング - 監視対象のエンドポイントに対してHTTPでアクセスし、メトリクスを収集
- Prometheusサーバー内に時系列データとして保存
このうち、kube-apiserverから監視対象候補を見つけ、relabel_configsで実際のターゲットを決める部分をいわゆる「サービスディスカバリ」と表現したりします。順番に詳しく見ていきます。
まず、ここまで機会がなかったので紹介してきませんでしたが、ConfigMapは、他のオブジェクトが使うための非機密の設定データを保持するAPIオブジェクトです74。Prometheusをクラスタに反映したkubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.29/samples/addons/prometheus.yamlのコマンドでConfigMapも既にクラスタに反映済みでした。以下でマニフェストを確認してみます。
kubectl -n istio-system get configmap prometheus -o yaml
# apiVersion: v1
# data:
# alerting_rules.yml: |
# {}
# alerts: |
# {}
# allow-snippet-annotations: "false"
# prometheus.yml: |
# global:
# evaluation_interval: 1m
# scrape_interval: 15s
# scrape_timeout: 10s
# scrape_configs:
# - job_name: kubernetes-api-servers
# bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
# kubernetes_sd_configs:
# - role: endpoints
# relabel_configs:
# - action: keep
# regex: default;kubernetes;https
# source_labels:
# - __meta_kubernetes_namespace
# - __meta_kubernetes_service_name
# - __meta_kubernetes_endpoint_port_name
# scheme: https
# tls_config:
# ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# ...このConfigMapのdata.prometheus.ymlにPrometheusの設定が入っています。クラスタ内で動くPrometheusのサーバーは、この設定を元にkube-apiserverに問い合わせ、監視候補となるPodやServiceなどの情報を取得します。
kube-apiserverから返ってくる情報は大量であり、また監視にあたっては不要なもの (例えば、未起動のPodの情報など) も多いため、絞り込みを行います (正確にはKubernetesのラベルをPrometheus用にマッピングしていたりもします)。その絞り込み条件が上記マニフェストにおけるdata.prometheus.yml.scrape_configs[].relabel_configs[]です。
例えば以下は未起動 / 完了済み / 起動失敗のPodは監視対象から除外するといったことを表しています。
- job_name: kubernetes-pods
honor_labels: true
kubernetes_sd_configs:
- role: pod # 対象は Pod
relabel_configs:
...
- action: drop # 一致する場合は監視対象から除外
regex: Pending|Succeeded|Failed|Completed # Pod が未起動 / 完了済み / 起動失敗
source_labels:
- __meta_kubernetes_pod_phase
...絞り込みを行って監視対象を決めたら、その監視対象のエンドポイントにHTTPでアクセスしてメトリクスを収集します。ここでいうエンドポイントとはStatus > Target Healthで見たEndpointに表示されているものです。echo-splitのPod (v1) は私の環境ではhttp://10.244.1.7:15020/stats/prometheusになっています (Pod IPは環境ごとに異なるため、各自の環境ではkubectl -n default get pod -l app=echo-split,version=v1 -o wideで確認してください)。このエンドポイントも上記の流れで組み立てられているので、一例として深掘りしてみます。
まず前提として、今回の環境ではIstioのサイドカーがPodに注入された際に、いくつかのannotationsが付与されています。また、PodのIPアドレスは10.244.1.7であることも確認できます。
kubectl -n default get pod -l app=echo-split,version=v1 -o yaml
# apiVersion: v1
# items:
# - apiVersion: v1
# kind: Pod
# metadata:
# annotations:
# ...
# prometheus.io/path: /stats/prometheus
# prometheus.io/port: "15020"
# prometheus.io/scrape: "true"
# ...
# status:
# podIP: 10.244.1.7
...prometheus.io/から始まるannotationsが3つ存在することがわかります。改めてPrometheusのConfigMapを抜粋します。(kubectl -n istio-system get configmap prometheus -o yamlで確認可能です)
job_name: kubernetes-pods
honor_labels: true
kubernetes_sd_configs:
- role: pod
...
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
...
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: (\d+);((([0-9]+?)(\.|$)){4})
replacement: $2:$1
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_port
- __meta_kubernetes_pod_ip
target_label: __address__
...それぞれのrelabelステップは以下のように動いています。
| relabel ステップ | 何をしているか |
|---|---|
action: keep (prometheus_io_scrape) | prometheus.io/scrape: "true"の Pod のみを監視対象に残す |
action: replace (prometheus_io_scheme → __scheme__) | prometheus.io/scheme annotation を URL のスキーム (http/https) に反映。未指定なら http |
action: replace (prometheus_io_path → __metrics_path__) | prometheus.io/path annotation を URL のパスに反映。未指定なら/metrics |
action: replace (prometheus_io_port + pod_ip → __address__) | Pod IP とprometheus.io/portを組み合わせて URL のホスト:ポートを組み立て |
各relabelブロックをYAMLレベルで深掘り
順番に詳しく見ていきます。まず以下の部分はprometheus.io/scrape: "true"のPodのみが監視対象となることが表現されています。
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrapeそして以下はprometheus.io/schemeがあればURLの先頭に使用します。なければデフォルトはhttpです。URLの末尾のパスはprometheus.io/pathがあればそれを使用し、なければ/metricsです。今回はPodのannotationsにて前者は未指定のためhttp、後者はprometheus.io/path: /stats/prometheusとなっているため、それが適用されます。
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scheme
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__そして以下でprometheus.io/port: "15020"とpodIP: 10.244.1.7を使ってURLの本体を組み立てます。
- action: replace
regex: (\d+);((([0-9]+?)(\.|$)){4})
replacement: $2:$1
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_port
- __meta_kubernetes_pod_ip
target_label: __address__まとめると、Prometheusはkube-apiserverにPodなど各種リソースの情報を問い合わせ、その結果をフィルタリングして残ったものを監視対象として画面に表示していたということです。そのフィルタリングの過程をエンドポイントのURLを例にとって紹介しました。Prometheusではこのような仕組みでKubernetesを継続的に監視し、メトリクスをPullして情報を収集しています。
ちなみに、これまでUIで確認してきた情報はAPI経由でも取得可能です。
# 例えば Status > Target Health で見た情報
curl -s http://localhost:9090/api/v1/targets
# レスポンスの JSON が大量に出力Flux での GitOps と Kustomize での環境差異管理
途中から始めたい方は、サンプルリポジトリ
zenn-k8s-handsonをcloneしてmake ckpt-30を実行すると、この節の前提状態 (Istio + Prometheusまで導入済み) を再現できます。
これまでの章ではkubectl applyやhelm upgrade --installを使い、クラスタに対する変更を人間が直接適用してきました。ここでは、その適用の起点をGitに移します。つまり、今まで作ってきた各種リソースのマニフェストをGitで管理し、Fluxがそれをクラスタ内からPullして同期するというGitOpsの流れを確認していきます。あわせて、Kustomizeを使いつつ「環境」の考え方も登場させて、「開発環境はmainの状態を自動反映、本番環境は自動反映せず手動反映」のようなこともします。
おさらいですが、GitOpsとはGitなどのバージョン管理システムを理想的な状態 (desired state) の拠り所として扱い、その内容に実クラスタを (自動で) 収束させる運用方法です。実現させるツールとしてArgo CDやFluxなどがありますが、これらを用いると一定間隔でGitの内容を取得し、クラスタとの差分を適用できます。人間がkubectl applyなどでクラスタ側を直接変更しても、次の同期でGitの状態に戻されます。つまり、Gitを起点にしたReconciliation Loopです。75
Kustomize
Fluxの前に、まず既存のマニフェストをKustomizeで整理します。引き続き、実際に今まで作ってきたリソースをそのまま題材にします。
おさらいすると、Kustomizeはマニフェストの差分を管理するKubernetesネイティブなツールで、kubectlからそのまま使えます。基本の考え方は、共通の完成形マニフェストをbase/に置き、環境ごとの差分だけをoverlays/で上書きして最終的なマニフェストを組み立てるというものです。
サンプルを簡単に再掲します。(必要であればマニフェスト管理と Helm、Kustomizeに戻ってください)
- 共通の完成形マニフェスト
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: app
image: ghcr.io/example/myapp:1.0.0
env:
- name: LOG_LEVEL
value: info- 上書き
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 1 # 2 ⇒ 1
template:
spec:
containers:
- name: app
image: ghcr.io/example/myapp:1.0.0-dev # 開発用イメージ
env:
- name: LOG_LEVEL
value: debug # info ⇒ debug今回は開発環境と本番環境の2つを用意していきますが、これをKustomizeなしでやろうとすると既存のマニフェストが以下のようになります。
manifests/
├─ dev/
│ ├─ deployment.yaml
│ ├─ service.yaml
│ ├─ deploy-svc.yaml
│ ├─ gateway-basic.yaml
│ └─ echo-split.yaml
└─ prod/
├─ deployment.yaml
├─ service.yaml
├─ deploy-svc.yaml
├─ gateway-basic.yaml
└─ echo-split.yamlマニフェストの数や環境の数が増えると、この構成では管理が大変になってきます。Kustomizeを用いた最終的な構成イメージは以下の通りです。
.
└─ manifests/
├─ base/
│ ├─ deployment.yaml
│ ├─ service.yaml
│ ├─ deploy-svc.yaml
│ ├─ gateway-basic.yaml
│ ├─ echo-split.yaml
│ └─ kustomization.yaml
└─ overlays/
├─ dev/
│ ├─ kustomization.yaml
│ ├─ patch-nginx-replicas.yaml
│ └─ patch-traffic-split.yaml
└─ prod/
├─ kustomization.yaml
├─ patch-nginx-replicas.yaml
└─ patch-traffic-split.yamlまずはディレクトリを切って、これまで作ってきた環境共通のマニフェストをbase/へ移動します。
mkdir -p manifests/base manifests/overlays/dev manifests/overlays/prod
mv deployment.yaml service.yaml deploy-svc.yaml gateway-basic.yaml echo-split.yaml manifests/base/base/には環境共通の完成形マニフェストを置き、overlays/devとoverlays/prodでは差分だけを持たせます。今回は「devではレプリカ数を少なく、prodでは多めにする」という差分を例に確認していきます。
まずはbase/側のkustomization.yamlです。これでKustomizeの管理対象を宣言します。
cat > manifests/base/kustomization.yaml <<'EOF'
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- deployment.yaml
- service.yaml
- deploy-svc.yaml
- gateway-basic.yaml
- echo-split.yaml
EOF次に、dev環境のoverlayです。今回は環境差分をNamespaceで分離します。namespace: devによって、DeploymentやServiceなどNamespaceスコープのリソースにはdev Namespaceが自動付与されます。ただしKustomizeがNamespace自体を自動作成するわけではないため、適用先のNamespaceを別途マニフェストとして用意します。
../../baseの取り込みと差分用のパッチ
cat > manifests/overlays/dev/kustomization.yaml <<'EOF'
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: dev
resources:
- ../../base
- namespace.yaml
patches:
- path: patch-nginx-replicas.yaml
EOFdevNamespace
cat > manifests/overlays/dev/namespace.yaml <<'EOF'
apiVersion: v1
kind: Namespace
metadata:
name: dev
EOF例えばdevでnginxのreplicasを2から1に落とす場合、以下のようなパッチを置きます。
cat > manifests/overlays/dev/patch-nginx-replicas.yaml <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
EOFprodも同じようにoverlayを作っておきます。対象は同じくnginxで、こちらはreplicasを2から4に増やします。
cat > manifests/overlays/prod/kustomization.yaml <<'EOF'
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: prod
resources:
- ../../base
- namespace.yaml
patches:
- path: patch-nginx-replicas.yaml
EOF
cat > manifests/overlays/prod/namespace.yaml <<'EOF'
apiVersion: v1
kind: Namespace
metadata:
name: prod
EOF
cat > manifests/overlays/prod/patch-nginx-replicas.yaml <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 4
