MCPツールボックスとAgentDevelopmentKit(ADK)を使用してプロジェクト進捗管理エージェントを構築する
BigQueryのプロジェクト・タスク情報を MCP Toolbox for Databasesから参照し、ADKを使って進捗状況などを回答できるエージェントの作り方を紹介します。
Table of contents
author: Mami
1. はじめに
本記事では、MCP Toolbox for DatabasesとAgent Development Kit(ADK) を組み合わせて、社内プロジェクトの進捗管理を支援するエージェントを構築します。BigQuery上に用意したプロジェクト・タスク情報をもとに、自然言語の質問に回答できるようにすることで、担当者や管理者が効率的に進捗状況を把握できる仕組みを作ります。
MCP Toolbox for Databases は、データベースに対する接続やSQLの実行を「ツール」として定義し、エージェントから安全かつ統制された形で呼び出せるようにする仕組みです。これにより、BigQueryやCloudSQLなどのデータベースに直接アクセスするのではなく、あらかじめ設定したクエリや会話型分析ツールを介して情報を取得できます。
Agent Development Kit(ADK) は、エージェントを効率的に設計・開発するためのフレームワークです。モデルやツールの接続、会話フローの定義、デプロイ方法を統一的に扱えるため、開発者はアプリケーションロジックに集中できます。MCP Toolboxで定義したツールをADKで利用することで、ユーザーからの質問を自然言語で処理し、必要なデータ取得と回答生成を一気通貫で実現できます。
2. BigQueryデータセットとテーブル・ビューを用意
BigQueryデータセットを作成し以下テーブルを2つ作成してください。
projects テーブルを作成します。
CREATE TABLE IF NOT EXISTS `YOUR_PROJECT_ID.YOUR_DATASET_NAME.projects`
(
project_id STRING OPTIONS(description = "P001 等。tasks.project_id の親キー"),
project_name STRING OPTIONS(description = "プロジェクト名"),
owner STRING OPTIONS(description = "責任者/PM"),
start_date DATE OPTIONS(description = "開始日"),
end_date DATE OPTIONS(description = "終了予定日"),
status STRING OPTIONS(description = "未着手/進行中/完了/保留 など"),
budget_jpy INT64 OPTIONS(description = "予算(円)")
)
CLUSTER BY status, owner
OPTIONS(description = "プロジェクトテーブル");tasks テーブルを作成します。
CREATE TABLE IF NOT EXISTS `YOUR_PROJECT_ID.YOUR_DATASET_NAME.tasks` (
project_id STRING,
task_id STRING,
task_name STRING,
assignee STRING,
start_date DATE,
end_date DATE,
status STRING,
hours_spent INT64
)
PARTITION BY end_date
CLUSTER BY project_id, status, assignee;v_tasks_with_project ビューを作成します。
CREATE OR REPLACE VIEW `YOUR_PROJECT_ID.YOUR_DATASET_NAME.v_tasks_with_project` AS
SELECT
t.project_id, p.project_name, p.owner AS project_owner, p.status AS project_status,
t.task_id, t.task_name, t.assignee, t.start_date, t.end_date, t.status AS task_status,
