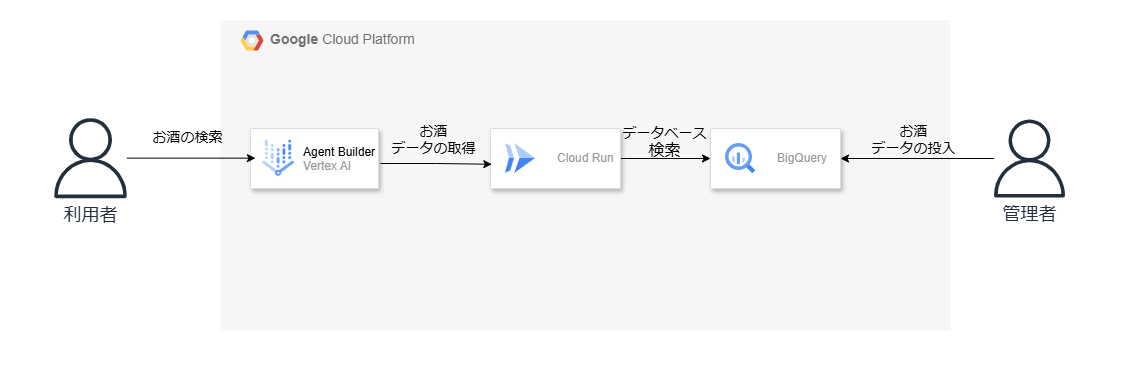
VertexAI Agent BuilderとBigQueryを使ったRAG
Vertex AI Agent Builder でおすすめのお酒を紹介してくれるチャットボットを作ってみた。
Table of contents
はじめに
去年ぐらいから生成AIがめちゃくちゃ加熱してきていて、日々良いサービスが出てきています。
Google Cloudでも同様に良いサービスが出てきており、BigQueryをベクトルDBとして使うためのサービスや、生成AIのAgentを作成してくれるものがあります。
そこで、それらを使ったらどんなことができるのだろう?という知的好奇心から、それらを使っておすすめのお酒を教えてくれるチャットボットを作成してみました。
使っている技術
サービス
- VertexAI Agent Builder
- BigQuery
- Cloud Run
- Gemini for Google Workspace(データ作成)
言語
- Python(Flask)
Vertex AI Agent Builderのいいところ
ユースケースごとに、AIがどんな挙動をしてほしいのかExampleとして定義できます。
Geminiがよしなに言い回しを変えてくれるのでチャットボットとして向いています。
作ってみよう
データを作ろう
今回Gemini for Google Workspaceの機能の1つである、サイドパネルを使用して、テストデータを作成しました。
以下がプロンプトです。
以下の項目で商品のテスト用の表を作成してください。
商品の種類は200種類です。
・項目
商品ID 商品名 種類 原材料 詳細分類 産地 メーカー 容量 アルコール度数 価格 在庫数 説明 仕入れ価格 仕入れ日 販売開始日 蔵元情報 ヴィンテージ(〇or✖) 保存方法 おすすめの飲み方 受賞歴・テストデータの生成のイメージ
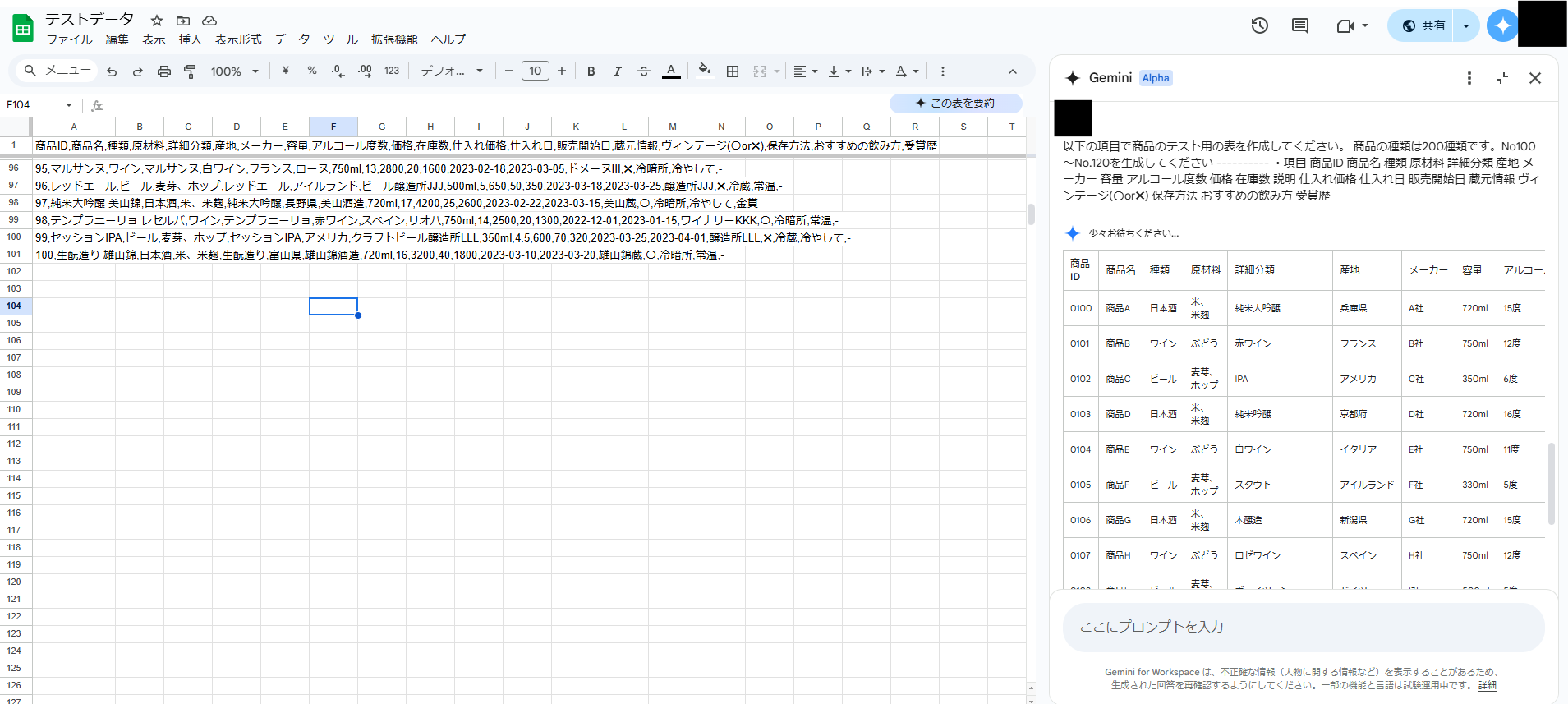
・データの一部抜粋

BigQueryにデータを登録しよう
Gemini for Google Workspaceでスプレッドシートに作ったデータを使って、BQのデータを登録します。
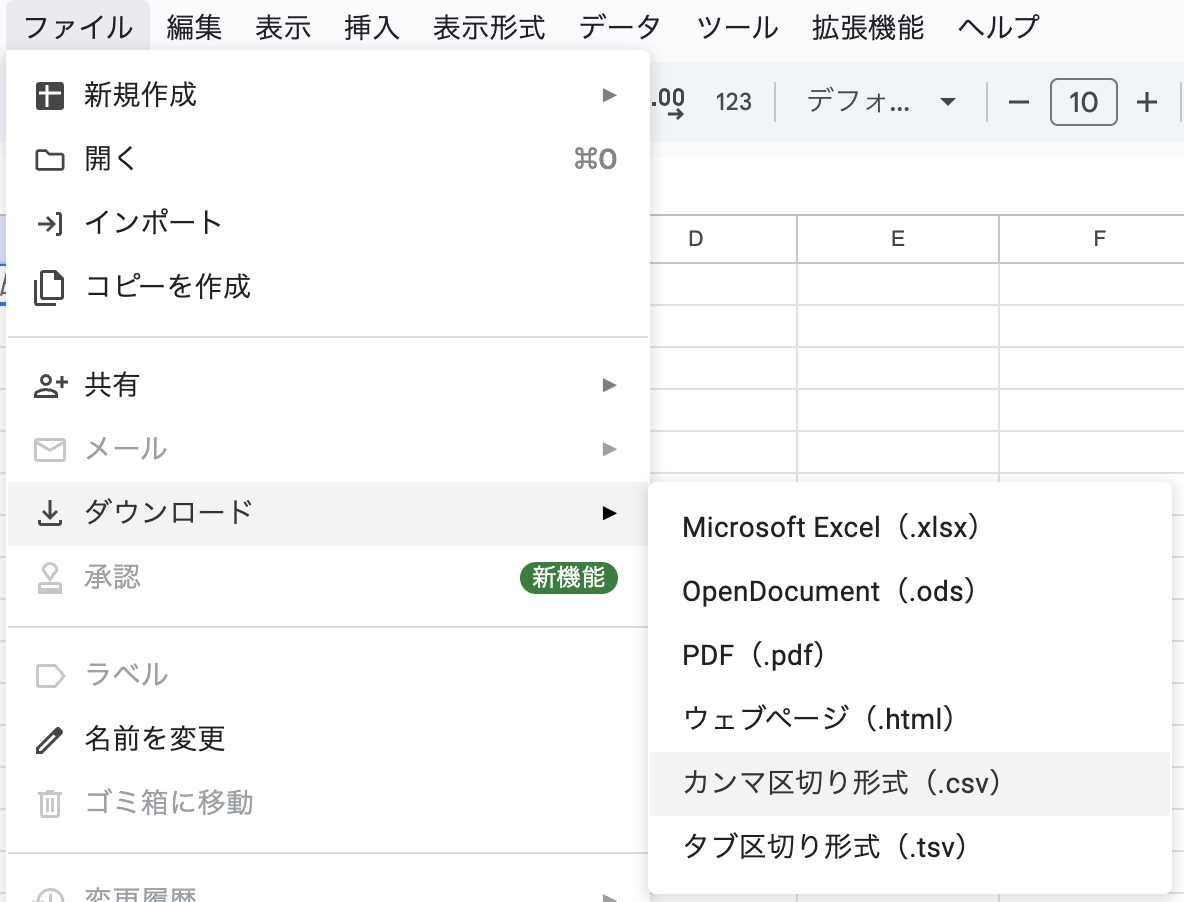
SpreadSheetなので、そのままCSVを出力します。
メニュー > ファイル > ダウンロード > カンマ区切り形式(.csv)
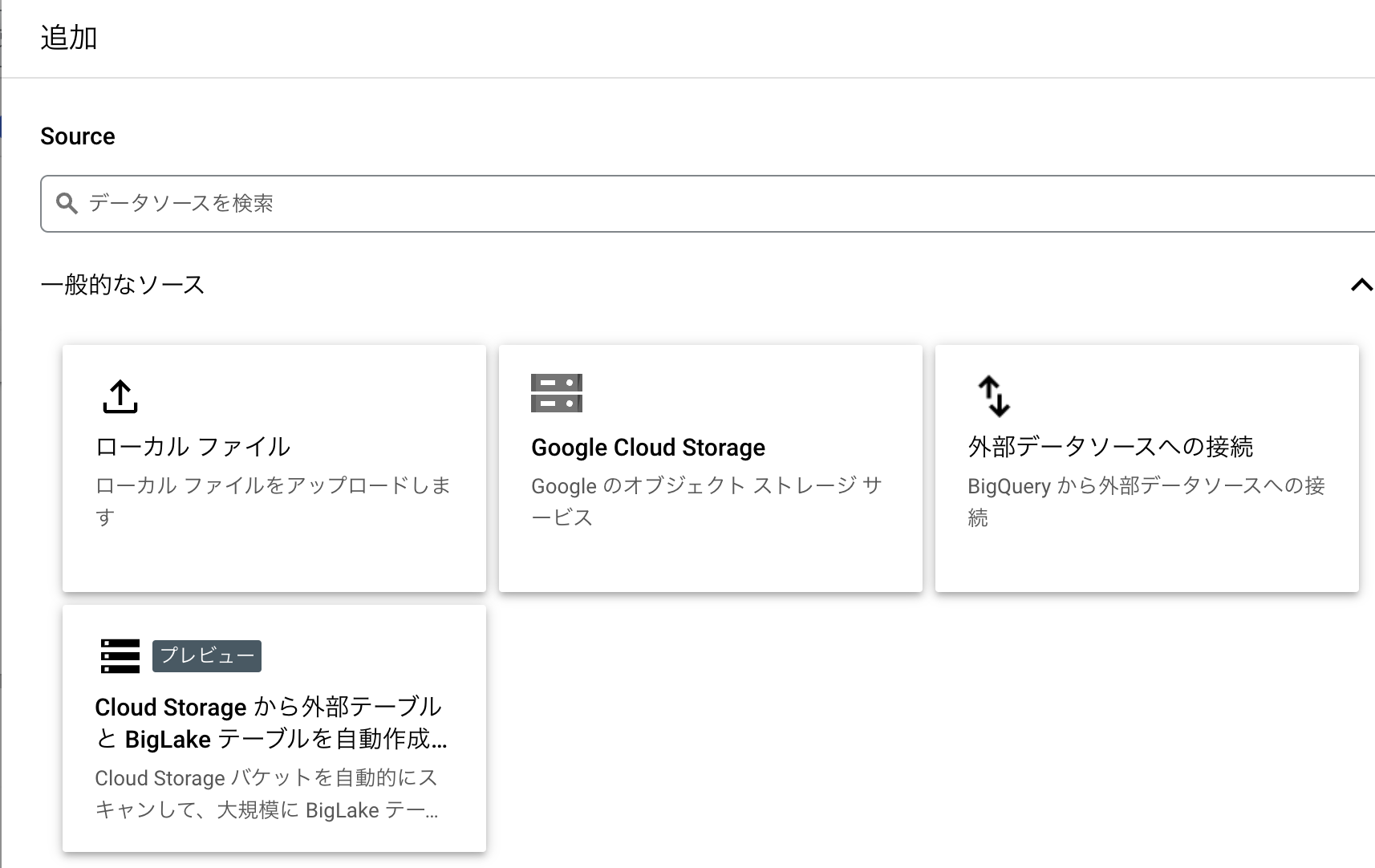
CSVをダウンロード後、BigQueryにテーブルとして取り込みます。
+追加 > ローカルファイル > テーブルを作成
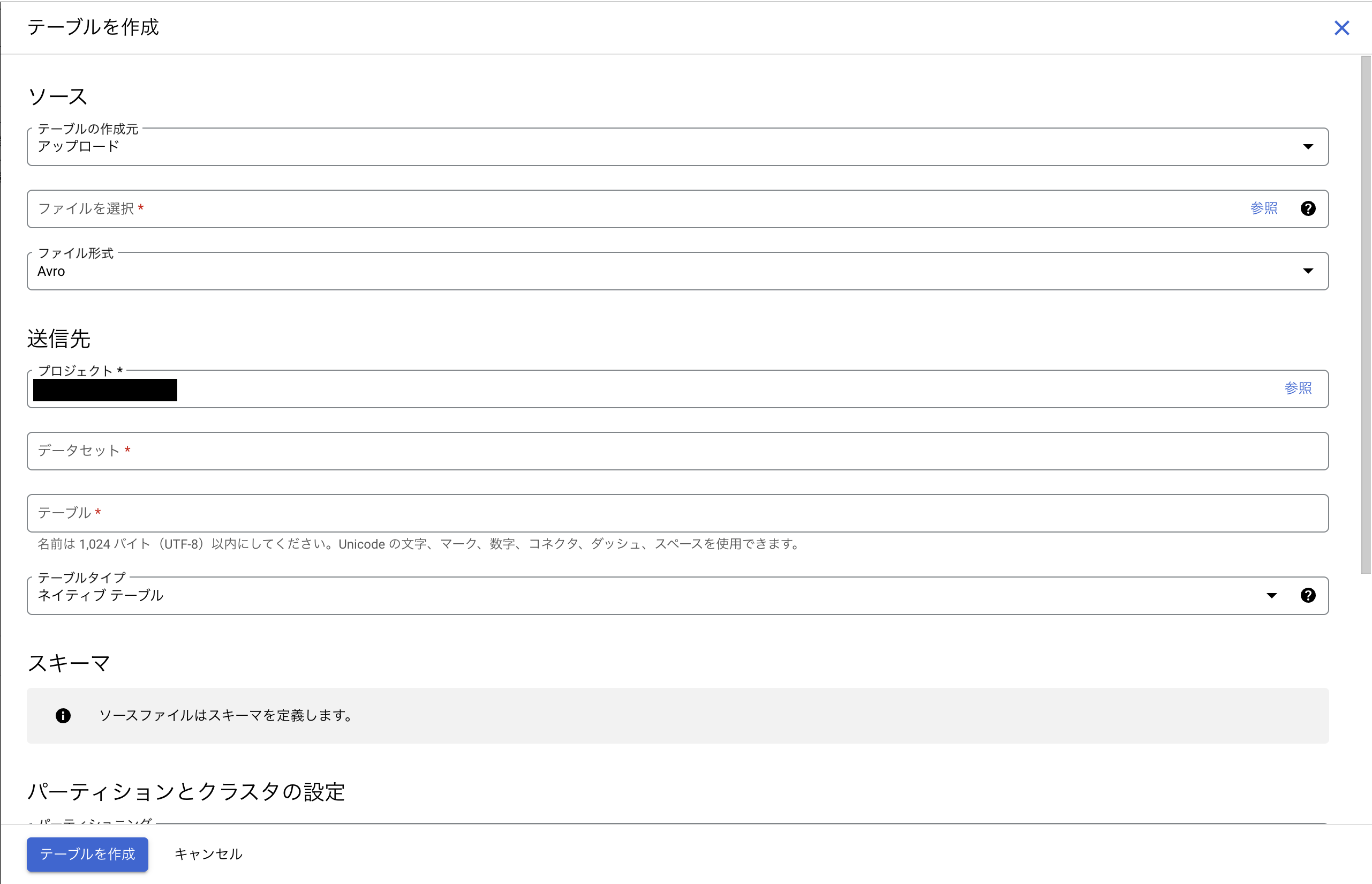
テーブルを作成では、必要な内容等入力してテーブルを作成します。

次にBQでEmbeddingするためのリモート関数とMLモデルを作成します。
以下シェルで実行します。
$ PROJECT_ID=<適宜プロジェクトIDを設定>
$ REGION=us
$ CONNECTION_ID=<適宜コネクションIDを設定>
■コネクション作成
$ bq mk --connection --location=$REGION --project_id=$PROJECT_ID \
--connection_type=CLOUD_RESOURCE $CONNECTION_ID以下BigQueryのQuery画面で実行します。