EOFこの時点で、環境ごとの最終マニフェストが組み立てられるようになりました。まず最終マニフェストの中身を以下のコマンドで確認できます。
kubectl kustomize manifests/overlays/dev
# ...
# ---
# apiVersion: apps/v1
# kind: Deployment
# metadata:
# name: nginx
# namespace: dev # default ではなく dev になっている
# spec:
# replicas: 1 # 2 ⇒ 1 になっている
# ...
# ---
# ...nginxのDeploymentで作成されるPodが1になっていることが確認できました。
開発環境の内容をクラスタに反映する場合は以下のコマンドです。(これまでdevというNamespaceは存在しなかったので、色々とcreatedと出力されます)
kubectl apply -k manifests/overlays/dev
# namespace/dev created
# service/echo created
# service/echo-split created
# service/nginx created
# deployment.apps/echo created
# deployment.apps/echo-split-v1 created
# deployment.apps/echo-split-v2 created
# deployment.apps/nginx created
# destinationrule.networking.istio.io/echo-split created
# gateway.networking.istio.io/web-gateway created
# virtualservice.networking.istio.io/echo-split-gateway created
# virtualservice.networking.istio.io/echo-split-mesh created
# virtualservice.networking.istio.io/web-route createdKustomizeでの差分管理は以上です。このように「ベースとなる内容にパッチを当てる」ことで環境ごとの差分を管理しやすくするツールです。
では次はFluxで上記を同期対象にしていきましょう。
Flux のセットアップ
今回は公式のbootstrapコマンド76でFluxをクラスタに導入します。念のため前提として、GitHubのOrganization配下ではない個人リポジトリを使って進めていきます。(GitHub以外だったりリポジトリの性質でコマンドが変わります)
まず事前準備としてGitHubでPersonal Access Token (PAT) を取得します (お好みで他の方法でも大丈夫です)。前提として、検証で使えるリポジトリも必要です。手順例を簡単に記載しておきます。
本記事は学習目的のため個人のPATを使いますが、本番運用での採用は推奨しません。本番ではFlux公式の GitHub App ベースの bootstrap やSSH Deploy Key、Workload Identity Federationなどの利用を推奨します。あわせて、クラスタ内のシークレット管理にはSOPS / Sealed Secrets / External Secretsなどの仕組みの検討が必要です。(Flux Security)
- GitHub右上のプロフィール画像からSettings
- Developer settings
- Personal access tokens ⇒ Fine-grained tokens
- Generate new token
- Token name: flux-bootstrap-spot
- Expiration: 7 days
- Description: 空で良い
- Resource owner: 自分
- Repository access: Only select repositories
- Selected repositories: 検証用リポジトリ (作ってない場合は作ってください)
- Permissions:
- Administration: Read-only
- Contents: Read and write
- Metadata: Read-only
作成したPATとユーザー名、リポジトリ名を環境変数に入れます。
export GITHUB_TOKEN=<YOUR_PAT_TOKEN>
GITHUB_USER=<YOUR_USER_NAME>
GITHUB_REPO=<YOUR_REPO_NAME>以下のコマンドで「このクラスタはFluxを入れて良い状態か」をチェックします。
flux check --pre
# ► checking prerequisites
# ✔ Kubernetes 1.35.0 >=1.33.0-0
# ✔ prerequisites checks passed上記のような表示が出れば問題ありません。ではクラスタにFluxを導入していきます。(説明簡略化のためmainブランチをそのまま使います。なお、個人リポジトリ前提なので--personalを付けています)
mkdir -p clusters/kind
# GITHUB_TOKEN は暗黙で読み込まれる
flux bootstrap github \
--token-auth \
--owner=${GITHUB_USER} \
--repository=${GITHUB_REPO} \
--branch=main \
--path=./clusters/kind \
--personal
# ► connecting to github.com
# ► cloning branch "main" from Git repository "https://github.com/<YOUR_USER_NAME>/<YOUR_REPO_NAME>.git"
# ✔ cloned repository
# ► generating component manifests
# ✔ generated component manifests
# ✔ committed component manifests to "main" ("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa")
# ► pushing component manifests to "https://github.com/<YOUR_USER_NAME>/<YOUR_REPO_NAME>.git"
# ► installing components in "flux-system" namespace
# ✔ installed components
# ✔ reconciled components
# ► determining if source secret "flux-system/flux-system" exists
# ► generating source secret
# ► applying source secret "flux-system/flux-system"
# ✔ reconciled source secret
# ► generating sync manifests
# ✔ generated sync manifests
# ✔ committed sync manifests to "main" ("bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb")
# ► pushing sync manifests to "https://github.com/<YOUR_USER_NAME>/<YOUR_REPO_NAME>.git"
# ► applying sync manifests
# ✔ reconciled sync configuration
# ◎ waiting for GitRepository "flux-system/flux-system" to be reconciled
# ✔ GitRepository reconciled successfully
# ◎ waiting for Kustomization "flux-system/flux-system" to be reconciled
# ✔ Kustomization reconciled successfully
# ► confirming components are healthy
# ✔ helm-controller: deployment ready
# ✔ kustomize-controller: deployment ready
# ✔ notification-controller: deployment ready
# ✔ source-controller: deployment ready
# ✔ all components are healthy上記出力のうち、主要な部分のみ解説します。以下のようなことが起きています。
- 指定したリポジトリを一時ディレクトリにclone (
cloning branch "main" from Git repository "https://github.com/<YOUR_USER_NAME>/<YOUR_REPO_NAME>.git") - Flux controller本体のマニフェストを追加して、mainにプッシュ (
pushing component manifests to "https://github.com/<YOUR_USER_NAME>/<YOUR_REPO_NAME>.git") - マニフェストをクラスタに適用 (
installing components in "flux-system" namespace) - Gitの認証情報 (前述のPATがここで使用される) をSecretとしてクラスタに適用 (
applying source secret "flux-system/flux-system") - リポジトリとの同期用マニフェストを追加して、mainにプッシュ、クラスタに適用 (
applying sync manifests) - (ここからは追加したcontrollerが動く) リポジトリを取得し、クラスタ内にアーティファクト生成 (
waiting for GitRepository "flux-system/flux-system" to be reconciled) - アーティファクトを読んでビルドし、クラスタに適用。ここでFluxが自分自身をGitで管理する状態になる (
waiting for Kustomization "flux-system/flux-system" to be reconciled) - 各controllerがReadyか確認 (
confirming components are healthy)
さらに簡単にまとめると、以下です。
- 一時cloneしたリポジトリにFlux用マニフェストを書いてGitHubにプッシュ
- クラスタに初回適用
- FluxにGitの運用を引き継ぎ
GitHubにプッシュされたFlux用のマニフェストをローカルに落として軽く確認してみます。
git pull
# remote: Enumerating objects: 14, done.
# ...
# .../gotk-components.yaml | 6428 +++++++++
# .../flux-system/gotk-sync.yaml | 27 +
# .../kustomization.yaml | 5 +
# 3 files changed, 6460 insertions(+)
# create mode 100644 clusters/kind/flux-system/gotk-components.yaml
# create mode 100644 clusters/kind/flux-system/gotk-sync.yaml
# create mode 100644 clusters/kind/flux-system/kustomization.yaml現状、以下のようになっています。
.
├ clusters/
| └─ kind/
| └─ flux-system/
| ├─ gotk-components.yaml
| ├─ gotk-sync.yaml
| └─ kustomization.yaml
└ manifests/
├ ...gotk-components.yamlがFlux本体です。6,500行弱あるので中身の紹介は割愛しますが、flux-systemというNamespaceやGitRepository、Kustomizationなどの各種CRD、source-controllerという名前のFlux実体となるDeploymentなどが定義されています。(prefixのgotkはGitOps ToolKitの略です77)
クラスタに作成された各種リソースも確認してみます。
kubectl -n flux-system get gitrepositories,kustomizations,deployments,secrets
# NAME URL AGE READY STATUS
# gitrepository.source.toolkit.fluxcd.io/flux-system https://github.com/<YOUR_USER_NAME>/<YOUR_REPO_NAME>.git xm True stored artifact for revision 'main@sha1:bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb'
# NAME AGE READY STATUS
# kustomization.kustomize.toolkit.fluxcd.io/flux-system xm True Applied revision: main@sha1:bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/helm-controller 1/1 1 1 xm
# deployment.apps/kustomize-controller 1/1 1 1 xm
# deployment.apps/notification-controller 1/1 1 1 xm
# deployment.apps/source-controller 1/1 1 1 xm
# NAME TYPE DATA AGE
# secret/flux-system Opaque 2 xm先ほど紹介した流れとマッピングすると、以下がgotk-components.yamlで追加されたdeployment.apps/source-controller、deployment.apps/kustomize-controllerです。(helm-controllerとnotification-controllerも同じタイミングですが説明の流れ的に登場させられないので割愛します)
- Flux コントローラー本体のマニフェストファイルを追加して、main にプッシュ (
pushing component manifests to "https://github.com/<YOUR_USER_NAME>/<YOUR_REPO_NAME>.git")- マニフェストをクラスタに適用 (
installing components in "flux-system" namespace)
そして以下がgotk-sync.yamlで追加されたgitrepository.source.toolkit.fluxcd.io/flux-system、kustomization.kustomize.toolkit.fluxcd.io/flux-systemです。
- リポジトリとの同期用のマニフェストファイルを追加して、main にプッシュ、クラスタに適用 (
applying sync manifests)
source-controllerはgitrepository.source.toolkit.fluxcd.io/flux-systemを元に、クラスタ内で使えるアーティファクトを生成します。このgitrepository.source...はGitRepositoryというカスタムリソース (gotk-components.yamlで定義されたCRDによるもの) であり、「どのGitリポジトリの、どのブランチから取得するか」などを定義します (ほかにも同列の概念でOCIRepositoryやBucketなどが存在していて、sourceとして指定可能です78)。
そしてkustomize-controllerは、source-controllerが作ったアーティファクトを材料にして、FluxのKustomization (GitRepositoryと同じくカスタムリソース) をreconcileし、マニフェストをビルド / 適用します。Kustomizationは「どのsourceを参照し、そこから生成されたアーティファクトのどのパスを、どの間隔でクラスタに適用するか (加えて、不要リソースを削除 (prune) するか)」を定義します。(Kustomize紹介後なのでややこしいですが、KustomizationはFluxのカスタムリソースであり、内部的に使用されてはいますが、ツールとして紹介したKustomizeとは別物です)
まとめると、source-controllerがGitRepositoryをreconcileしてリポジトリの内容を取得・アーティファクトを生成し、kustomize-controllerがKustomizationの設定を見てクラスタへ反映するという役割分担になっています。
