Geminiで英語ブログを要約→和訳→Slack投稿。最新情報にお手軽キャッチアップする
Google Cloudの英語ブログを要約→和訳してSlackに投稿する簡単なPythonアプリを作ります。
Table of contents
author: Shintaro
はじめに
Dataチームの森本です。
弊社はGoogle Cloudに特化したSIerです。
そのため、英語で発信されるプロダクトのアップデートなど最新情報のキャッチアップが欠かせません。
Google Cloud運営のブログは日本語記事も豊富ですが、
基本的にはまず英語で投稿された後、若干のタイムラグを経て日本語版の記事が出る(出ないものもある)という流れです。
弊社ではGoogle CloudブログのRSSフィードから情報を取得して
Slackに自動投稿されるようにしていますが、私は英語が得意ではありません。
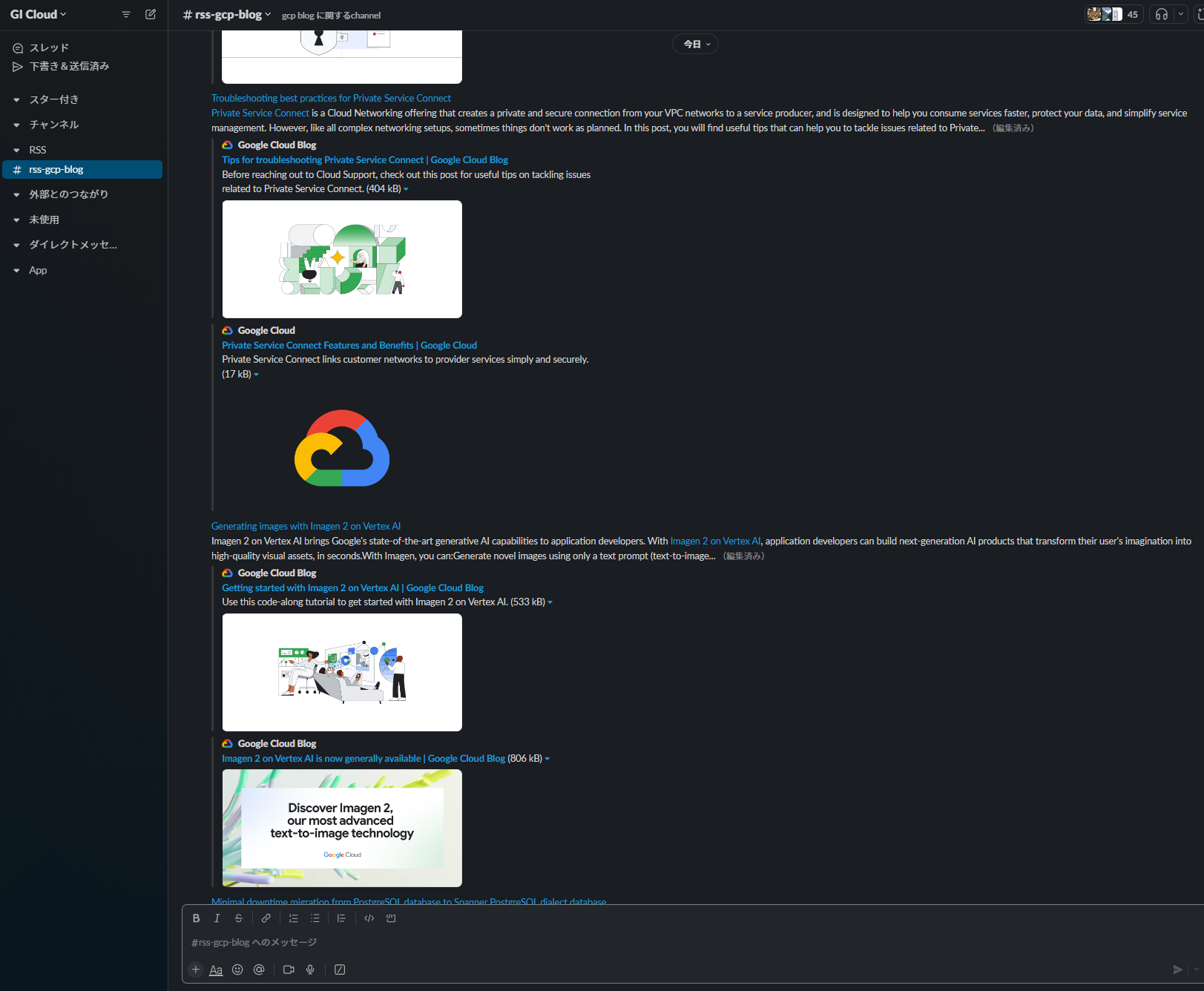
最新ブログの投稿が流れてきても、「おっこれは面白そうな(自分と関係がありそうな)内容だ」と瞬時に判断できず、
結果として、あまり英語ブログには目が通せていない状況になってしまっています。
(SNSのタイムラインなどを見ていて、興味のない話題は日本語でも目に入ってこない感覚です。伝われ。)
そこで、新規投稿される英語ブログの内容を
3行に要約→日本語化→Slackに投稿する
という簡単なアプリを作ってみたので、ご紹介します。ざっくりと以下の流れで進めます。
- Slackの設定と必要情報の取得
- Cloud Storageバケットの作成、ファイルの保存
- コード記述
- コンテナ化→Artifact Registryに保存
- Cloud Schedulerで定期実行
※Google Cloudのプロジェクトはすでに作成済みとします。
Slackの設定と必要情報の取得
Slackに関して必要なことを進めていきます。
APIの有効化、トークンの取得
わかりすやい記事があったので、参照ください。
Slack API を使用してメッセージを投稿する
xoxp-から始まるBot User OAuth Tokenの取得まで行い、メモして戻ってきてください。
のちほど環境変数として使用します。
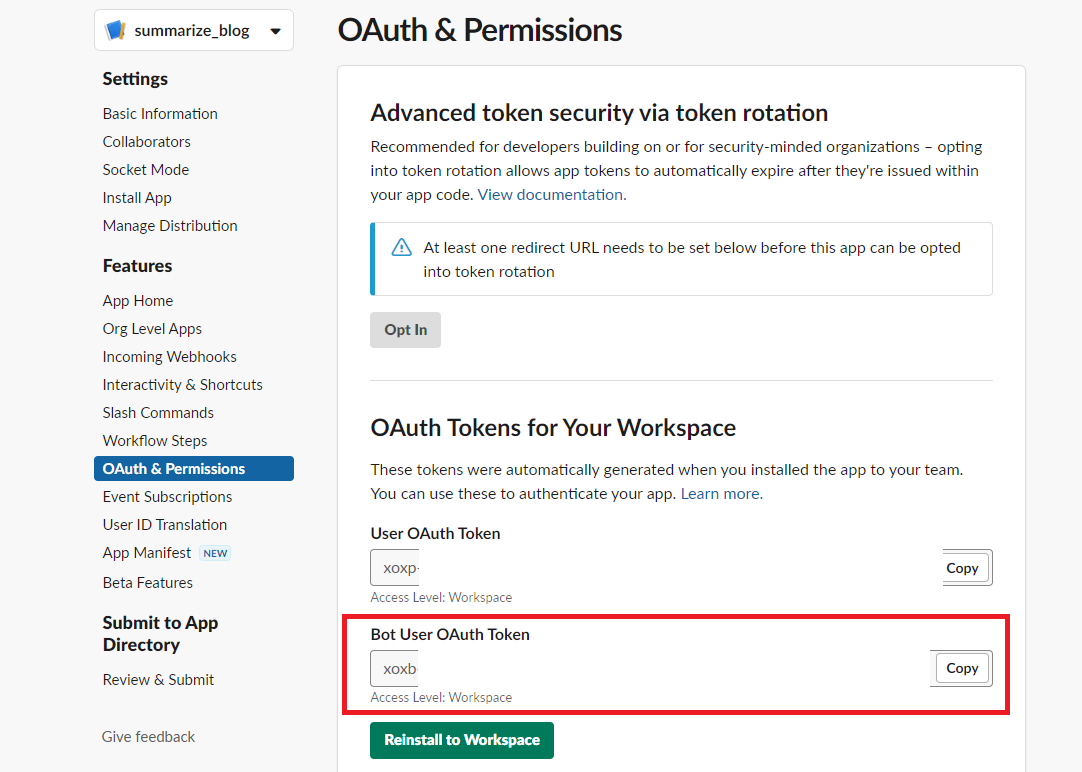
メンバーIDの取得
Slack上の自身のプロフィールから取得できます。こちらもメモしてください。
Cloud Storageバケットの作成、ファイルの保存
Cloud Storageでバケットを作成し、適当な名前の空の.txtファイルを作成→保存してください。
※公開アクセスはオンにしないでください。
バケット名とファイル名をメモしておいてください。
コード記述
適当なところに新しくフォルダを作成し、ファイルを作成していきます。
(今回の記事ではローカル実行しないので、それに関する説明は省きます。)
main.pyに以下のコードを記述します。
import feedparser
import requests
import os
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from slack_sdk import WebClient