-- ■モデル作成
CREATE MODEL `<PROJECT_ID>.<DATASET_NAME>.textembedding-gecko-multilingual`
REMOTE WITH CONNECTION `<PROJECT_ID>.us.<CONNECTION_ID>`
OPTIONS(ENDPOINT = 'textembedding-gecko-multilingual@001')次にテスト用に作成したお酒のデータをEmbeddingします。
-- Embeddingデータ生成
WITH text_embedding_table AS (
SELECT *
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `<PROJECT_ID>.<DATASET_NAME>.textembedding-gecko-multilingual`, -- 使用するテキストエンベディングモデル
(SELECT product_id, CONCAT(product_name,' ',product_type,' ',ingredients,' ',category,' ',origin,' ',manufacturer,' ',volume,' ',alcohol_content,' ',price,' ',stock_quantity,' ',purchase_price,' ',purchase_date,' ',sales_start_date,' ',brewery_information,' ',vintage,' ',storage_method,' ',serving_suggestion,' ',awards) AS content FROM `test_dataset_kobatake.sake-raw`), -- エンベディングを生成するテキストデータ
STRUCT(TRUE AS flatten_json_output) -- 出力をフラットなJSONとして返す設定
)
)
-- メインのSELECT文
SELECT
main.*, -- sampleDataテーブルの全列を選択
text_embedding_table.text_embedding AS target_text_embedding -- 生成されたテキストエンベディングを追加
FROM text_embedding_table -- テキストエンベディングテーブルを結合
INNER JOIN `<PROJECT_ID>.<Embedding元テーブル名>` AS main -- 元テーブルに別名"main"を付けて結合
ON text_embedding_table.product_id = main.product_id -- エンベディングを生成したテキストデータで結合ここまででお酒データをEmbeddingしたデータを生成できるので、できたデータを確認したら次に進みます。
APIサーバーたてよう
Pythonのコードは以下です。
from flask import Flask, jsonify, request
import json
from google.cloud import bigquery
import os
# 環境変数からプロジェクトID、テキストエンベディングモデル、商品テーブルを取得
PROJECT_ID = os.environ.get("PROJECT_ID", "YOUR_PROJECT_ID")