GitRepositoryとKustomizationはgotk-sync.yamlとして生成されています。
# This manifest was generated by flux. DO NOT EDIT.
---
apiVersion: source.toolkit.fluxcd.io/v1
kind: GitRepository
metadata:
name: flux-system
namespace: flux-system
spec:
interval: 1m0s # source-controller が Git リポジトリを fetch する間隔
ref:
branch: main # 対象ブランチ
secretRef:
name: flux-system
url: https://github.com/<YOUR_USER_NAME>/<YOUR_REPO_NAME>.git # 対象リポジトリ
---
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
metadata:
name: flux-system
namespace: flux-system
spec:
interval: 10m0s # kustomize-controller が Kustomization を reconcile する間隔
path: ./clusters/kind
prune: true # マニフェストからなくなったオブジェクトなどを削除する
sourceRef:
kind: GitRepository # 参照する source
name: flux-system # 参照する source の名前続いて、dev overlayを同期するためのFluxのKustomizationを追加します。コマンドで生成し、その結果をGitに置くのがわかりやすいです79。
flux create kustomization apps-dev \
--namespace=flux-system \
--source=GitRepository/flux-system \
--path="./manifests/overlays/dev" \
--prune=true \
--interval=1m \
--wait=true \
--export > clusters/kind/apps-dev.yaml生成されるマニフェストは以下のようになります。(バージョンなどで内容がブレる可能性があるため、あいまいな表現にしています)
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
metadata:
name: apps-dev
namespace: flux-system
spec:
interval: 1m0s
path: ./manifests/overlays/dev
prune: true
sourceRef:
kind: GitRepository
name: flux-system
wait: trueこれで、mainブランチにマージされた変更のうち、manifests/overlays/devに書かれた内容だけがkindクラスタへ自動で反映されるようになります。
一方で、prodは自動反映させず、人間が確認してから反映するようにします。
flux create kustomization apps-prod \
--namespace=flux-system \
--source=GitRepository/flux-system \
--path="./manifests/overlays/prod" \
--prune=true \
--interval=1m \
--wait=true \
--export > clusters/kind/apps-prod.yamlspec.suspend: trueはオプションがないため、手動で追加して止めておきます。80
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
metadata:
name: apps-prod
namespace: flux-system
spec:
+ suspend: true
interval: 1m0s
path: ./manifests/overlays/prod
prune: true
sourceRef:
kind: GitRepository
name: flux-system
wait: trueprodを反映したくなったら、suspendを外してcommitします。ちなみに、以下のコマンドで手動での再開 / 停止もできます。
# 反映再開
flux resume kustomization apps-prod -n flux-system
# 反映停止
flux suspend kustomization apps-prod -n flux-systemではDevとProdをクラスタに反映していきましょう。
git add clusters/kind/apps-dev.yaml clusters/kind/apps-prod.yaml
git commit -m "Add Flux Kustomizations for dev and prod"
git pushFlux導入後は、以下のコマンドで同期状態を確認できます。
flux get kustomizations -A
# NAMESPACE NAME REVISION SUSPENDED READY MESSAGE
# flux-system apps-dev main@sha1:cccccccc False True Applied revision: main@sha1:cccccccc
# flux-system apps-prod True False waiting to be reconciled
# flux-system flux-system main@sha1:cccccccc False True Applied revision: main@sha1:ccccccccProdについてはSUSPENDEDがTrueとなっており、クラスタへの反映は行われていないことが確認できます。
Flux の動作確認
ここまででKustomizeとFluxのセットアップが完了したので、実際にGitOpsの挙動を確認します。「Gitの変更がクラスタへ自動で反映されること」と「クラスタ側の手動変更がGitの状態へ自動で戻る (ドリフトが収束する) こと」の2点を順に見ていきます。
Git の変更が自動で反映されることを確認する
Gitを変更したときにクラスタが追従することを確認します。Kustomizeの章で準備した開発環境のnginx DeploymentでPodを3つにしてみましょう。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
- replicas: 1
+ replicas: 3変更前は以下のようになっています。
kubectl get deployment nginx -n dev -o yaml
# apiVersion: apps/v1
# kind: Deployment
# metadata:
# annotations:
# deployment.kubernetes.io/revision: "3"
# ...
# generation: 2
# labels:
# kustomize.toolkit.fluxcd.io/name: apps-dev
# kustomize.toolkit.fluxcd.io/namespace: flux-system
# name: nginx
# namespace: dev
# ...
# spec:
# ...
# replicas: 1
# ...spec.replicasが1になっています。おまけ的に、Fluxによってラベル (metadata.labels) が付与されていることも確認できます。
変更したらGitにcommit / pushします。
git add manifests/overlays/dev/patch-nginx-replicas.yaml
git commit -m "Adjust dev nginx pod to 3"
git push origin mainしばらく待つとFluxがその差分を検知し、devクラスタ側のnginx Deploymentを更新します。(以下のコマンドで手動でreconcileを促すこともできます)
flux reconcile source git flux-system -n flux-system
flux reconcile kustomization apps-dev -n flux-system改めてマニフェストを見て反映結果を確認してみます。
kubectl get deployment nginx -n dev -o yaml
# apiVersion: apps/v1
# kind: Deployment
# metadata:
# annotations:
# deployment.kubernetes.io/revision: "3"
# creationTimestamp: "<TIMESTAMP>"
# generation: 3
# ...
# spec:
# ...
# replicas: 3
# ...spec.replicasが3になっていることが確認できました。
手動変更のドリフトが戻ることを確認する
次に、kubectl applyでクラスタに手動で変更を加えてみます。replicasを5にしてみます。
kubectl scale deployment/nginx -n dev --replicas=5
# deployment.apps/nginx scaledすぐに以下のコマンドを打ってみます。
kubectl get deployment nginx -n dev
# NAME READY UP-TO-DATE AVAILABLE AGE
# nginx 5/5 5 5 xmreplicasが5になっています。しばらく待ってから、もう一度実行してみます。
kubectl get deployment nginx -n dev
# NAME READY UP-TO-DATE AVAILABLE AGE
# nginx 3/3 3 3 xm3に戻っていることが確認できました (見るタイミングによっては5が残っている場合もあります)。このようにFluxはReconciliation Loop を体感するで紹介した「宣言した状態に収束させる」という考え方を、KubernetesのDeploymentだけでなく「Gitを起点にしたクラスタ全体の運用」に拡張したもの (= GitOps) だと言えます。
Gatekeeper でのセキュリティ担保
途中から始めたい方は、サンプルリポジトリ
zenn-k8s-handsonを fork してから cloneし、GITHUB_TOKEN/GITHUB_USER/GITHUB_REPOをexportしたうえでmake ckpt-40を実行すると、この節の前提状態 (Istio + Prometheus + Flux bootstrap完了) を再現できます。詳細は同リポジトリのREADMEを参照してください。
Gitにcommitしたマニフェストが、Fluxによって自動でクラスタに反映されることが確認できました。ただし、Gitに「適用したくない内容が入ってしまった」など、そのまま自動反映されたくないときがあります。そこで最後の関門として置くのがAdmission Controllerです。
マニフェストへの制約と Gatekeeper、Kyverno のおさらいになりますが、KubernetesではCREATEやUPDATEのAPIリクエストがkube-apiserverに届くと、認証 / 認可やスキーマ検証を経て、etcdに保存される前に最終チェックされます。この最終チェックをAdmissionと表現し、その段階で「オブジェクトを変更する」「そのまま通す」「拒否する」といった処理を行う仕組みがAdmission Controllerです。Kubernetes組み込みのAdmissionだけでなく、Webhook経由で外部ツールを呼び出して制約をかける方法もあり、GatekeeperやKyvernoはそのためのツールで、クラスタへ保存される直前のオブジェクトを検査し、ルール違反ならそこで止めます。
新しく出てくる言葉がいくつかあるため、上記のAdmissionなども含め、一緒に紹介します。
- Admission: APIリクエストがetcdに保存される前の検査フェーズ
- Admission Controller: そのフェーズでオブジェクトを変更したり拒否したりする仕組み
- ポリシーエンジン: 入力データとルールをもとに、許可 / 拒否などの判定を返す仕組み
- OPA: Open Policy Agentの略で、汎用のポリシーエンジン
- Rego: OPAでポリシーを書くための宣言的な言語
OPAはKubernetes専用のツールではなく、CI/CDやAPI Gatewayなどでも使える汎用エンジンです。一方でGatekeeperは、そのOPAをKubernetesのAdmissionに組み込みやすくしたOSSで、ポリシーをConstraintTemplateとConstraintというカスタムリソースとして扱えるようにしています。 ConstraintTemplateの内側では最終的にRegoなどが使われますが、今回は公式のポリシーライブラリを使うのでRego自体は手書きしません。8182