from fastapi import FastAPI
from google.cloud import storage
import vertexai
from vertexai.preview.generative_models import GenerativeModel
load_dotenv()
project_id = os.environ["PROJECT_ID"]
location = os.environ["LOCATION"]
slack_token = os.environ["SLACK_TOKEN"]
slack_client = WebClient(token=slack_token)
slack_member_id = os.environ["SLACK_MEMBER_ID"]
bucket_name = os.environ["BUCKET_NAME"]
file_name = os.environ["FILE_NAME"]
feed_url = "https://cloudblog.withgoogle.com/rss/"
parsed_feed = feedparser.parse(feed_url)
def initialize_vertexai(project_id, location):
vertexai.init(project=project_id, location=location)
def initialize_storage(bucket_name, file_name):
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
return blob
def read_urls_from_storage(blob):
try:
content = blob.download_as_text()
return set(content.strip().split("\n"))
except storage.blob.NotFound:
return set()
# htmlからtitleとbody、URLを取得
def extract_entry_info(entry):
html_bytes = requests.get(entry.link).content
extracted_url = requests.get(entry.link).url
soup = BeautifulSoup(html_bytes, "html.parser")
body_content = soup.body.get_text()
return extracted_url, body_content
# テキスト要約&日本語化
def summarize_text(input_text):
prompt = f"""
Summarize "Input text" in 3 bullet points and translate it into Japanese.
Each bullet points should be a maximum of 150 characters.
Focus on Google Cloud products.
I want ONLY Japanese text.
Example output:
- summary of Input text1
- summary of Input text2
- summary of Input text3
Input text: {input_text}
"""
config = {
"temperature": 0,
"max_output_tokens": 300,
"top_p": 0,
"top_k": 1,
}
gemini_pro_model = GenerativeModel("gemini-1.0-pro")
responses = gemini_pro_model.generate_content(
prompt, generation_config=config, stream=True
)
response_list = []
for response in responses:
response_list.append(response.text)
response_join = ",".join(response_list)
return response_join
def write_urls_to_storage(blob, extracted_urls, existing_urls):
# 重複しない新しいURLのみを追加
new_urls = set(extracted_urls) - existing_urls
if new_urls:
# 新しいURLを追記
new_content = "\n".join(existing_urls.union(new_urls))
blob.upload_from_string(new_content)
return new_urls
app = FastAPI()
@app.get("/")
def main():
initialize_vertexai(project_id, location)
blob = initialize_storage(bucket_name, file_name)
existing_urls = read_urls_from_storage(blob)
extracted_urls = []
# フィードにあるURLを取得
for entry in parsed_feed.entries:
extracted_url = requests.get(entry.link).url
extracted_urls.append(extracted_url)
# 未取得のURLのみをCloud Storageに追記
added_urls = write_urls_to_storage(blob, extracted_urls, existing_urls)
# 未取得のURLのみ処理を実行
for added_url in added_urls:
for entry in parsed_feed.entries:
extracted_url, body_content = extract_entry_info(entry)
if added_url == extracted_url:
print("summarizing...")
summarized_text = summarize_text(body_content)
post_text = (
"新しい記事が投稿されました!"