TEXT_EMBEDDING_MODEL = os.environ.get("TEXT_EMBEDDING_MODEL", "YOUR_PROJECT_ID.YOUR_DATASET_ID.textembedding-gecko-multilingual")
PRODUCT_TABLE = os.environ.get("PRODUCT_TABLE", "YOUR_PROJECT_ID.YOUR_DATASET_ID.sake-embedding")
app = Flask(__name__)
app.config["JSON_AS_ASCII"] = False
@app.route('/', methods=['POST'])
def index():
# リクエストからユーザーメッセージを取得
postedData = request.data.decode('utf-8')
postedData = json.loads(postedData)
user_message = postedData["search"]
print(f"user_message: {user_message}")
# 商品を検索
results = search_products(user_message)
# 検索結果からコンテキストを生成
context = generate_product_context(results)
return jsonify({"text": context}), 200
def search_products(query):
# BigQueryクライアントを作成
client = bigquery.Client(project=PROJECT_ID)
print(f"クライアントの作成成功")
# 商品検索のクエリを定義
query_job = client.query(
f"""
WITH embedded_text AS (
SELECT *
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `{TEXT_EMBEDDING_MODEL}`,
(SELECT "{query}" AS content),
STRUCT(TRUE AS flatten_json_output)
)
)
SELECT
base.product_id,
base.product_name,
base.product_type,
base.ingredients,
base.category,
base.origin,
base.manufacturer,
base.volume,
base.alcohol_content,
base.price,
base.stock_quantity,
base.purchase_price,
base.purchase_date,
base.sales_start_date,
base.brewery_information,
base.vintage,
base.storage_method,
base.serving_suggestion,
base.awards,
distance
FROM VECTOR_SEARCH(
TABLE `{PRODUCT_TABLE}`,
'target_text_embedding',
(SELECT text_embedding FROM embedded_text),
top_k => 3,
distance_type => 'COSINE',
OPTIONS => '{{"use_brute_force":true}}'