Gatekeeper を kind クラスタに導入する
これまで使ってきたkindのクラスタを引き続き使います。クラスタにOSSのGatekeeperを導入していきます。
まずはHelmを使ってGatekeeperをインストールします。83
helm repo add gatekeeper https://open-policy-agent.github.io/gatekeeper/charts
helm repo update
# 動作確認時の安定版バージョンに固定
GATEKEEPER_VERSION=3.22.2
helm install gatekeeper gatekeeper/gatekeeper \
--namespace gatekeeper-system \
--create-namespace \
--version ${GATEKEEPER_VERSION}
# "gatekeeper" has been added to your repositories
# Hang tight while we grab the latest from your chart repositories...
# ...Successfully got an update from the "gatekeeper" chart repository
# ...Successfully got an update from the "istio" chart repository
# Update Complete. ⎈Happy Helming!⎈
# NAME: gatekeeper
# LAST DEPLOYED: <DATETIME>
# NAMESPACE: gatekeeper-system
# STATUS: deployed
# REVISION: 1
# DESCRIPTION: Install complete
# TEST SUITE: NonePodが起動していることを確認します。
kubectl get pods -n gatekeeper-system
# NAME READY STATUS RESTARTS AGE
# gatekeeper-audit-6d8d9bb8b8-xxxxx 1/1 Running 0 xs
# gatekeeper-controller-manager-7c8f9d4b5d-xxxxx 1/1 Running 0 xs
# gatekeeper-controller-manager-7c8f9d4b5d-yyyyy 1/1 Running 0 xs
# gatekeeper-controller-manager-7c8f9d4b5d-zzzzz 1/1 Running 0 xsgatekeeper-controller-manager-...がRunningであればOKです。次に、ポリシー本体となるConstraintTemplateを適用します。ここではRegoを自作せず、Gatekeeperの公式ポリシーライブラリにあるテンプレートを使います。8485
kubectl apply -f https://raw.githubusercontent.com/open-policy-agent/gatekeeper-library/master/library/general/disallowedtags/template.yaml
kubectl apply -f https://raw.githubusercontent.com/open-policy-agent/gatekeeper-library/master/library/general/containerresources/template.yaml
# constrainttemplate.templates.gatekeeper.sh/k8sdisallowedtags created
# constrainttemplate.templates.gatekeeper.sh/k8srequiredresources createdConstraintTemplateは「どういうルールで検査するか」の定義で、 Constraintは「そのルールをどこに、どんなパラメータで適用するか」の定義です。今回はAdmissionの挙動確認が主目的であるため、わかりやすさと説明簡略化の観点からdev NamespaceのPodに対してルールをかけます。(実運用ではDeploymentなどに対して早い段階でエラーを返したいことが多いと考えられます)
ではConstraintのマニフェストを作っていきます。今回は以下の2つを試します。
latestタグの禁止- CPU / Memoryの
requestsパラメータ必須
mkdir -p manifests/policies
cat > manifests/policies/gatekeeper-constraints-dev.yaml <<'EOF'
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sDisallowedTags
metadata:
name: disallow-latest-in-dev
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Pod"]
namespaces:
- dev
parameters:
tags:
- latest
---
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredResources
metadata:
name: require-cpu-memory-requests-in-dev
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Pod"]
namespaces:
- dev
parameters:
requests:
- cpu
- memory
EOFspec.match.kinds[].kindsに対象のリソース種別を指定し、spec.parametersにConstraintTemplateに渡す設定値を指定します。
なお、マニフェスト先頭のkindは制約の種類そのものです。今回のK8sDisallowedTagsとK8sRequiredResourcesは、先ほどクラスタに適用した2つのConstraintTemplateから定義されたConstraintの種類であり、意味は割とそのままですが、「禁止するタグに関するルール」と「必須の計算リソースに関するルール」を表しています。
では上記マニフェストをクラスタに適用します。
kubectl apply -f manifests/policies/gatekeeper-constraints-dev.yaml
# k8sdisallowedtags.constraints.gatekeeper.sh/disallow-latest-in-dev created
# k8srequiredresources.constraints.gatekeeper.sh/require-cpu-memory-requests-in-dev createdlatestタグの Pod が拒否されることを確認する
まずはlatestタグ違反だけを起こすPodを作ってみます。(requestsはちゃんと書いておきます)
cat > manifests/policies/pod-latest.yaml <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: nginx-latest
namespace: dev
spec:
containers:
- name: nginx
image: nginx:latest
resources:
requests:
cpu: 100m
memory: 128Mi
EOFこれをkubectl applyすると、以下のようにAdmissionで拒否されます。
kubectl apply -f manifests/policies/pod-latest.yaml
# Error from server (Forbidden): error when creating "manifests/policies/pod-latest.yaml": admission webhook "validation.gatekeeper.sh" denied the request: [disallow-latest-in-dev] container <nginx> uses a disallowed tag <nginx:latest>; disallowed tags are ["latest"]requestsがない Pod が拒否されることを確認する
次はlatestを外し、代わりにrequestsを消してみます。
cat > manifests/policies/pod-no-requests.yaml <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: nginx-no-requests
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.27.5
EOFこれも拒否されます。
kubectl apply -f manifests/policies/pod-no-requests.yaml
# Error from server (Forbidden): error when creating "manifests/policies/pod-no-requests.yaml": admission webhook "validation.gatekeeper.sh" denied the request: [require-cpu-memory-requests-in-dev] container <nginx> does not have <{"cpu", "memory"}> requests defined逆に、タグもrequestsも問題ないPodは通ります。
cat > manifests/policies/pod-ok.yaml <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: nginx-ok
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.27.5
resources:
requests:
cpu: 100m
memory: 128Mi
EOFkubectl apply -f manifests/policies/pod-ok.yaml
# pod/nginx-ok createdFlux 経由でも同じ制約が効くことを確認する
上記ではkubectl applyで手動適用してきましたが、これはFluxがGitから適用しようとした内容にも同じように効きます。FluxのKustomizationはGit上のマニフェストをビルドし、kube-apiserverに対して検証・適用するため、Admissionを迂回できません。
では同じ違反をGitOps経由で起こしてみます。manifests/overlays/devに違反Podを追加し、overlayのkustomization.yamlから参照させます。
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: dev
resources:
- ../../base
- namespace.yaml
+ - pod-policy-test.yaml
patches:
- path: patch-nginx-replicas.yamlcat > manifests/overlays/dev/pod-policy-test.yaml <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: pod-policy-test
namespace: dev
spec:
containers:
- name: nginx
image: nginx:latest
EOFこれをcommit / pushしたうえで、手動でreconcileを促します。
git add manifests/overlays/dev/kustomization.yaml manifests/overlays/dev/pod-policy-test.yaml
git commit -m "Add invalid pod to test Gatekeeper"
git push origin main
flux reconcile source git flux-system -n flux-system
flux reconcile kustomization apps-dev -n flux-system
# ► annotating GitRepository flux-system in flux-system namespace
# ✔ GitRepository annotated
# ◎ waiting for GitRepository reconciliation
# ✔ fetched revision main@sha1:dddddddddddddddddddddddddddddddddddddddd
# ► annotating Kustomization apps-dev in flux-system namespace
# ✔ Kustomization annotated
# ◎ waiting for Kustomization reconciliationこの状態のまま止まるので、強制終了してください。apps-devの状態を見てみます。
flux get kustomizations -A
# NAMESPACE NAME REVISION SUSPENDED READY MESSAGE
# flux-system apps-dev main@sha1:dddddddd False False Pod/dev/pod-policy-test dry-run failed (Forbidden): admission webhook "validation.gatekeeper.sh" denied the request: [require-cpu-memory-requests-in-dev] container <nginx> does not have <{"cpu", "memory"}> requests defined
# [disallow-latest-in-dev] container <nginx> uses a disallowed tag <nginx:latest>; disallowed tags are ["latest"]
# flux-system apps-prod True False waiting to be reconciled
# flux-system flux-system main@sha1:dddddddd False True Applied revision: main@sha1:ddddddddREADYがFalseになっています。MESSAGEを見るとrequestsにcpuとmemoryがないし、nginx:latestがついていると怒られています。またエラーの主体はFlux固有のものではなく、admission webhook "validation.gatekeeper.sh"になっています。つまりFluxはGitの内容を適用しようとしただけで、その最終判定をしているのはAdmissionということです。また、FluxのKustomizationは定期的にdry-runを実行し、差分や問題を検出するため、Gitに違反マニフェストが入っている限り同期が失敗し続けます。86
では、Git側を修正して復旧させます。
apiVersion: v1
kind: Pod
metadata:
name: pod-policy-test
namespace: dev
spec:
containers:
- name: nginx
- image: nginx:latest
+ image: nginx:1.27.5
+ resources:
+ requests:
+ cpu: 100m
+ memory: 128Migit add manifests/overlays/dev/pod-policy-test.yaml
git commit -m "Fix Gatekeeper policy violation"
git push origin main
...
flux reconcile source git flux-system -n flux-system
flux reconcile kustomization apps-dev -n flux-system
# ► annotating GitRepository flux-system in flux-system namespace
# ✔ GitRepository annotated
# ◎ waiting for GitRepository reconciliation
# ✔ fetched revision main@sha1:eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
# ► annotating Kustomization apps-dev in flux-system namespace
# ✔ Kustomization annotated
# ◎ waiting for Kustomization reconciliation
# ✔ applied revision main@sha1:eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee今度はKustomizationのreconcileも成功します。再度apps-devの状態を見てみます。
flux get kustomizations -A
# NAMESPACE NAME REVISION SUSPENDED READY
# flux-system apps-dev main@sha1:eeeeeeee False True Applied revision: main@sha1:eeeeeeee
# flux-system apps-prod True False waiting to be reconciled
# flux-system flux-system main@sha1:eeeeeeee False True Applied revision: main@sha1:eeeeeeeeこれでGitに書かれたdesired stateのうち、Admissionを通過したものだけがクラスタに反映されることが確認できました。Fluxが継続的に同期し、Gatekeeperがその入口で安全性を担保する、という役割分担です。
まとめ
これで各種ツールをkind上のクラスタで動かしてみる章は終わりです。次の章ではGoogle CloudのGKEに触れつつ、この章で動かしてきたPrometheus / Gatekeeper / サービスメッシュの関心事を、GKEとその周辺のマネージドサービスで見ていきます。
GKE と各種マネージドサービス
ここまではkind上のローカルクラスタにOSSのIstio、Prometheus、Gatekeeperなどを導入し、Kubernetesとその周辺ツールの手触り感を確認してきました。記事の最後として、同じ関心事をGoogle Cloudのマネージドサービスではどう扱うのかを見ていきます。
GKEはGoogle CloudのマネージドKubernetesで、Kubernetes APIやコントロールプレーンの管理をGoogle Cloudが担います87。開発者はワーカーノード上で自分のコンテナを動かすことに集中できます。この章で見ていくサービスの対応関係は以下のイメージです。
- ローカルで作ったkindクラスタ ⇒ GKE
- kind上で動かしたPrometheus ⇒ Managed Service for Prometheus
- kind上で動かしたGatekeeper ⇒ Policy Controller
- kind上で触ったIstio / サービスメッシュ ⇒ Cloud Service Mesh
なおCloud Service MeshのマネージドコントロールプレーンにはTraffic Director実装とistiod実装があり、新規導入ではデフォルトでTraffic Director実装が使われるため、「マネージドなIstio」とは単純に言い切れません。88
前提
GKE のモード
前提として、GKEにはAutopilotとStandardという2つのモードがあります。ノードの運用やマシンタイプの設定可否などのマネージド具合が異なり8990、Google Cloud推奨はよりマネージドなAutopilotモードです91。ここまでkindではノードやコントロールプレーンの構成を見てきましたが、GKEでは逆に「そのあたりをどこまで自分でやらなくて良いか」を見たいため、ここではAutopilotモードで進めます。(ノードプールやマシンタイプを明示的に管理したい場合や、クラスタ構成そのものを細かく設計したい場合はStandardモードの方が向いています)
Google Cloud の環境など
この章では、以下を満たす検証用のGoogle Cloudプロジェクトがある前提で進めます。
- 課金が有効になっているGoogle Cloudプロジェクト
gcloud auth loginでローカルから操作できる状態- APIの有効化、IAMの変更、GKEクラスタの作成ができる権限 (このあたりの必要権限の話も割愛させてください)
なお、本章は以下バージョンのgcloud CLIで動作確認しています。
gcloud --version | head -n 1
# Google Cloud SDK 565.0.0まず対象プロジェクトを設定しておきます。
PROJECT_ID={YOUR_PROJECT_ID}
gcloud auth login検証用プロジェクトを新規作成する場合
クリーンなプロジェクトから始める場合の一例です。プロジェクト作成にはroles/resourcemanager.projectCreator、請求先の紐付けにはプロジェクト側と請求先アカウント側の権限が必要です。9293
- 利用可能な請求先アカウント確認、gcloud CLI認証
# 請求先アカウント確認
gcloud billing accounts list
# gcloud CLI 認証
gcloud auth login- プロジェクト作成、請求先アカウント紐づけ
# Project ID はグローバルに一意である必要があるため、日時と乱数を付ける
PROJECT_ID="gke-lab-$(date +%Y%m%d%H%M%S)-${RANDOM}"
# gcloud billing accounts list で出力した ACCOUNT_ID のいずれかを指定
BILLING_ACCOUNT_ID="000000-000000-000000"
# プロジェクトの作成
gcloud projects create ${PROJECT_ID}
gcloud billing projects link "${PROJECT_ID}" \
--billing-account="${BILLING_ACCOUNT_ID}"検証が終わったら、このプロジェクトごと削除することで、残っているリソースをまとめて片付けられます。ただし、プロジェクトを削除すると中のリソースも使えなくなるため、必要なものが残っていないことを確認してから実行してください。
gcloud projects delete ${PROJECT_ID}GKE Autopilotクラスタを作るだけであれば、有効化するAPIはひとまずGoogle Kubernetes Engine APIのみです94。(後続の章でもいくつか有効化しますが、必要なタイミングで都度行います)
gcloud services enable container.googleapis.com \
--project=${PROJECT_ID}また、GKEのノードが使うSAには、最低限roles/container.defaultNodeServiceAccountが必要です。ここでは説明簡略化のため、公式ドキュメントでも紹介されているCompute Engineのdefault service accountに必要な権限を付与する方法で進めます95。(本来は専用のSAを作り、クラスタ作成時に--service-accountで指定する方法が推奨です)
以下のコマンドで権限を付与します。
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} \
--format="value(projectNumber)")
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${PROJECT_NUMBER}-compute@developer.gserviceaccount.com" \
--role="roles/container.defaultNodeServiceAccount"クラスタ作成
まずはGKEに最小のAutopilotクラスタを1つ作ります。請求先アカウント単位で毎月の無料枠はありますが、GKEはクラスタが存在するだけで課金されるので、途中でやめる場合も環境のクリーンアップは忘れずにお願いします。96