t.hours_spent
FROM `YOUR_PROJECT_ID.YOUR_DATASET_NAME.tasks` AS t
LEFT JOIN `YOUR_PROJECT_ID.YOUR_DATASET_NAME.projects` AS p
USING (project_id);3. 用意したテーブルにサンプルデータ用意
projectsテーブルにサンプルデータを挿入します。
INSERT INTO `YOUR_PROJECT_ID.YOUR_DATASET_NAME.projects`
(project_id, project_name, owner, start_date, end_date, status, budget_jpy)
VALUES
('P001','新ECサイト刷新','佐藤', DATE '2025-08-01', DATE '2025-10-31','進行中',15000000),
('P002','モバイルアプリ改修','鈴木', DATE '2025-08-01', DATE '2025-09-30','進行中',8000000),
('P003','データ基盤整備','高橋', DATE '2025-08-05', DATE '2025-11-15','未着手',12000000),
('P004','保守改善パッケージ','山本', DATE '2025-08-10', DATE '2025-09-25','未着手',3000000);tasksテーブルにサンプルデータを挿入します。
INSERT INTO `YOUR_PROJECT_ID.YOUR_DATASET_NAME.tasks`
(project_id, task_id, task_name, assignee, start_date, end_date, status, hours_spent)
VALUES
-- P001 新ECサイト刷新
('P001','T001','企画書作成','佐藤', DATE '2025-08-01', DATE '2025-08-05','完了',12),
('P001','T002','顧客ヒアリング','鈴木', DATE '2025-08-03', DATE '2025-08-06','完了',8),
('P001','T003','要件定義','高橋', DATE '2025-08-07', DATE '2025-08-12','進行中',15),
('P001','T004','詳細設計','伊藤', DATE '2025-08-10', DATE '2025-08-17','未着手',0),
('P001','T005','インフラ準備','山本', DATE '2025-08-15', DATE '2025-08-22','未着手',0),
-- P002 モバイルアプリ改修
('P002','T006','UIデザイン','山本', DATE '2025-08-02', DATE '2025-08-08','完了',20),
('P002','T007','API設計','伊藤', DATE '2025-08-04', DATE '2025-08-15','進行中',25),
('P002','T008','DB設計','佐藤', DATE '2025-08-05', DATE '2025-08-14','未着手',0),
('P002','T009','ログイン機能実装','鈴木', DATE '2025-08-10', DATE '2025-08-18','進行中',18),
('P002','T010','結合テスト','高橋', DATE '2025-08-16', DATE '2025-08-25','未着手',0),
-- P003 データ基盤整備
('P003','T011','DWH設計','高橋', DATE '2025-08-05', DATE '2025-08-20','未着手',0),
('P003','T012','ETL設計','伊藤', DATE '2025-08-06', DATE '2025-08-21','未着手',0),
('P003','T013','単体テスト','鈴木', DATE '2025-08-10', DATE '2025-08-18','進行中',10),
('P003','T014','監視設定','佐藤', DATE '2025-08-12', DATE '2025-08-22','未着手',0),