)
ORDER BY distance ASC
"""
)
print(f"query_job: {query_job}")
# クエリを実行し、結果をデータフレームに変換
results = query_job.to_dataframe().to_dict("records")
print(f"results: {results}")
return results
def generate_product_context(results):
product_info = []
# 検索結果から商品情報を抽出
for row in results:
print(f"row: {row}")
product_info.append(
f"商品ID:{row['product_id']},商品名:{row['product_name']},種類:{row['product_type']},原材料:{row['ingredients']},詳細分類:{row['category']},産地:{row['origin']},メーカー:{row['manufacturer']},容量:{row['volume']},アルコール度数:{row['alcohol_content']},価格:{row['price']},在庫数:{row['stock_quantity']},仕入れ価格:{row['purchase_price']},仕入れ日:{row['purchase_date']},販売開始日:{row['sales_start_date']},蔵元情報:{row['brewery_information']},ヴィンテージ(〇or✖):{row['vintage']},保存方法:{row['storage_method']},おすすめの飲み方:{row['serving_suggestion']},受賞歴:{row['awards']}"
)
# 商品情報を改行で結合
context = "\n".join(product_info)
print(f"context: {context}")
return context
if __name__ == "__main__":
app.run(debug=False, host='0.0.0.0', port=8080)
Cloud RunへのDeployコマンドは以下です。
$ gcloud run deploy YOUR_APPLICATION_NAME \
--project=YOUR_PROJECT_ID \
--region=us-central1 \
--allow-unauthenticated \
--source=. \
--execution-environment=gen2 \
--port=8080OpenAPIのYamlは以下です。
openapi: 3.1.0
info:
title: Product Recommendations API
version: v1
servers:
- url: "CLOUD_RUN_URL"
paths:
/:
post:
summary: Get product recommendations based on user query.
requestBody:
content:
application/json:
schema:
type: object
properties:
search:
type: string
description: User message containing the search query.