CLUSTER_NAME=gke-lab
CLUSTER_LOCATION=asia-northeast1
# 10 分くらいかかります
gcloud container clusters create-auto ${CLUSTER_NAME} \
--location=${CLUSTER_LOCATION} \
--project=${PROJECT_ID}
# Creating cluster gke-lab in asia-northeast1... Cluster is being health-checked (Kubernetes Con
# trol Plane is healthy)...done.
# Created [https://container.googleapis.com/v1/projects/gke-lab-2026xxxxxxxxxxx-xxxxxx/zones/asia-northeast1/clusters/gke-lab].
# To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/asia-northeast1/gke-lab?project=gke-lab-2026xxxxxxxxxxx-xxxxxx
# kubeconfig entry generated for gke-lab.
# NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS STACK_TYPE
# gke-lab asia-northeast1 1.35.1-gke.1396002 xx.xxx.xx.xxx ek-standard-8 1.35.1-gke.1396002 3 RUNNING IPV4MACHINE_TYPEがek-standard-8のノードが3つ作成されました。ekはE2の派生マシンシリーズで、Compute Engineのマシンファミリー一覧には登場しないAutopilot専用のマシンタイプです97。(公式ドキュメントに記載はありませんが、ek-standard-8はvCPU 8 / メモリ32 GBとされています98)
上記のクラスタ作成コマンドには引数がほぼありませんでした。一方、Standardモードのクラスタはノードのマシンタイプやノード数、オートスケーリングの設定などを指定して作るのが一般的です。例えば、最小構成のStandardクラスタは以下のようなコマンドになります。
# Standard モードでのクラスタ作成コマンド例
gcloud container clusters create gke-lab-standard \
--location=asia-northeast1-a \
--machine-type=e2-medium \
--num-nodes=3--machine-typeや--num-nodesで指定しているような、「マシンタイプを揃えた一定数のノードのまとまり」をGKEでは「ノードプール」と呼びます。これはクラスタ内のノードを構成単位にまとめたもので、マシンタイプ、ブートディスク、オートスケーリング設定などがプール単位で揃います99。Autopilotではこのノードプールをユーザー側で設計しません。DeploymentやPodの定義に書いたCPU / メモリ要求などをもとに、GKEがそれを動かすためのノードを自動で用意・調整します。(必要に応じてマニフェストに定義を追加することで調整は可能です)9190
kubectlからGKEクラスタに接続するには、GKE用の認証プラグインgke-gcloud-auth-pluginが必要です。100
gcloud components install gke-gcloud-auth-plugin
# その他の例: gcloud を apt で管理している場合
sudo apt-get install -y google-cloud-cli-gke-gcloud-auth-plugin認証情報を取得してkubectlの向き先をkindのクラスタからGKEに変更します。get-credentialsを実行するとkubeconfigが更新され、以降のkubectlは先ほど作ったクラスタを向くようになります。100
gcloud container clusters get-credentials ${CLUSTER_NAME} \
--location=${CLUSTER_LOCATION} \
--project=${PROJECT_ID}
# Fetching cluster endpoint and auth data.
# kubeconfig entry generated for gke-lab.クラスタの情報を確認してみます。
kubectl cluster-info
# Kubernetes control plane is running at https://<CONTROL_PLANE_ENDPOINT>
# GLBCDefaultBackend is running at https://<CONTROL_PLANE_ENDPOINT>/api/v1/namespaces/kube-system/services/default-http-backend:http/proxy
# KubeDNS is running at https://<CONTROL_PLANE_ENDPOINT>/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
# KubeDNSUpstream is running at https://<CONTROL_PLANE_ENDPOINT>/api/v1/namespaces/kube-system/services/kube-dns-upstream:dns/proxy
# Metrics-server is running at https://<CONTROL_PLANE_ENDPOINT>/api/v1/namespaces/kube-system/services/https:metrics-server:/proxy
# To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.確認できました。
fleet に登録する
このあと触るPolicy ControllerやCloud Service Meshはfleetという論理的なまとまりの上で有効化していく機能です。fleetはGKEの複数クラスタを管理するための仕組みですが、1クラスタのみでもfleetレベルの機能を使うために必要です。101
クラスタ作成時に--enable-fleetを付ければ同時に登録できますが、今回は既に作成したクラスタをあとから登録します。102
# API 有効化 (fleet の旧称が GKE Hub であるため、API は gkehub になっている)
gcloud services enable gkehub.googleapis.com \
--project=${PROJECT_ID}
# Operation "operations/acat.p2-XXXXXXXXXXXX-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" finished successfully.
# fleet に登録
gcloud container clusters update ${CLUSTER_NAME} \
--location=${CLUSTER_LOCATION} \
--enable-fleet \
--project=${PROJECT_ID}
# Updating gke-lab...done.
# Updated [https://container.googleapis.com/v1/projects/gke-lab-2026xxxxxxxxxxx-xxxxxx/zones/asia-northeast1/clusters/gke-lab].
# To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/asia-northeast1/gke-lab?project=gke-lab-2026xxxxxxxxxxx-xxxxxxfleetに登録されたクラスタは、membershipとして確認できます。fleetレベルの機能はこのmembership単位で適用します。
gcloud container fleet memberships list \
--project=${PROJECT_ID}
# NAME UNIQUE_ID LOCATION
# gke-lab xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx asia-northeast1membership名はデフォルトでクラスタ名と同じです。
Managed Service for Prometheus
Prometheus での監視の章ではPrometheusをkind上に自前で入れて、メトリクス収集の仕組みを確認しました。Managed Service for Prometheusは、Prometheusのメトリクス収集・保存・クエリ体験をGoogle Cloud側に寄せたマネージドサービスです。
サンプルアプリをデプロイする
Managed Service for Prometheusの公式ドキュメントでは、prom-exampleというサンプルアプリが使われています103。この記事でもそのまま使います。
kubectl create namespace prom-demo
# namespace/prom-demo created
kubectl -n prom-demo apply -f \
https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.17.2/examples/example-app.yaml
# Autopilot ではリソース要求がない Deployment に対してデフォルト値が自動で挿入されるため、以下の Warning が出ます。
# Warning: autopilot-default-resources-mutator:Autopilot updated Deployment prom-demo/prom-example: defaulted unspecified 'cpu' resource for containers [prom-example] (see http://g.co/gke/autopilot-defaults).
# deployment.apps/prom-example created
kubectl -n prom-demo get pods
# NAME READY STATUS RESTARTS AGE
# prom-example-xxxxxxxxxx-aaaaa 1/1 Running 0 xm
# prom-example-xxxxxxxxxx-bbbbb 1/1 Running 0 xm
# prom-example-xxxxxxxxxx-ccccc 1/1 Running 0 xm適用したアプリのマニフェストは以下のようになっています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: prom-example
labels:
app.kubernetes.io/name: prom-example
spec:
selector:
matchLabels:
app.kubernetes.io/name: prom-example
replicas: 3
template:
metadata:
labels:
app.kubernetes.io/name: prom-example
spec:
...
containers:
- image: nilebox/prometheus-example-app@sha256:dab60d038c5d6915af5bcbe5f0279a22b95a8c8be254153e22d7cd81b21b84c5
name: prom-example
ports:
- name: metrics
containerPort: 1234
command:
- "/main"
- "--process-metrics"
- "--go-metrics"以下、主要な点だけ簡単に解説します。
spec.replicas: 3つのPodを起動します。spec.template.spec.containers[].image: nilebox/prometheus-example-app というPrometheus形式のメトリクスを公開するGo製のアプリが使われています。Prometheusのメトリクスには4種類のタイプがあり104、そのうちのCounter (累積カウンタ) やHistogram (観測値の分布) などのメトリクスを/metricsエンドポイントで公開します。自分自身にHTTPリクエストを投げ続ける作りになっており、放置するだけでメトリクスの値が変化していくため、スクレイプ動作の確認に便利です。spec.template.spec.containers[].ports: メトリクス公開用ポート (1234) にmetricsという名前が付いています。のちほど作るPodMonitoringからこの名前を参照します。spec.template.spec.containers[].command: アプリ独自のメトリクスに加えて--process-metricsと--go-metricsを渡すことで、プロセスやGoランタイムのメトリクスも公開するようになっています。
PodMonitoring を作成する
次に、Managed Service for Prometheusに対してスクレイプ対象のPodを伝えるためのPodMonitoringというカスタムリソースを作ります。105
kubectl -n prom-demo apply -f \
https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.17.2/examples/pod-monitoring.yaml
# podmonitoring.monitoring.googleapis.com/prom-example created
kubectl -n prom-demo get podmonitoring
# NAME AGE
# prom-example xsマニフェストは以下のようになっています。
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
labels:
app.kubernetes.io/name: prom-example
spec:
selector:
matchLabels:
app.kubernetes.io/name: prom-example
endpoints:
- port: metrics
interval: 30sselector.matchLabelsでapp.kubernetes.io/name: prom-exampleのラベルが付いたPodを対象としています。そしてendpoints[].portでexample-app.yamlが公開しているポート (metrics) を指定して、そのポートをスクレイプするようにしています。
これで数分待てば自動的にメトリクスが取り込まれますが、スクレイプが正常にできる状態であることを能動的に確認するため、デバッグ用途でtarget statusという機能を一時的に有効にします。106
mkdir -p manifests/gke/prometheus
# features.targetStatus で target status を有効化
cat > manifests/gke/prometheus/operatorconfig-targetstatus.yaml <<'EOF'
apiVersion: monitoring.googleapis.com/v1
kind: OperatorConfig
metadata:
namespace: gmp-public
name: config
features:
targetStatus:
enabled: true
EOF
kubectl apply -f manifests/gke/prometheus/operatorconfig-targetstatus.yaml
# Warning: resource operatorconfigs/config is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
# operatorconfig.monitoring.googleapis.com/config configured
kubectl -n prom-demo describe podmonitorings/prom-example
# ...
# Status:
# Endpoint Statuses:
# Active Targets: 3
# Collectors Fraction: 1
# ...Active Targets: 3のように出ていれば、3つのPodがスクレイプ対象として正しく検出されています。確認が終わったらtarget statusは戻しておきます。
cat > manifests/gke/prometheus/operatorconfig-targetstatus.yaml <<'EOF'
apiVersion: monitoring.googleapis.com/v1
kind: OperatorConfig
metadata:
namespace: gmp-public
name: config
features:
targetStatus:
enabled: false
EOF
kubectl apply -f manifests/gke/prometheus/operatorconfig-targetstatus.yaml
# Warning: resource operatorconfigs/config is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
# operatorconfig.monitoring.googleapis.com/config configuredPromQL でメトリクスを見てみる
ローカルのkindで動かした際はPrometheusの画面を確認しましたが、Managed Service for Prometheusでは取り込んだメトリクスがCloud Monitoringから確認できます。107
また、記事の流れの都合で Prometheus での監視で説明できなかったのですが、Prometheusの時系列データを検索・集計・変換するための専用クエリ言語をPromQLと言い、Cloud MonitoringはPromQLによるクエリに対応しています。Google Cloudのコンソール画面からMetrics Explorerを開き、CodeタブでPromQLを使って確認してみます。
たとえば以下のようなクエリでサンプルアプリの1秒あたりのリクエスト数を確認できます。
sum(rate(example_requests_total{namespace="prom-demo"}[5m])) Cloud Monitoring での PromQL クエリ実行
Cloud Monitoring での PromQL クエリ実行
ローカルのkindで検証したように、Prometheusを自前で立てるとサーバーのデプロイやデータの保持期間も開発者が気にする必要があります。一方でGKE + Managed Service for Prometheusでは、「メトリクスを出すアプリ」と「それをどのようにスクレイプするか」に集中できるようになります。103
Policy Controller
Gatekeeper でのセキュリティ担保ではGatekeeperをkindのクラスタに直接導入し、latestタグ禁止やrequests必須といった制約をAdmissionで強制しました。Policy Controllerは、その「クラスタにガードレールを入れる」という関心事がGoogle Cloudに統合されたマネージドなサービスです。単一クラスタだけでなく、fleet全体に対しても一貫したポリシーを適用できます。108101
Policy Controller を有効化する
まずPolicy ControllerのAPIを有効化し、次にクラスタに対してPolicy Controllerを有効化します。
AutopilotではPolicy Controllerの機能のうち、ポリシー違反を書き換えるmutation機能と、特定のNamespaceをポリシーから除外する機能が使えません (公式に理由は明示されていませんが、Autopilotではadmission / mutationをGoogleが管理する設計のため、ユーザー側で同種の操作を重ねられない仕様だと推測しています)。ここではValidation (違反の拒否) とAudit (違反の検出) だけを使う最小構成で進めます。109
# Policy Controller の API 有効化
gcloud services enable anthospolicycontroller.googleapis.com \
--project=${PROJECT_ID}
# Operation "operations/acat.p2-XXXXXXXXXXXX-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" finished successfully.
# クラスタで Policy Controller 有効化
gcloud container fleet policycontroller enable \
--memberships=${CLUSTER_NAME} \
--location=${CLUSTER_LOCATION} \
--project=${PROJECT_ID}
# Waiting for Feature Policy Controller to be created...done.
# Waiting for MembershipFeature projects/gke-lab-2026xxxxxxxxxxx-xxxxxx/locations/asia-northeast1/
# memberships/gke-lab/features/policycontroller to be updated...done.上記コマンドから1〜2分待つとクラスタでPolicy Controllerが有効化され、以下でPolicy Controllerの構成と現在の状態を確認できます。(内容の簡単な解説はコマンド出力内に書いておきました)
gcloud container fleet policycontroller describe \
--memberships=${CLUSTER_NAME} \
--location=${CLUSTER_LOCATION} \
--project=${PROJECT_ID}
# createTime: '2026-xx-xxTxx:xx:xx.xxxxxxxxxZ'
# membershipSpecs:
# projects/XXXXXXXXXXXX/locations/asia-northeast1/memberships/gke-lab:
# policycontroller:
# policyControllerHubConfig:
# auditIntervalSeconds: '60' # 60 秒ごとに既存リソースを監査
# deploymentConfigs:
# admission:
# podAffinity: ANTI_AFFINITY # admission 用の複数 Pod を同じノードに配置しないようにする
# installSpec: INSTALL_SPEC_ENABLED
# monitoring:
# backends:
# - PROMETHEUS # Prometheus の exposition format でメトリクスを公開する
# - CLOUD_MONITORING # メトリクスを Cloud Monitoring にも送る
# policyContent:
# bundles:
# policy-essentials-v2022: {}
# templateLibrary:
# installation: ALL # constraint template library を全部入れる
# version: 1.23.1
# membershipStates:
# projects/XXXXXXXXXXXX/locations/asia-northeast1/memberships/gke-lab:
# policycontroller:
# componentStates:
# admission:
# details: 1.23.1
# state: ACTIVE
# audit:
# details: 1.23.1
# state: ACTIVE
# mutation:
# details: 'deployment not installed: resource is missing'
# state: NOT_INSTALLED
# policyContentState:
# bundleStates:
# asm-policy-v0.0.1:
# state: NOT_INSTALLED
# cis-gke-v1.5.0:
# state: NOT_INSTALLED
# cis-k8s-v1.5.1:
# state: NOT_INSTALLED
# cost-reliability-v2023:
# state: NOT_INSTALLED
# nist-sp-800-190:
# state: NOT_INSTALLED
# nist-sp-800-53-r5:
# state: NOT_INSTALLED
# nsa-cisa-k8s-v1.2:
# state: NOT_INSTALLED
# pci-dss-v3.2.1:
# state: NOT_INSTALLED
# pci-dss-v3.2.1-extended:
# state: NOT_INSTALLED
# pci-dss-v4.0:
# state: NOT_INSTALLED
# policy-essentials-v2022:
# state: ACTIVE
# psp-v2022:
# state: NOT_INSTALLED
# pss-baseline-v2022:
# state: NOT_INSTALLED
# pss-restricted-v2022:
# state: NOT_INSTALLED
# referentialSyncConfigState:
# state: NOT_INSTALLED
# templateLibraryState:
# state: ACTIVE
# state: ACTIVE # Policy Controller 全体としては健全に稼働中 (NOT_INSTALLED もいくつかあるが、、という状態)
# state:
# code: OK # fleet から見た membership の状態が OK
# updateTime: '2026-xx-xxTxx:xx:xx.xxxxxxxxxZ'
# name: projects/gke-lab-2026xxxxxxxxxxx-xxxxxx/locations/global/features/policycontroller
# resourceState:
# state: ACTIVE
# spec: {}
# updateTime: '2026-xx-xxTxx:xx:xx.xxxxxxxxxZ'Policy Controllerの有効化が完了すると、事前定義されたポリシー集であるconstraint template libraryもデフォルトでインストールされます (templateLibrary: installation: ALL)110。
# 公式ドキュメントに書いてあるラベル付きのコマンド例は環境/バージョンによって合わないことがあるようなのでこちらを実行
kubectl get constrainttemplates
# NAME AGE
# allowedserviceportname xm
# asmauthzpolicydisallowedprefix xm
# asmauthzpolicyenforcesourceprincipals xm
# asmauthzpolicynormalization xm
# asmauthzpolicysafepattern xm
# ...数が多いためすべては解説できませんが、以下のようなConstraintTemplateが入っています。
k8srequiredlabels: 指定キーのラベル必須化 (このあと使います)k8sdisallowedtags: 特定タグ (latestなど) 禁止k8srequiredresources:requests/limits必須化k8spssrunasnonroot: rootユーザーでの起動禁止
dryrunで監査してみる
ここでは素朴な例として「Namespaceにはownerラベルを必須にする」という制約を使います。まずは違反を拒否せず、dryrunで監査だけおこないます。111
- Namespaceとマニフェスト作成 (YAMLの内容から読み取れるため、内容の説明は割愛します)
# owner ラベルなしで Namespace 作成
kubectl create namespace policy-test-audit
# namespace/policy-test-audit created
mkdir -p manifests/gke/policy
cat > manifests/gke/policy/require-owner-label.yaml <<'EOF'
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: namespaces-must-have-owner
spec:
enforcementAction: dryrun
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
message: All namespaces must have an owner label
labels:
- key: owner
allowedRegex: ".+"
EOF- クラスタに適用し、監査結果を確認
kubectl apply -f manifests/gke/policy/require-owner-label.yaml
# k8srequiredlabels.constraints.gatekeeper.sh/namespaces-must-have-owner created
# 監査結果を確認
kubectl describe k8srequiredlabels namespaces-must-have-owner
# ...
# Status:
# ...
# Total Violations: 13 # 数値は環境によって異なる可能性があります
# Violations:
# ...
# Enforcement Action: dryrun
# Group:
# Kind: Namespace
# Message: All namespaces must have an owner label
# Name: policy-test-audit
# Version: v1
# Enforcement Action: dryrun
# ...policy-test-auditのNamespaceにownerラベルがないため、監査結果に違反として出ます (他12件のNamespaceもラベルがないので出ていますが、説明には関係ないので気にせず進めます)。違反を解消してみます。
kubectl label namespace policy-test-audit owner=morishin --overwrite
# namespace/policy-test-audit labeledauditのインターバルは60秒なので、反映を待って以下のコマンドを実行します。
kubectl describe k8srequiredlabels namespaces-must-have-owner
# ...
# Status:
# Total Violations: 12
# ...denyにして拒否してみる
次に、同じ制約をdryrunからdenyに切り替えて、違反したリソースがAdmissionで拒否されることを確認します。111
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: namespaces-must-have-owner
spec:
- enforcementAction: dryrun
+ enforcementAction: deny
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
message: All namespaces must have an owner label
labels:
- key: owner
allowedRegex: ".+"- クラスタに適用
kubectl apply -f manifests/gke/policy/require-owner-label.yaml- 違反するNamespaceを作成し、クラスタに適用
cat > manifests/gke/policy/namespace-no-owner.yaml <<'EOF'
apiVersion: v1
kind: Namespace
metadata:
name: policy-test-deny
EOF
kubectl apply -f manifests/gke/policy/namespace-no-owner.yaml
# Error from server (Forbidden): error when creating "manifests/gke/policy/namespace-no-owner.yaml": admission webhook "validation.gatekeeper.sh" denied the request: [namespaces-must-have-owner] All namespaces must have an owner labelAll namespaces must have an owner labelというメッセージとともにadmission webhookでクラスタへの適用が拒否されたことがわかります。ラベルを付ければ通ります。
cat > manifests/gke/policy/namespace-with-owner.yaml <<'EOF'
apiVersion: v1
kind: Namespace
metadata:
name: policy-test-ok
labels:
owner: morishin
EOF
kubectl apply -f manifests/gke/policy/namespace-with-owner.yaml
# namespace/policy-test-ok createdGatekeeper でのセキュリティ担保のGatekeeperと見比べて、ConstraintやAdmissionの基本的な考え方は同じです。一方で、GKEではPolicy Controllerをfleet featureとして有効化し、クラスタ横断で使いやすくなっています。108
Cloud Service Mesh
Istio によるサービスメッシュではIstioを通じてサービスメッシュの基本的な考え方を見ました。Cloud Service MeshはGoogle Cloudのマネージドなサービスメッシュで、トラフィック管理、可観測性、セキュリティというサービスメッシュの代表的な関心事をGoogle Cloudと統合された形で扱えます。Autopilotではistiod相当のコントロールプレーンがクラスタ外部にGoogle管理で置かれ (in-cluster型ではない)、サービスメッシュのUIも自動的に有効になります。88112
Cloud Service Mesh を有効化する
Cloud Service Meshを有効化し、このクラスタをautomatic managementにします。automatic managementは、コントロールプレーン (istiod相当) とEnvoyサイドカー、CNI (Container Network Interface) などのアップグレードやスケールをGoogleにフルマネージドさせるモードで、前述の通りAutopilotではin-cluster型が選べないため実質これ一択です。113
# API 有効化
gcloud services enable mesh.googleapis.com \
--project=${PROJECT_ID}
# Operation "operations/acat.p2-XXXXXXXXXXXX-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" finished successfully.