('P003','T015','ドキュメント作成','山本', DATE '2025-08-12', DATE '2025-08-20','完了',5),
-- P004 保守改善パッケージ
('P004','T016','改善要望整理','佐藤', DATE '2025-08-10', DATE '2025-08-12','完了',6),
('P004','T017','軽微修正対応','鈴木', DATE '2025-08-13', DATE '2025-08-18','進行中',9),
('P004','T018','リリース準備','伊藤', DATE '2025-08-18', DATE '2025-08-25','未着手',0),
('P004','T019','ユーザトレーニング','高橋', DATE '2025-08-20', DATE '2025-08-28','未着手',0),
('P004','T020','運用マニュアル更新','山本', DATE '2025-08-21', DATE '2025-08-29','未着手',0);データを確認します。
SELECT * FROM v_tasks_with_project;4. MCPツールボックスを設定
MCPツールボックスのインストール
データベース用MCPツールボックスのバイナリバージョンをインストールします。 リリースページを確認し、OSとCPUアーキテクチャに応じて変更してください。
mkdir mcp-toolbox
cd mcp-toolbox
# リリースページで最新のバージョンを確認してください
export VERSION=0.14.0
export OS="darwin/arm64" # one of linux/amd64, darwin/arm64, darwin/amd64, or windows/amd64
curl -O https://storage.googleapis.com/genai-toolbox/v$VERSION/$OS/toolbox
chmod +x toolboxtools.yaml を作成
tools.yamlは、MCP Toolbox for Databasesがどのデータベースにどう接続し、どんなSQLをツールとして提供し、それらをどうまとめてエージェントに渡すかを記述する設定ファイルです。記載方法はこちらをご確認ください。
sources:
my-bigquery-source:
kind: bigquery
project: YOUR_PROJECT_ID
location: us-central1
tools:
# 1) BigQuery ソースとの会話型のやり取り
# このツールを利用するには、事前に `gcloud services enable geminidataanalytics.googleapis.com` の実行が必要です。
ask_data_insights:
kind: bigquery-conversational-analytics
source: my-bigquery-source
description: |
BigQueryテーブルの内容に関してデータ分析を行ったり、インサイトを得たり、複雑な質問に答える
# 2) 任意SELECT(読み取り専用)
bq-exec-sql:
kind: bigquery-execute-sql
source: my-bigquery-source
description: 任意の読み取り専用GoogleSQLを実行する(更新系は禁止)
# 3) データセット内テーブル/ビュー一覧
bq-list-tables:
kind: bigquery-get-table-info
source: my-bigquery-source
description: テーブルのメタデータを取得します
# 4) プロジェクト別進捗サマリ(JOINビュー)
bq-project-summary:
kind: bigquery-sql
source: my-bigquery-source
description: プロジェクト単位で完了/進行中/未着手件数と総工数を集計する
statement: |
SELECT
project_id,
project_name,
COUNTIF(task_status = '完了') AS done_count,