example: "おすすめの日本酒はありますか?"
responses:
"200":
description: Successful response with product recommendations.
content:
application/json:
schema:
type: object
properties:
text:
type: string
description: Product recommendations generated.Vertex AI Agent Builderでボットを作ろう
アプリの作成(コンソール操作)
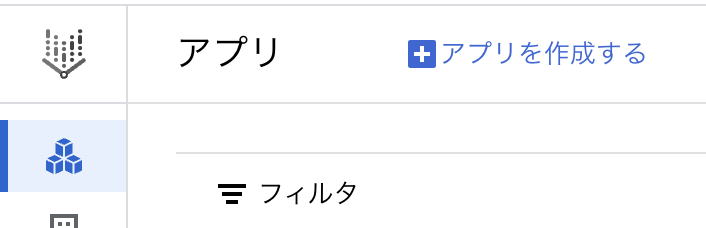
Agent Builderで検索をし、Agent Builderの画面を表示したら、「+アプリを作成する」をクリックします。
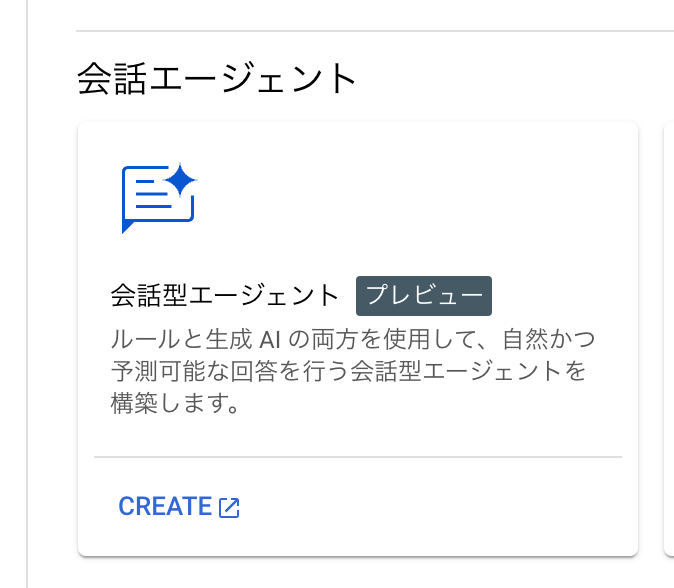
「+アプリを作成する」の画面から、会話エージェントを探し、「CREATE」ボタンをクリックします。
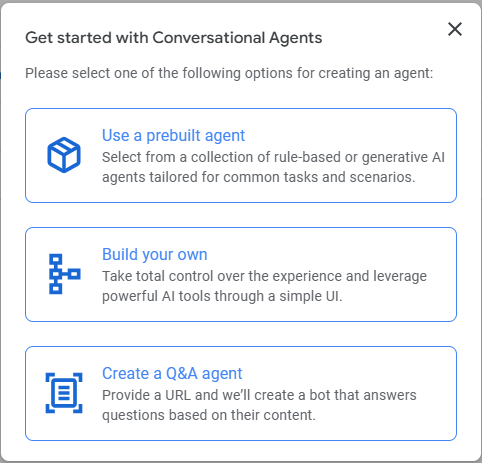
「Get started with Conversational Agents」の画面から「Build your own」を選択します。
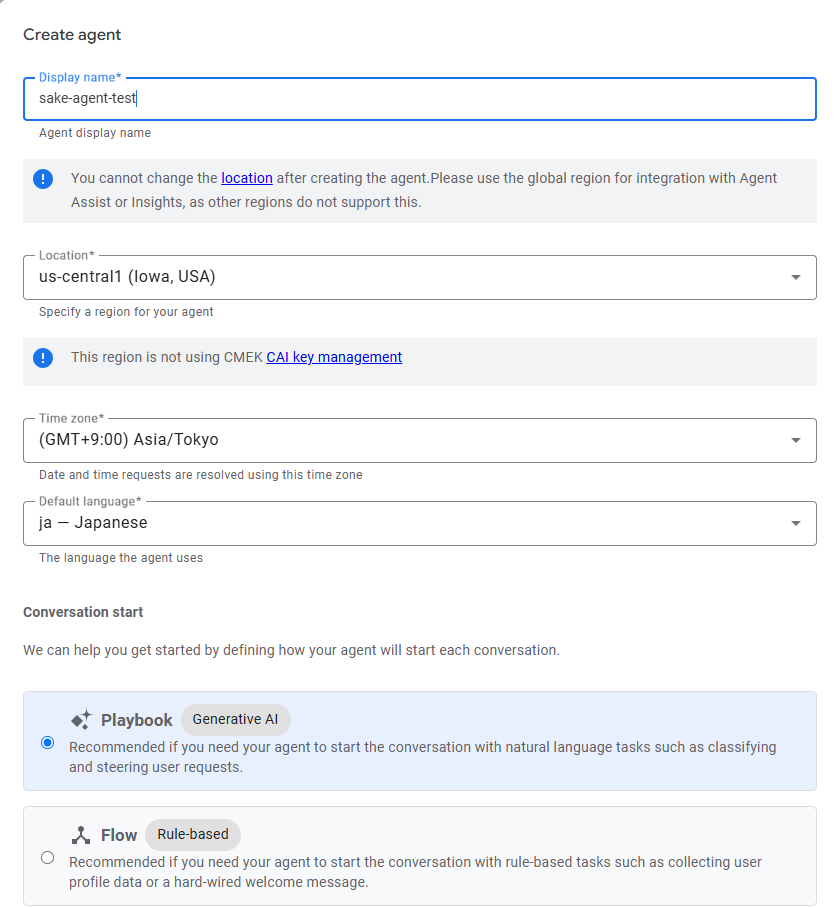
「Create agent」画面で、それぞれ以下のように設定値を入力し、Agentを作成します。
Agentを作成したら、Playbookの画面内で、「Basics」「Examples」を設定します。
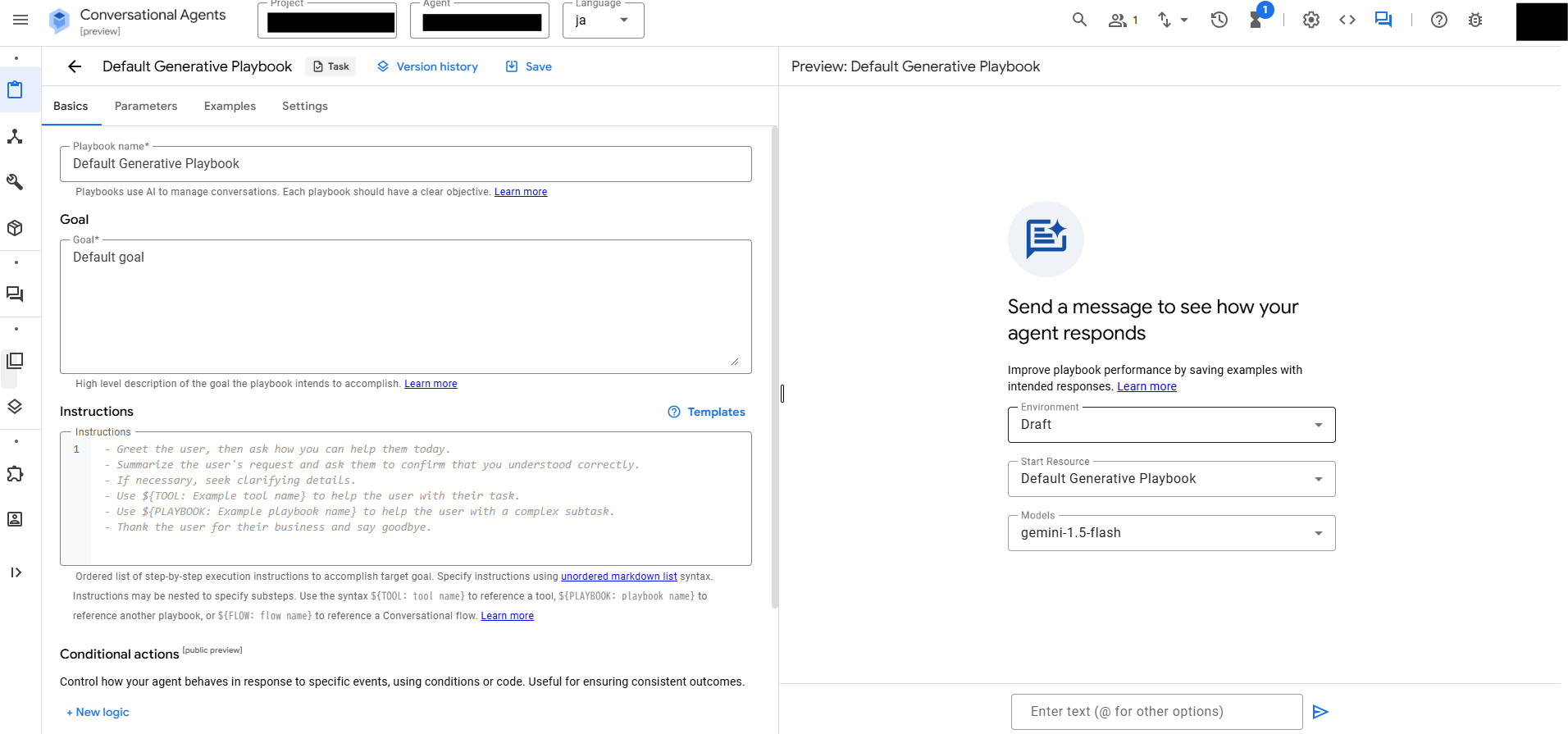
Playbooksの設定
まずは「Basics」から設定します。
■Goalについて
Goalは以下のように登録しました。
Recommend alcoholic beverages tailored to user preferences, occasions, and dietary needs.■Instructionsについて
Googleのドキュメントによると、Instructionsの中身には以下を定義する必要があると記載がありました。
- LLMが理解できる基本的な指示。
- ユーザーを別のプレイブックにルーティングする指示。プレイブックは、フォームを使用して参照されます ${PLAYBOOK: playbook_name}。
- 特定のプレイブック ツールを使用するための指示。ツールは、 という形式を使用して参照されます ${TOOL: tool_name}。
- ユーザーを会話エージェント (Dialogflow CX) フローにルーティングする指示。フローは、フォームを使用して参照されます ${FLOW: flow_name}。
会話型エージェントでは、Playbook・Tool・Flowで各機能や、返答の仕方を決めることができます。
以下のGoogleのドキュメントでは、1つのブッキングのシステムとしてAgentを1つ作成し、プレイブックで飛行機のブッキング・ホテルのブッキング等を分ける例が記載されていました。
- greet the customer and ask them how you can help.
- If the customer wants to book flights, route them to ${PLAYBOOK: flight_booking}.