# fleet の機能として Cloud Service Mesh 有効化
gcloud container fleet mesh enable \
--project=${PROJECT_ID}
# Waiting for Feature Service Mesh to be created...done.
# クラスタで Cloud Service Mesh 有効化
gcloud container fleet mesh update \
--management automatic \
--memberships=${CLUSTER_NAME} \
--location=${CLUSTER_LOCATION} \
--project=${PROJECT_ID}
# Waiting for MembershipFeature projects/gke-lab-2026xxxxxxxxxxx-xxxxxx/locations/asia-northeast1/memberships/gke-lab/features/servicemesh to be updated...done.
# Cloud Service Mesh の有効化状態の確認
gcloud container fleet mesh describe \
--project=${PROJECT_ID}
# ...
# createTime: '2026-xx-xxTxx:xx:xx.xxxxxxxxxZ'
# membershipSpecs:
# projects/XXXXXXXXXXXX/locations/asia-northeast1/memberships/gke-lab:
# mesh:
# management: MANAGEMENT_AUTOMATIC
# membershipStates:
# projects/XXXXXXXXXXXX/locations/asia-northeast1/memberships/gke-lab:
# servicemesh:
# conditions:
# - code: VPCSC_GA_SUPPORTED
# details: This control plane supports VPC-SC GA.
# documentationLink: http://cloud.google.com/service-mesh/docs/managed/vpc-sc
# severity: INFO
# controlPlaneManagement:
# details:
# - code: REVISION_READY
# details: 'Ready: asm-managed'
# implementation: TRAFFIC_DIRECTOR
# state: ACTIVE
# dataPlaneManagement:
# details:
# - code: OK
# details: Service is running.
# state: ACTIVE
# state:
# code: OK
# description: 'Revision ready for use: asm-managed.'
# updateTime: '2026-xx-xxTxx:xx:xx.xxxxxxxxxZ'
# name: projects/gke-lab-2026xxxxxxxxxxx-xxxxxx/locations/global/features/servicemesh
# resourceState:
# state: ACTIVE
# spec: {}
# updateTime: '2026-xx-xxTxx:xx:xx.xxxxxxxxxZ'上記のような状態になればOKです。(10分くらいかかります)
小さな HTTP 通信を流してみる
Cloud Service MeshのテレメトリはHTTP通信のときに特に見やすいため、ここでは極小の2サービス構成を使います。echoサービスを立てて、curl Podから定期的にHTTPリクエストを流します。Namespaceにsidecar auto-injectionのラベルを付けてからデプロイすると、各PodにEnvoy sidecarが注入されます。113114
kubectl create namespace mesh-demo
kubectl label namespace mesh-demo \
istio.io/rev- istio-injection=enabled --overwrite
# namespace/mesh-demo created
# label "istio.io/rev" not found. ⇐ not found で問題なし
# namespace/mesh-demo labeled
mkdir -p manifests/gke/mesh
cat > manifests/gke/mesh/mesh-demo.yaml <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo
namespace: mesh-demo
spec:
replicas: 1
selector:
matchLabels:
app: echo
template:
metadata:
labels:
app: echo
spec:
containers:
- name: echo
image: hashicorp/http-echo:1.0.0
args: ["-text=hello from echo", "-listen=:5678"]
ports:
- containerPort: 5678
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
---
apiVersion: v1
kind: Service
metadata:
name: echo
namespace: mesh-demo
spec:
selector:
app: echo
ports:
- name: http
port: 80
targetPort: 5678
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: curl
namespace: mesh-demo
spec:
replicas: 1
selector:
matchLabels:
app: curl
template:
metadata:
labels:
app: curl
spec:
containers:
- name: curl
image: curlimages/curl:8.8.0
command: ["/bin/sh", "-c"]
args:
- |
while true; do
curl -s http://echo.mesh-demo.svc.cluster.local/;
sleep 2;
done
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
EOF
kubectl apply -f manifests/gke/mesh/mesh-demo.yaml
kubectl get pods -n mesh-demo
# NAME READY STATUS RESTARTS AGE
# curl-xxxxxxxxxx-aaaaa 2/2 Running 0 xm
# echo-xxxxxxxxxx-bbbbb 2/2 Running 0 xm
kubectl get pods -n mesh-demoでREADYが1/2のまま動かない場合は、gcloud container fleet mesh describeのdataPlaneManagement.stateがACTIVEになっているのを確認したうえで、以下のコマンドでPodを再スタートさせてみてください。kubectl rollout restart deploy/echo deploy/curl -n mesh-demoCloud Service Meshを有効化した直後は、Pod作成時にTraffic Director側のMeshリソースのprovisioningが間に合わず、サイドカーがxDSから構成を貰えずに止まってしまうことがあります。
READYが2/2になっていれば、アプリ本体に加えてEnvoy sidecarも入っていることがわかります。通信自体は以下で確認できます。
kubectl logs deploy/curl -n mesh-demo -c curl --tail=3
# hello from echo
# hello from echo
# hello from echoGoogle Cloud のコンソールでサービスメッシュの見え方を確認する
数分待つと、Cloud Service Meshの画面でサービス一覧やメトリクスが見えるようになります。
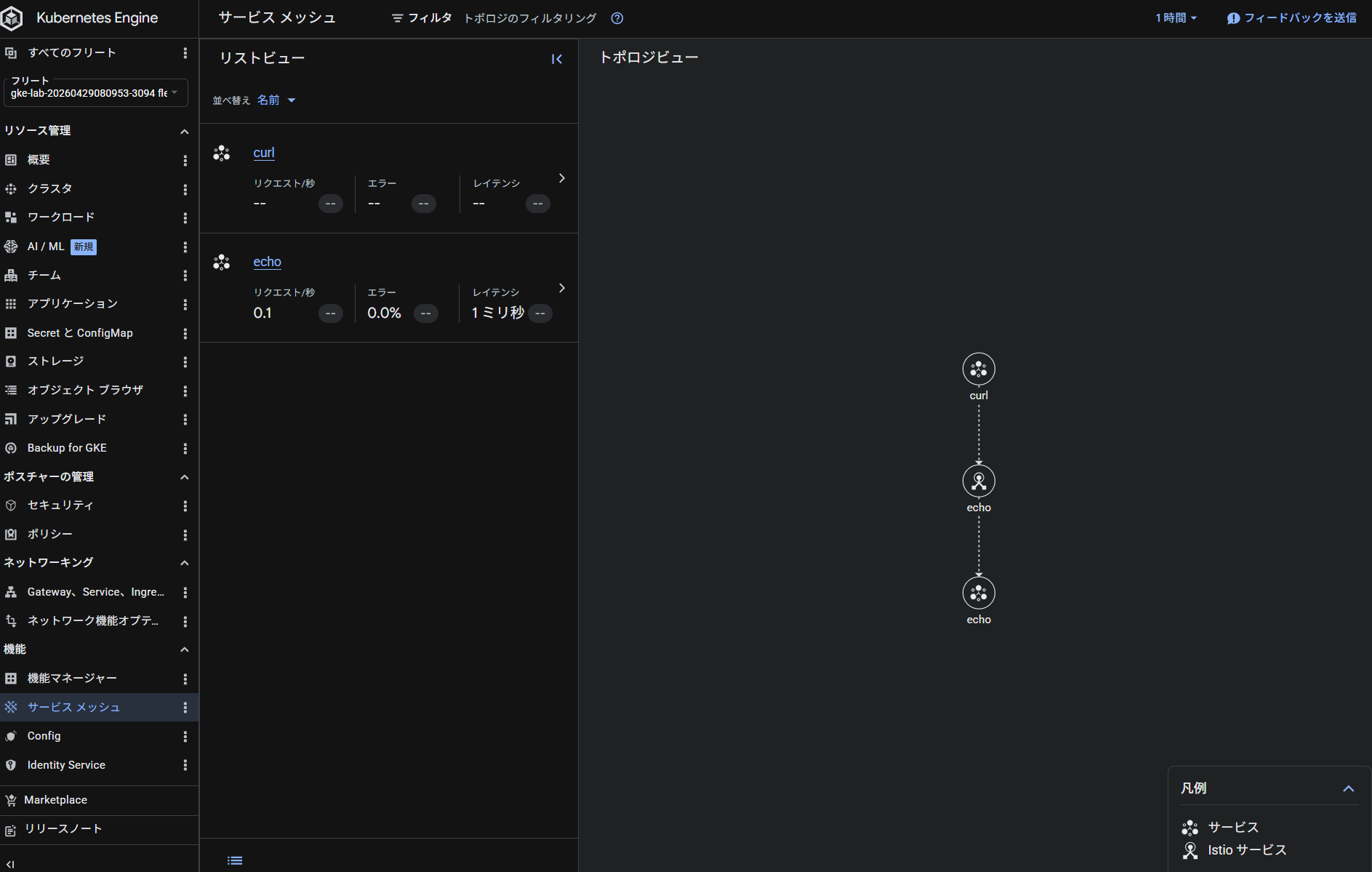 Cloud Service Mesh 画面 (トポロジビュー)
Cloud Service Mesh 画面 (トポロジビュー)
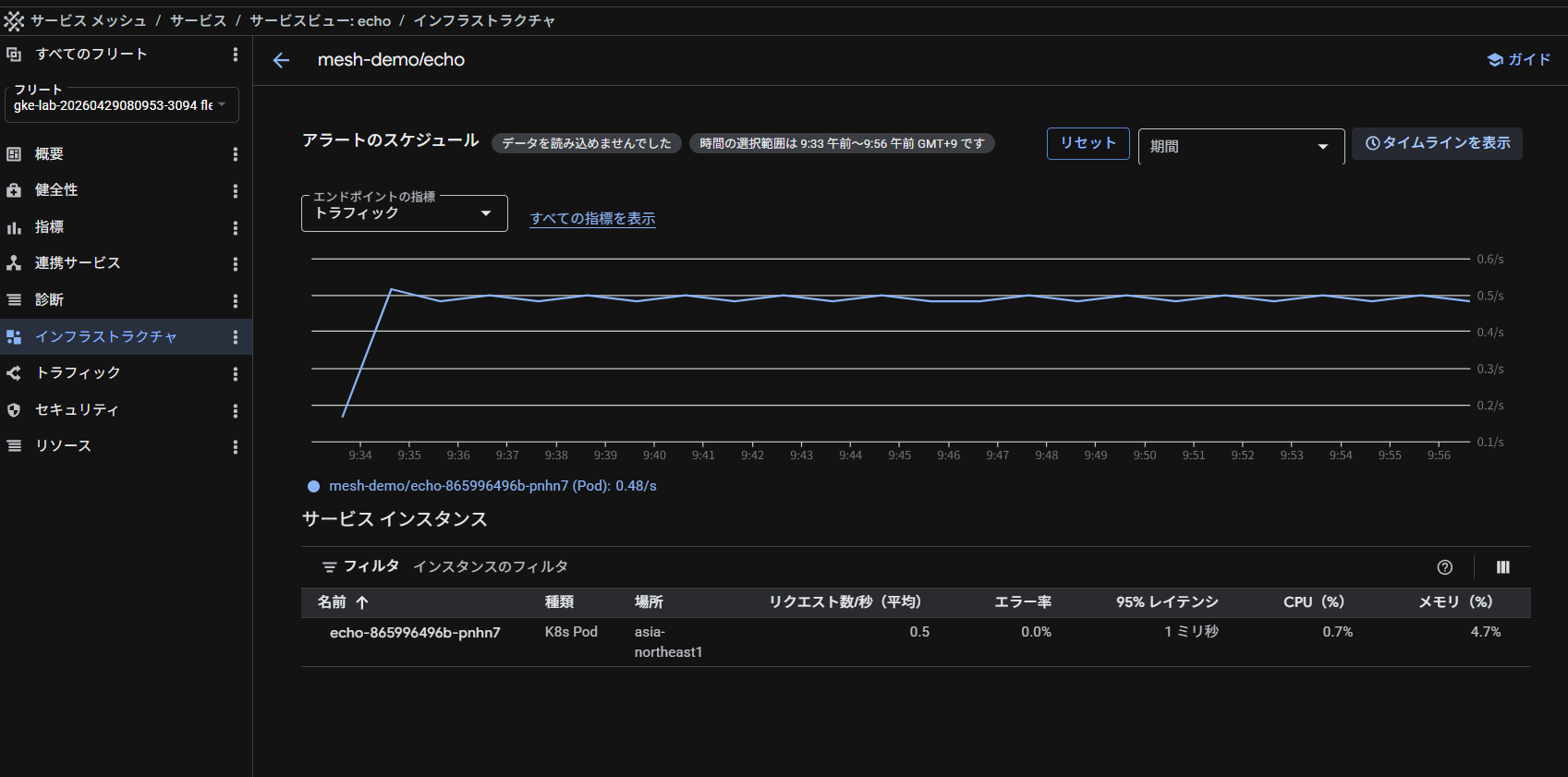 Cloud Service Mesh 画面 (
Cloud Service Mesh 画面 (echoのインフラストラクチャ)
Cloud Service MeshはサイドカープロキシがHTTPトラフィックを観測してCloud Monitoring / Cloud Loggingにテレメトリを送るため、アプリ側に追加の計装を書かなくても「どのサービスがどのサービスを呼んでいるか」を見やすいのが利点です。114
Istio によるサービスメッシュではIstioのコンポーネントやsidecar注入の仕組み自体を追いましたが、GKEではそのコントロールプレーンの管理をGoogleに任せ、こちらはメッシュの利用に集中できるのが違いです。
料金の概況
ここまで使ってきたManaged Service for Prometheus、Policy Controller、Cloud Service Meshの3サービスは、運用コストの増え方の性格がそれぞれかなり違います。最後にざっくり比較してまとめておきます。
Managed Service for Prometheus
「Cloud Monitoringに取り込まれたsampleの数」で課金されます115。1データポイントが何sampleにカウントされるかはメトリクスの型で変わり、スカラー値は1サンプル、ヒストグラムは1データポイントあたり2 + 非ゼロのバケット数というカウント方式です。116