COUNTIF(task_status = '進行中') AS doing_count,
COUNTIF(task_status = '未着手') AS todo_count,
SUM(hours_spent) AS total_hours
FROM `YOUR_PROJECT_ID.YOUR_DATASET_NAME.v_tasks_with_project`
GROUP BY project_id, project_name
ORDER BY project_id
LIMIT 100;
# 5) 期限範囲でタスク取得
bq-get-tasks-by-due:
kind: bigquery-sql
source: my-bigquery-source
description: タスクの終了日が指定期間に含まれるものを取得する
parameters:
- name: start_due
type: string
description: "開始日 (YYYY-MM-DD)"
- name: end_due
type: string
description: "終了日 (YYYY-MM-DD)"
statement: |
SELECT project_id, task_id, task_name, assignee, start_date, end_date, status, hours_spent
FROM `YOUR_PROJECT_ID.YOUR_DATASET_NAME.tasks`
WHERE end_date BETWEEN PARSE_DATE('%Y-%m-%d', @start_due) AND PARSE_DATE('%Y-%m-%d', @end_due)
ORDER BY end_date, project_id, task_id
LIMIT 100;
toolsets:
project-tracker-toolset:
- ask_data_insights
- bq-exec-sql
- bq-list-tables
- bq-project-summary
- bq-get-tasks-by-dueToolbox サーバーを実行
先ほど作成したファイルを指定して、Toolboxサーバーを実行します。
./toolbox --tools-file "tools.yaml"5. エージェントとToolboxを接続
エージェント開発キット(ADK)をインストール
agentフォルダを作成、仮想Python環境を作成してADKとMCP Toolbox for Databasesのパッケージをインストールします。
mkdir my-agents
cd my-agents
python -m venv .venv
source .venv/bin/activate
pip install google-adk toolbox-coreエージェントを作成
adk create project-tracker-agent以下手順に沿って選択・入力していきます。
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
You need an existing Google Cloud account and project, check out this link for details:
https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai
Enter Google Cloud project ID [YOUR_PROJECT_ID]:
Enter Google Cloud region [us-central1]:
Agent created in <YOUR_HOME_FOLDER>/my-agents/project-tracker-agent:
- .env
- __init__.py
- agent.py「project-tracker-agent」フォルダ内に.env、__init__.py、agent.pyが出来上がります。
この状態でADKを起動してみます。
adk web以下のようなWeb UIが起動します。
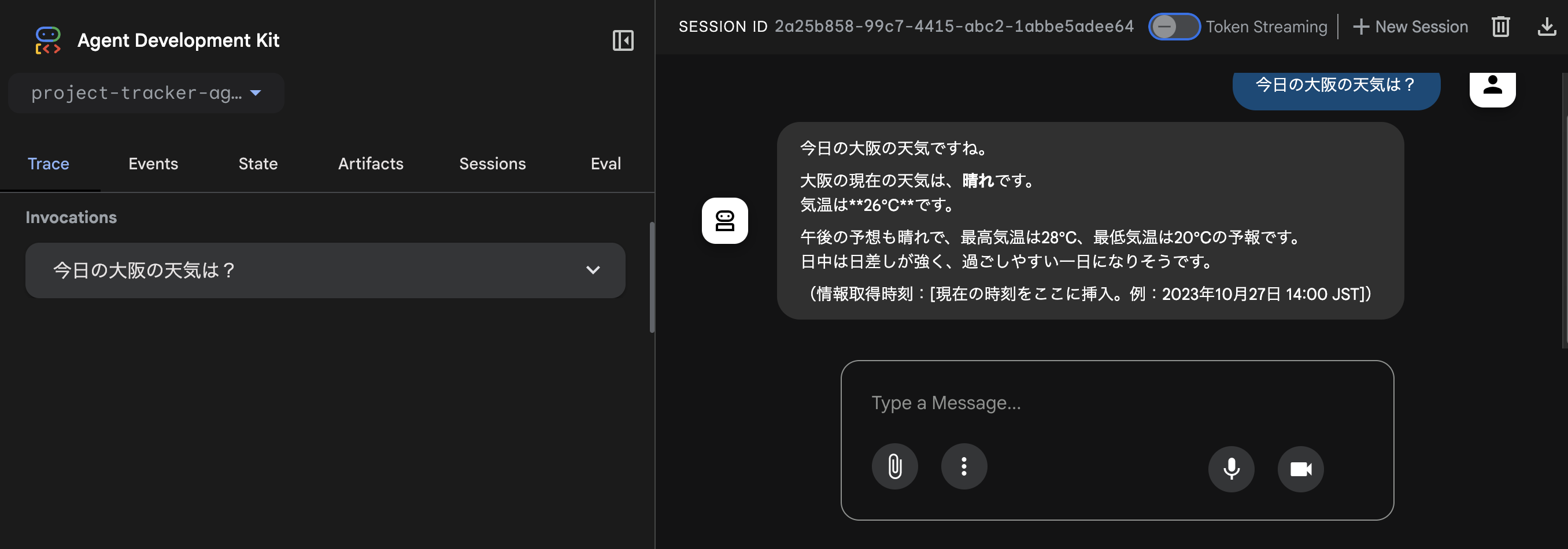
この状態だとMCPと接続していないので、agent.pyを以下に書き換えます。
from google.adk.agents import Agent