- If the customer wants to book hotels, route them to ${PLAYBOOK: hotel_booking}.
- If the customer wants to know trending attractions, use the ${TOOL: attraction_tool} to show them the list.
- help the customer to pay for their booking by routing them to ${FLOW: make_payment}.今回作成するお酒用のAgentでは1つのAgentでツールの切り替えは実装していません。
以下が今回使用したInstructionsです。
- Please provide all responses in Japanese.
- Please connect the product name and product details with spaces and use ${TOOL:sake-search} to search.
- Please create a recommendation message for the user using the product information obtained from the search.Toolsの設定
登録したToolは以下です。
Agentが応答時に使うToolを登録します。
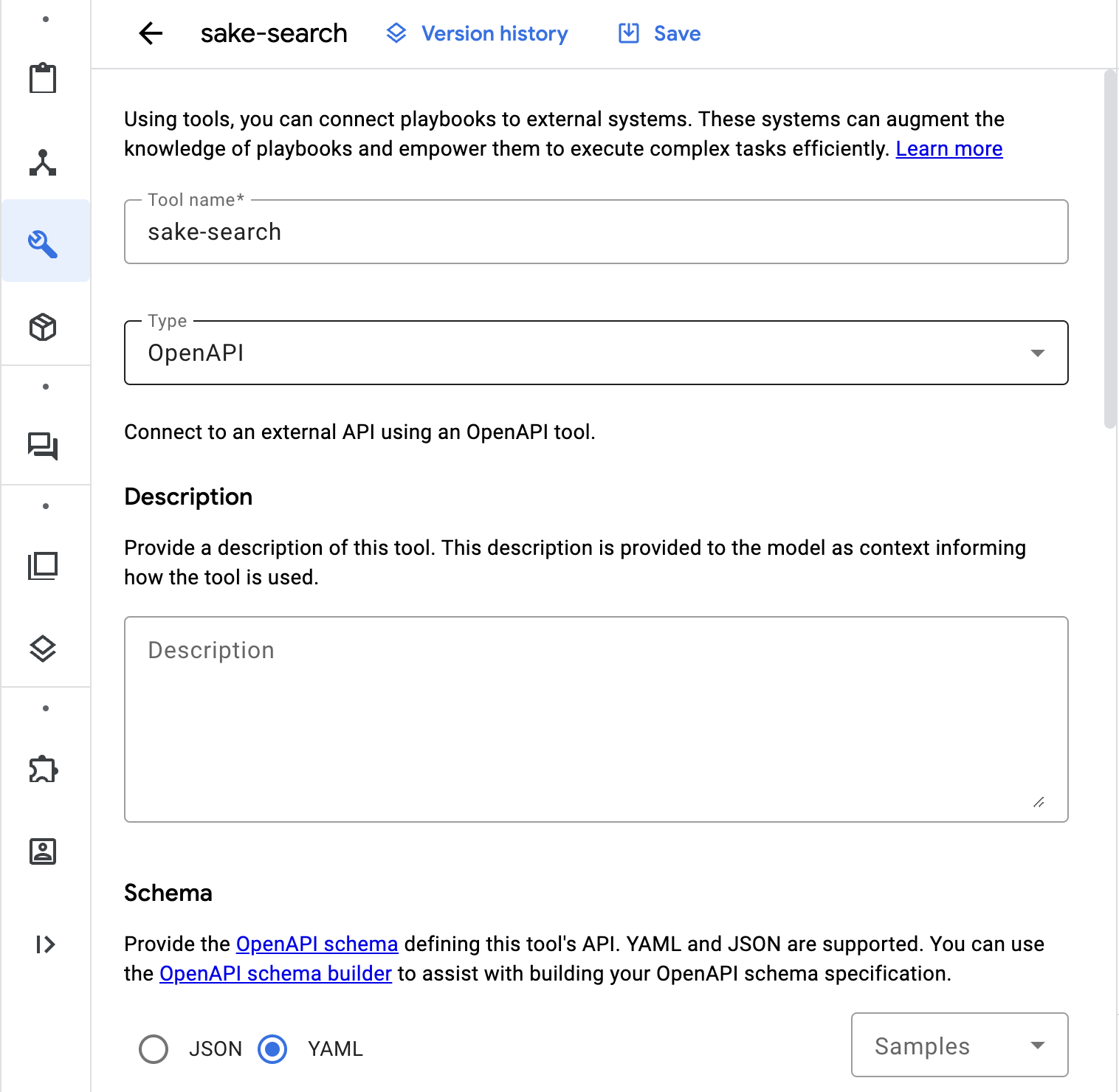
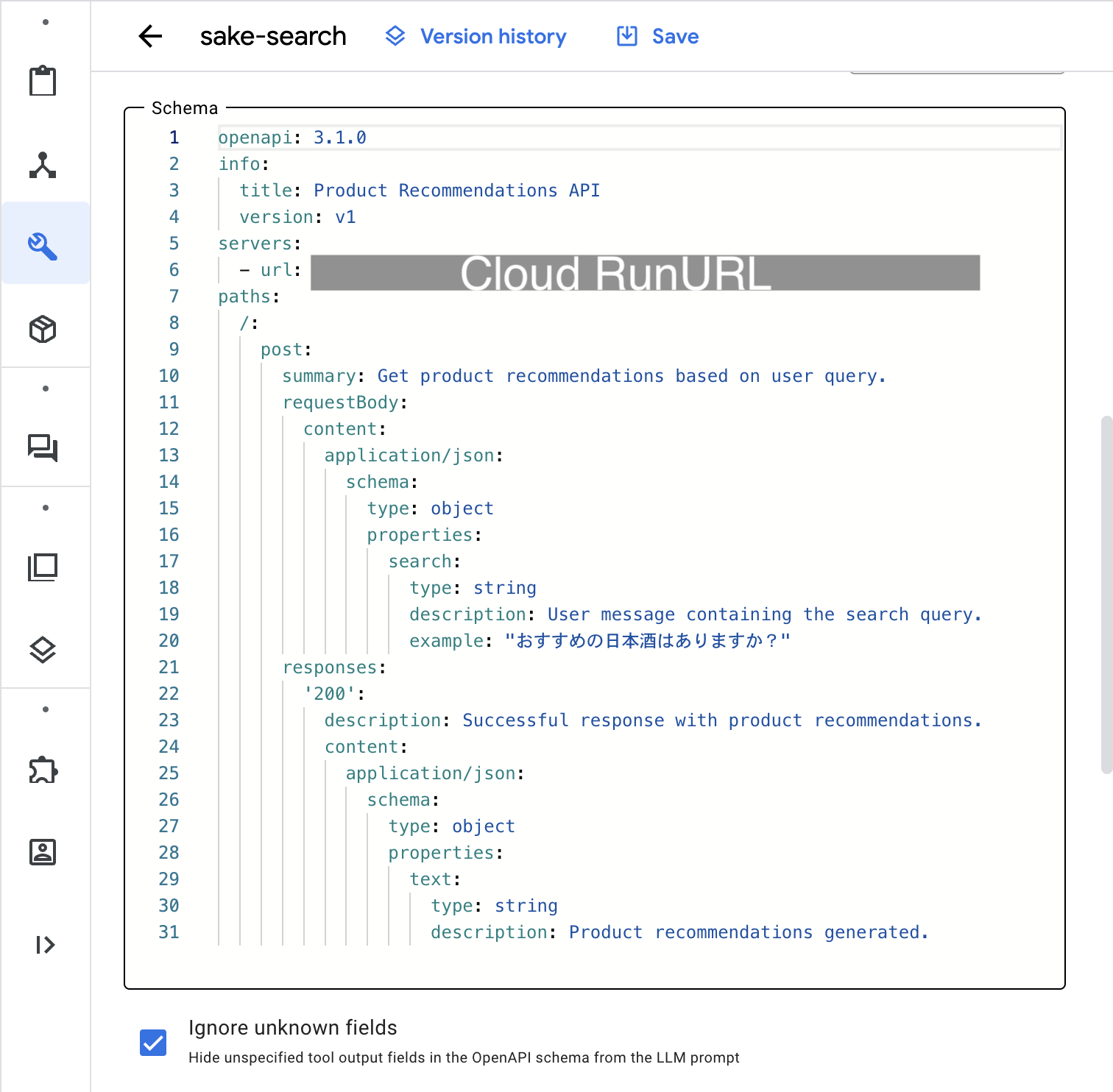
 Tool nameを入力し、SchemaのところでYamlを選択し、APIの作成のときに一緒に作成している、OpenAPIのYamlを貼り付けて登録します。