単価は階層型で、月500億sampleまでは $0.06 / 100万sample (2023年8月の60% 値下げ後の単価)、それより多い分は段階的に下がっていきます。117 Prometheus形式のsampleベース課金には無料枠が設定されておらず (byteベース課金のCloud Monitoringメトリクスには別途150 MiB / 月の無料枠あり)、データ保持期間は24ヶ月です。115
メトリクス量とscrape間隔に対して線形に増えていくため、不要なメトリクスをmetricRelabelingで落としたり、scrape間隔を伸ばしたりするのが基本的なコスト対策になります。
Policy Controller
GKE上で使う場合は追加料金がかかりません。元々はGKE Enterprise tierに紐づく機能でしたが、2024年9月のGKE料金改定でfleet管理・Config Management・Policy ControllerなどがGKE Standard側に含まれる形に整理され、現在はGKEの基本料金のみで使えます。118
Cloud Service Mesh
「sidecarが注入されたclientインスタンスの数」で課金されます。GKEのPod、Cloud Runのインスタンス、Proxyless gRPCのインスタンスがそれぞれ1 clientとして数えられ、レプリカが増えればその分client数も増えます。単価は $0.0006945 / client / 時間 (= 約 $0.50 / client / 月) で、無料枠はありません。119 Mesh CA、マネージドcontrol plane、標準テレメトリダッシュボードは追加料金なしで含まれます。
レプリカ数に比例するので、サービス数とレプリカ数を抑えれば線形にコストも下がります。
なお、この記事のサンプル構成 (3 Podのprom-example、echo + curlの小さなCSMデモ) では、いずれも無料枠やごく小さい単価レンジに収まります。検証が済んだら、次節でクリーンアップしておきます。
環境のクリーンアップ
- プロジェクトを作成した場合
gcloud projects delete ${PROJECT_ID}- クラスタのみ削除する場合
gcloud container clusters delete ${CLUSTER_NAME} \
--location=${CLUSTER_LOCATION} \
--project=${PROJECT_ID}- 検証用Namespaceのみ削除する場合 (クラスタは残す)
kubectl delete namespace mesh-demo prom-demo policy-test-audit policy-test-okまとめ
この章ではGKE Autopilot上でManaged Service for Prometheus / Policy Controller / Cloud Service Meshを動作確認し、前章でkindに立てたツール群がGoogle Cloudマネージドではどう変わるかの対応関係を見ました。
おわりに
Kubernetesの基礎的な内容、Kubernetesを取り巻く用語やツール、そしてGoogle CloudのマネージドKubernetesであるGKEを概観してきました。Kubernetes関連のトピックに触れた際に、なんとなくでも「これはこの辺の話だな」くらいはわかるようになりたいという思いで書きましたが、ちょっとスコープを広げすぎた感もあります…。
一方で、私の力量では扱えなかった領域がまだまだあります。例えば以下のようなトピックは本記事では触れられていません。
- StatefulSet、DaemonSet、Job / CronJobなどのワークロードAPI
- PersistentVolume / PersistentVolumeClaim / CSIといったストレージ関連
- NetworkPolicyやPod Security Admissionの本格運用
- Horizontal / Vertical Pod Autoscaler、Cluster Autoscalerなどのオートスケール
- 本番運用でのRBAC、マルチテナンシー、コスト最適化
非常に広大で奥深い領域ですが、AIエージェントのサンドボックス環境120としても注目されつつあるため、今後も学んでいきます。
Footnotes
-
Referring to Kubernetes API resources (Kubernetes公式ドキュメント) ↩
-
Resource Management for Pods and Containers (Kubernetes公式ドキュメント) ↩
-
cgroups(7) (Linux man-pages) / About cgroup v2 (Kubernetes 公式ドキュメント) ↩
-
Configuration > Cluster-wide options (kind公式ドキュメント) / Quick Start (kind公式ドキュメント) (
kind create cluster後のkubectl get nodes出力にkind-control-plane/kind-worker/kind-worker2などの命名例がある) ↩ -
Objects In Kubernetes (Kubernetes公式ドキュメント) / Pod API Reference (Kubernetes公式ドキュメント) ↩
-
Configuration (kind公式ドキュメント) / Implementation details (Kubernetes公式ドキュメント) ↩
-
ReplicaSet API Reference (Kubernetes公式ドキュメント) / ReplicaSet (Kubernetes公式ドキュメント) ↩
-
Deployment API Reference (Kubernetes公式ドキュメント) / Deployments (Kubernetes公式ドキュメント) ↩
-
DNS for Services and Pods (Kubernetes公式ドキュメント) / Configuring each kubelet in your cluster using kubeadm > clusterDNS: 10.96.0.10 (Kubernetes公式ドキュメント) / Kubernetes Default ServiceCIDR Reconfiguration (Kubernetes公式ドキュメント) ↩
-
README > Mac, Windows and WSL2 support (cloud-provider-kind GitHub) ↩
-
pkg/gateway/controller.go#L322-L335 (cloud-provider-kind GitHub) ↩
-
Managing Workloads > Organizing resource configurations (Kubernetes公式ドキュメント) ↩
-
Kubernetes v1.33: Continuing the transition from Endpoints to EndpointSlices (Kubernetes Blog) ↩
-
Configuring OpenID Connect in cloud providers (GitHub Docs) ↩
-
Configure Workload Identity Federation with deployment pipelines (Google Cloud) ↩
-
Admission Control in Kubernetes > Admission control phases (Kubernetes公式ドキュメント) ↩
-
Installing the Sidecar > Automatic sidecar injection (Istio公式ドキュメント) ↩
-
Prometheus > Installation > Option 1: Quick start (Istio公式ドキュメント) ↩
-
Compare features in Autopilot and Standard clusters (Google Cloud) ↩ ↩2
-
GKE Autopilot overview > Autopilot clusters and workloads (Google Cloud) ↩ ↩2
-
Enable, disable, or change billing for a project (Google Cloud) ↩
-
About Balanced and Scale-Out ComputeClasses in Autopilot clusters (Google Cloud) ↩
-
Install kubectl and configure cluster access (Google Cloud) ↩ ↩2
-
Register a cluster on Google Cloud to your fleet (Google Cloud) ↩
-
Get started with managed collection > Deploy the example application (Google Cloud Observability) ↩ ↩2
-
Get started with managed collection > Enabling the target status feature ↩
-
Provision a managed Cloud Service Mesh control plane on GKE (Google Cloud) ↩ ↩2
-
Cost controls and attribution (Google Cloud Observability) ↩
-
Managed Service for Prometheus price cut (Google Cloud Blog) ↩
-
GKE gets new pricing and capabilities on 10th birthday (Google Cloud Blog) ↩
-
Agent Sandbox のご紹介: Kubernetes と GKE 上のエージェント AI 向けの強力なガードレール ↩
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。