from toolbox_core import ToolboxSyncClient
toolbox = ToolboxSyncClient("http://127.0.0.1:5000")
tools = toolbox.load_toolset('project-tracker-toolset')
root_agent = Agent(
model="gemini-2.5-flash",
name="project-tracker-agent",
description=(
"社内プロジェクトの進捗状況やタスク情報を把握し、担当者ごとの工数や進捗サマリを回答するエージェント。"
),
instruction=(
"あなたは社内プロジェクト管理を支援するエージェントです。"
"ユーザーからの質問に基づき、BigQueryの project_tracker データセットにある"
"projects / tasks / v_tasks_with_project を参照して回答してください。"
"必ず提供されたツール(tools.yamlで定義されたツールセット)を使って、"
"プロジェクト別の進捗、担当者別工数、タスクの詳細や期日などを検索し、"
"その結果に基づいて回答を生成してください。"
),
tools=tools,
)もう一度起動してみます。
adk web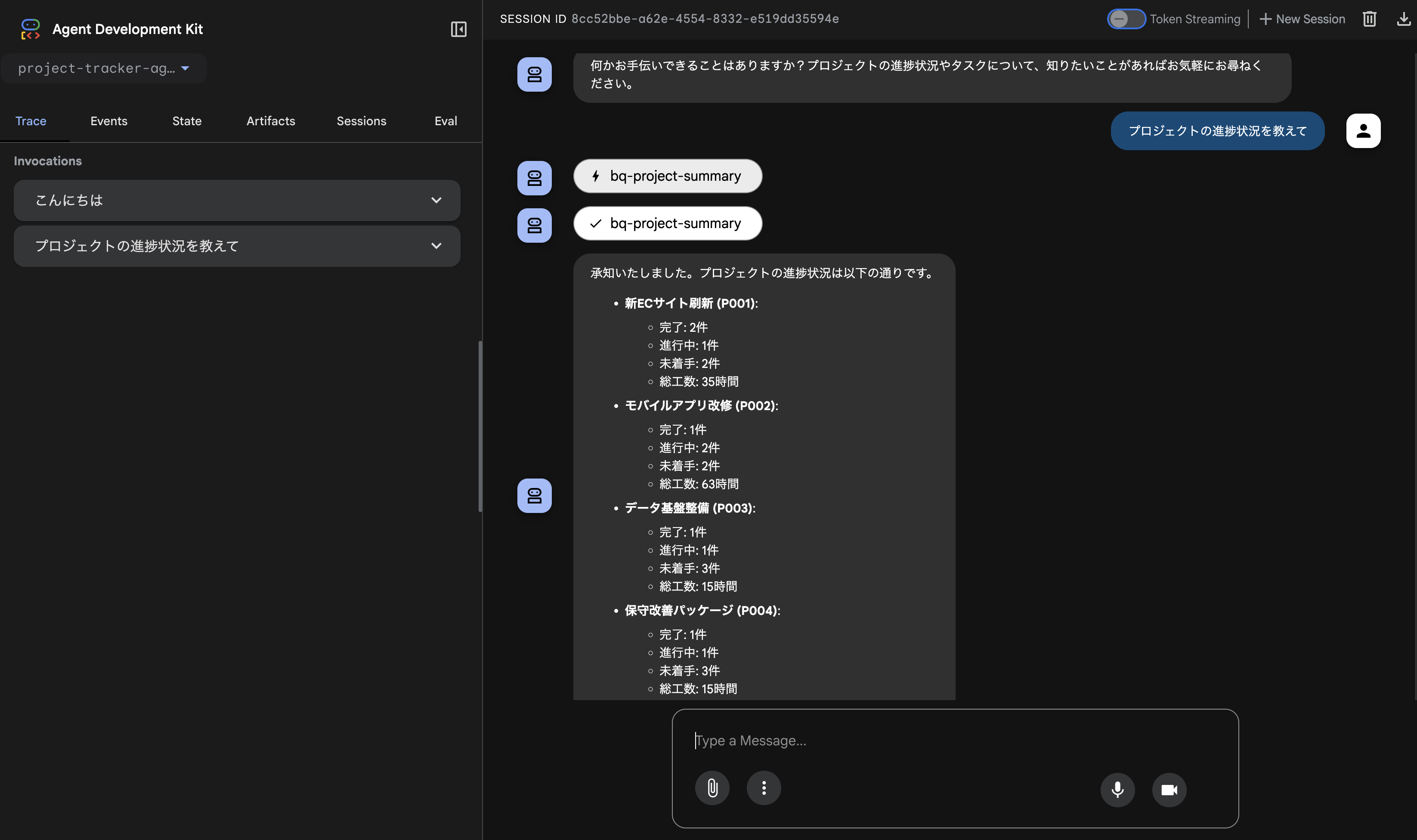
CLIモードで実行も可能です。
adk run project-tracker-toolset以下のような結果になりました。
[user]: 2025年8月の未完了 タスクを教えて
[project_tracker_agent]: 2025年8月の未完タスクは以下の通りです。
**進行中のタスク:**
* **要件定義** (プロジェクト: P001, 担当: 高橋, 終了日: 2025-08-12)
* **API設計** (プロジェクト: P002, 担当: 伊藤, 終了日: 2025-08-15)
* **ログイン機能実装** (プロジェクト: P002, 担当: 鈴木, 終了日: 2025-08-18)
* **単体テスト** (プロジェクト: P003, 担当: 鈴木, 終了日: 2025-08-18)
* **軽微修正対応** (プロジェクト: P004, 担当: 鈴木, 終了日: 2025-08-18)
**未着手のタスク:**
* **DB設計** (プロジェクト: P002, 担当: 佐藤, 終了日: 2025-08-14)
* **詳細設計** (プロジェクト: P001, 担当: 伊藤, 終了日: 2025-08-17)
* **DWH設計** (プロジェクト: P003, 担当: 高橋, 終了日: 2025-08-20)
* **ETL設計** (プロジェクト: P003, 担当: 伊藤, 終了日: 2025-08-21)
* **インフラ準備** (プロジェクト: P001, 担当: 山本, 終了日: 2025-08-22)
* **監視設定** (プロジェクト: P003, 担当: 佐藤, 終了日: 2025-08-22)
* **結合テスト** (プロジェクト: P002, 担当: 高橋, 終了日: 2025-08-25)
* **リリース準備** (プロジェクト: P004, 担当: 伊藤, 終了日: 2025-08-25)
* **ユーザトレーニング** (プロジェクト: P004, 担当: 高橋, 終了日: 2025-08-28)
* **運用マニュアル更新** (プロジェクト: P004, 担当: 山本, 終了日: 2025-08-29)おわりに
MCP Toolbox for Databasesを使うことで、データベースへのアクセスを安全に統制しつつ、あらかじめ定義したクエリや分析を「ツール」として簡単に提供できる強みを実感できました。さらに、ADKを組み合わせることで、複雑な設定なしにエージェントを素早く立ち上げ、自然言語でのやり取りをすぐに試せる手軽さも体験できました。
この仕組みは、今回のプロジェクト進捗管理に限らず、営業支援や顧客管理、監視運用など幅広い業務に応用可能です。ぜひ、MCP Toolbox for Databasesの強みとADKの手軽さを活かして、自分たちのユースケースに合わせたエージェントを試してみてください。
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。