Tool nameを入力し、SchemaのところでYamlを選択し、APIの作成のときに一緒に作成している、OpenAPIのYamlを貼り付けて登録します。
Examplesの設定
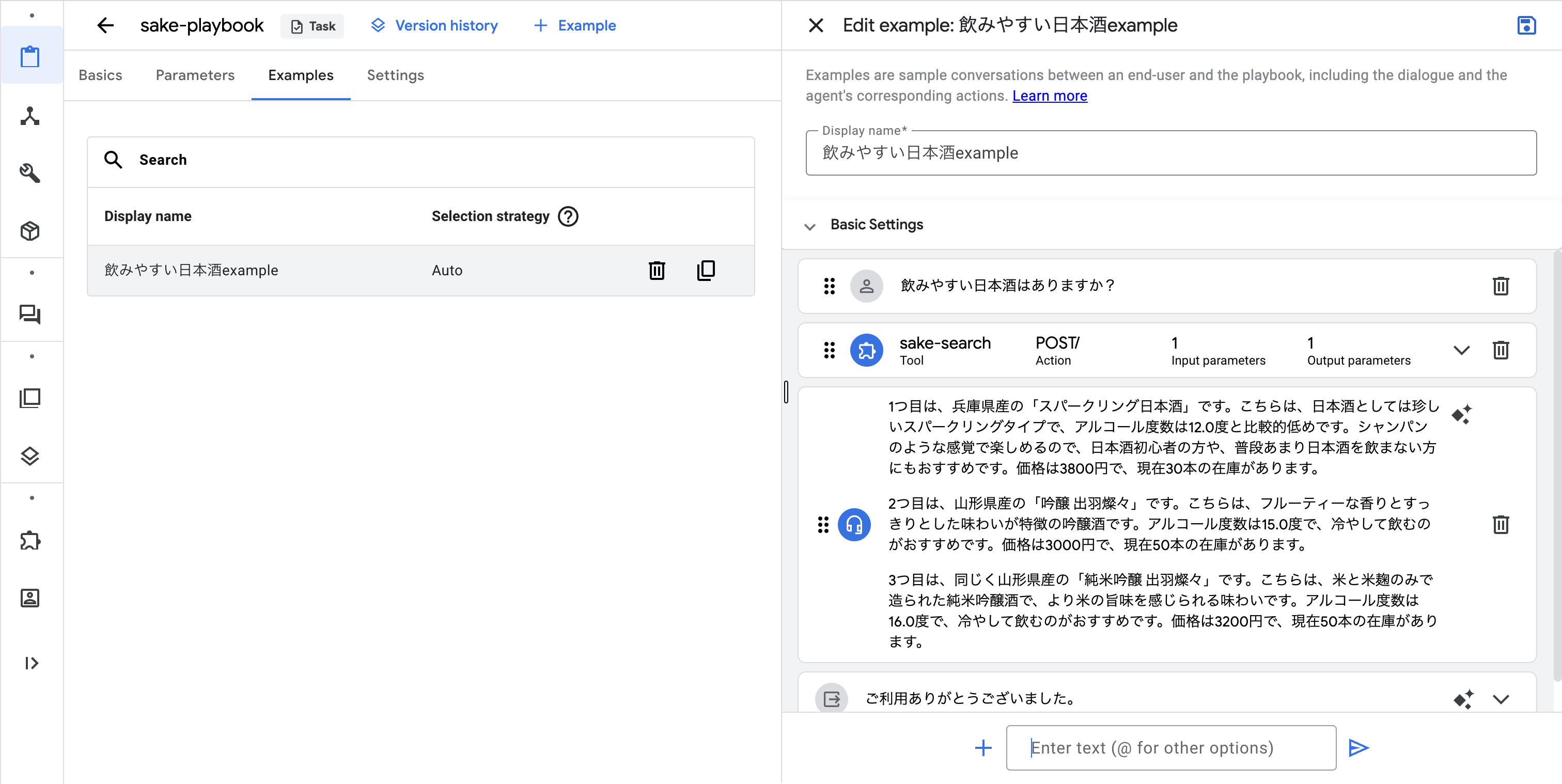
登録したExampleは以下です。
Exampleとして自然言語を使ってどういう流れでAgentに応対して欲しいかを作成します。
ユーザ入力>入力からツールに問い合わせ>問い合わせ結果でおすすめ文章生成>締めの言葉
という流れのExampleです。
ポイントとしては、ExampleにあるToolから問い合わせのところで、この前ステップで作成しているToolを指定しています。
なお、Exampleを複数作ることで自動的に色々なパターンにも対応できるようになります。
(今回は1つだけのExampleを紹介しています)
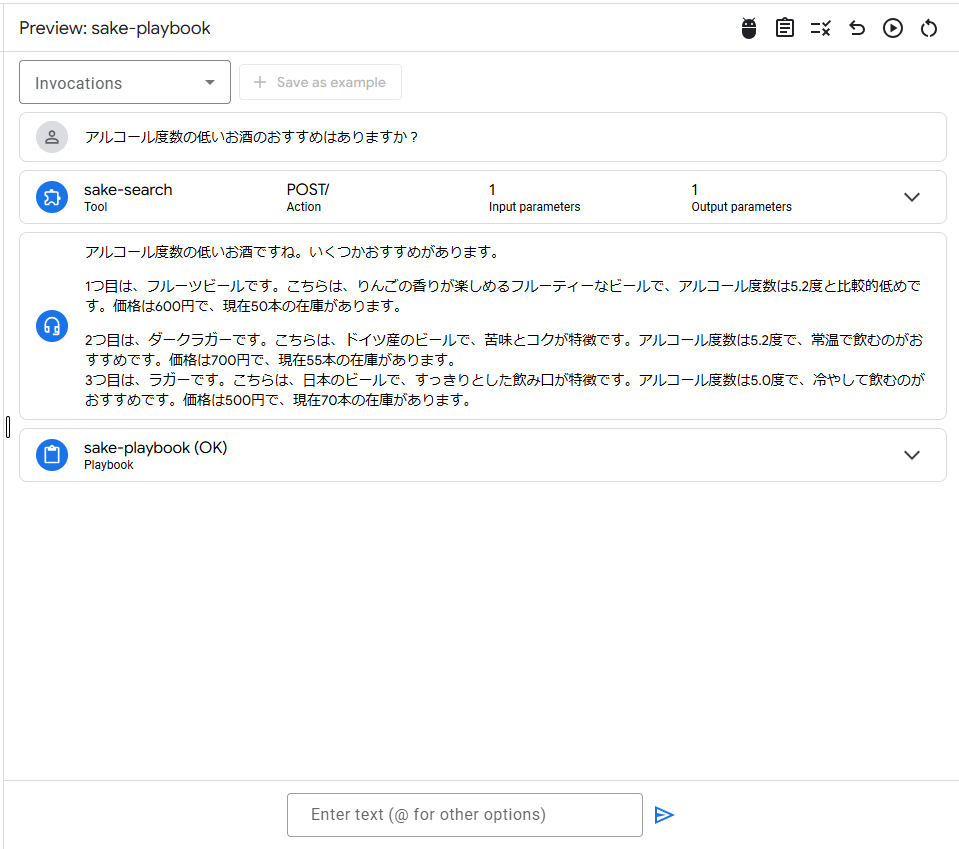
動作確認
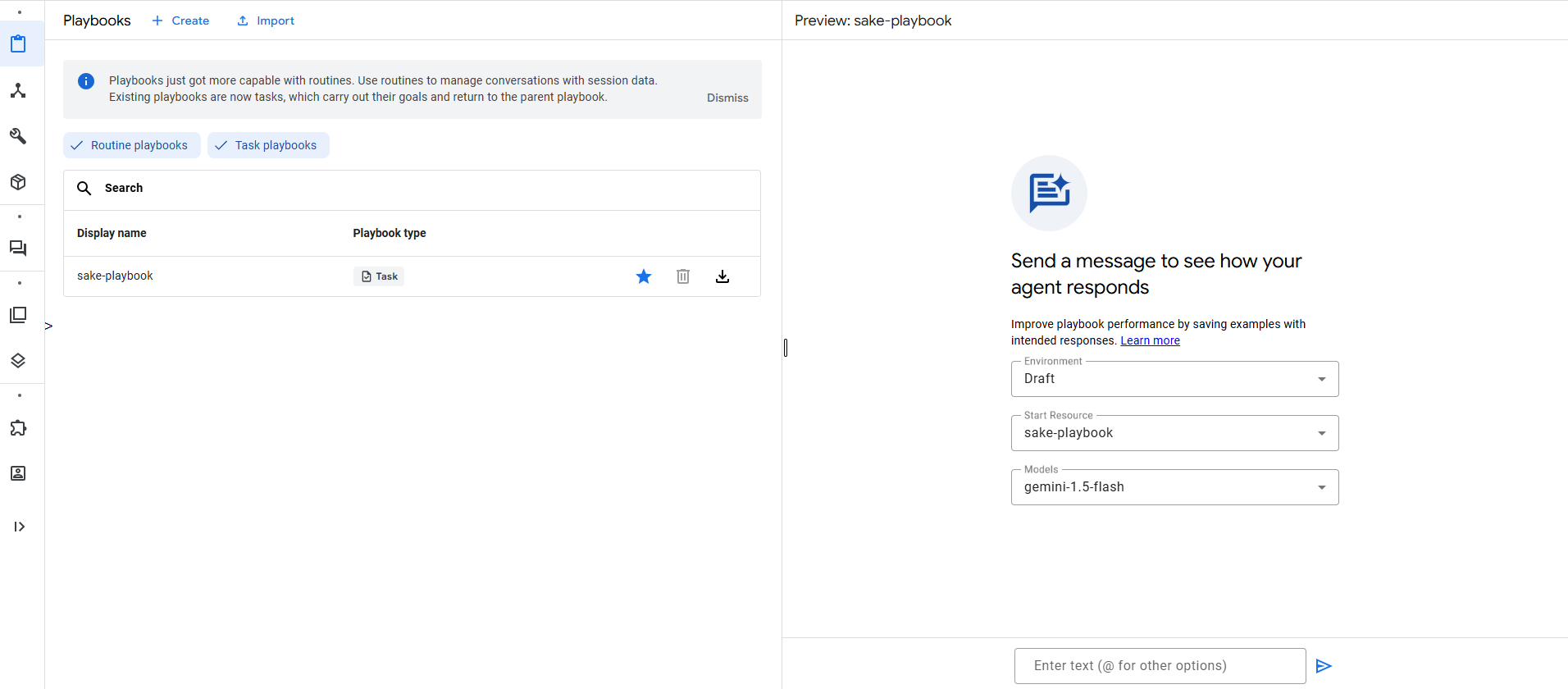
ユーザーからの問い合わせを入力し、送信すると以下のようにレスポンスデータをもとにGeminiが整理したデータが表示されました。
Geminiを開発に活用するナレッジ
-
テストデータの作成方法
サイドパネルのGeminiでは、一度に出力できるトークン数に上限があるため、200種類のお酒データを一度に生成することが困難でした。
そのため、20種類ずつ段階的に作成することで対応しました。(まず200種類を作成することを指定したうえで、No.1からNo.20までのデータを生成し、その後新たなプロンプトとしてNo.21からNo.40までのデータを生成する。) -
テストデータの抜けがあることの気づき
Geminiを使ってデータを作る際、トークン数に上限があるため、情報が不完全になることがあります。その後の処理に影響があることがあるため、生成したデータを度々確認することをお勧めします(特にデータの末尾)。 -
OpenAPIのYaml作成
Geminiを使って原型となるYamlを作成しています。
そのあと人間の目で確認しながらYamlを修正しています。 -
Exampleの作成
APIを作成して動作確認をするところまでは特につまづきはなかったですが、Agent Builderから使えるようになるまで試行錯誤しています。
ToolのSchemaは定義していますが、PlaybookのExampleで問い合わせする際のリクエストの形式をきちんと指定しないとエラーになるような感じでした。
Agentで呼んでくれているかがわかりづらいので、Cloud Loggingも確認しています。
最後に
Vertex AI Agent Builderを使うことで、簡単にチャットボットを開発できることが分かりました。BigQueryとの連携もスムーズで、大規模なデータに基づいたAIエージェントを構築するのに最適です。
Geminiの自然言語処理能力により、ユーザーとの会話も非常にスムーズに行えます。
今回の例では、お酒に特化したチャットボットを作成しましたが、応用次第で様々な分野での活用が期待できます。例えば、旅行プランの提案や、レストランの予約など、アイデア次第で無限の可能性が広がります。
Agent Builderは、AI技術を手軽にビジネスに導入するための強力なツールだと感じました。
参考ページ
https://blog.g-gen.co.jp/entry/semantics-and-ranking-search-with-bigquery
https://cloud.google.com/dialogflow/cx/docs
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。