+ "\n\n"
+ "■記事の要約\n"
+ summarized_text
+ "\n\n"
+ "原文URL: "
+ extracted_url
)
# スラックでのメッセージ送信
slack_client.chat_postMessage(channel=slack_member_id, text=post_text)
return {"status": "OK"}
if __name__ == "__main__":
main()処理の流れ
ざっくりとした流れは以下の通りです。
- Cloud Storageから、これまで取得してきたフィードのURLを取得(初回の場合はない)
- RSSフィードのブログ記事URLと、Cloud Storageから取得したURLの重複を確認
- 重複していないブログ記事URLの本文を順番に要約→日本語化
- Slackに投稿
- 投稿したブログ記事のURLをCloud Storageに保存
プロンプトとパラメータについても記載するか迷ったのですが、
記事が長くなってしまうので、また別で記事を書く予定です。
次にrequirements.txtを作成し、以下をコピペします。
annotated-types==0.6.0
anyio==4.2.0
beautifulsoup4==4.12.2
bs4==0.0.1
cachetools==5.3.2
certifi==2023.11.17
charset-normalizer==3.3.2
click==8.1.7
colorama==0.4.6
fastapi==0.108.0
feedparser==6.0.11
google-api-core==2.15.0
google-auth==2.25.2
google-cloud-aiplatform==1.38.1
google-cloud-bigquery==3.14.1
google-cloud-core==2.4.1
google-cloud-resource-manager==1.11.0
google-cloud-storage==2.14.0
google-crc32c==1.5.0
google-resumable-media==2.7.0
googleapis-common-protos==1.62.0
grpc-google-iam-v1==0.13.0
grpcio==1.60.0
grpcio-status==1.60.0
h11==0.14.0
httptools==0.6.1
idna==3.6
numpy==1.26.2
packaging==23.2
proto-plus==1.23.0
protobuf==4.25.1
pyasn1==0.5.1
pyasn1-modules==0.3.0
pydantic==2.5.3
pydantic_core==2.14.6
python-dateutil==2.8.2
python-dotenv==1.0.0
PyYAML==6.0.1
requests==2.31.0
rsa==4.9
sgmllib3k==1.0.0
shapely==2.0.2
six==1.16.0
slack-sdk==3.26.1
sniffio==1.3.0
soupsieve==2.5
starlette==0.32.0.post1
typing_extensions==4.9.0
urllib3==2.1.0
uvicorn==0.25.0
watchfiles==0.21.0
websockets==12.0コンテナイメージ作成→Artifact Registryに保存
Dockerfile作成
Dockerfileを作成します。
FROM python:3.11.5-slim-bullseye
WORKDIR /app
COPY requirements.txt ./
RUN apt-get update \
&& pip install -r requirements.txt
COPY . ./
CMD [ "uvicorn", "main:app", "--host=0.0.0.0", "--port=8080"]Dockerイメージ作成
イメージ作成のコマンドを実行します。今回はblog-summarizeという名前のイメージを作成します。
docker image build -t blog-summarize .
Artifact Registryに保存
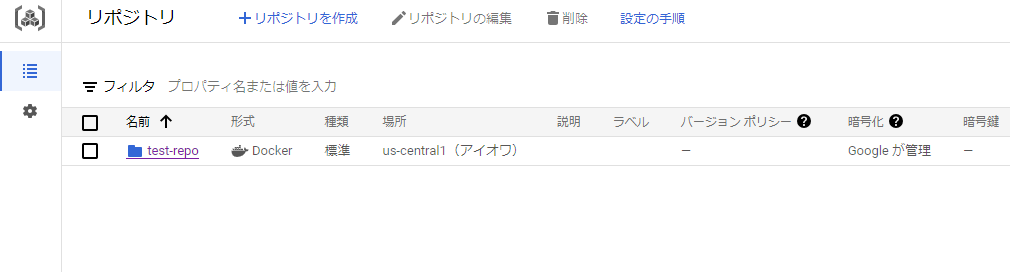
以下の手順で、作成したイメージをArtifact Registryにpushします。
-
Artifact Registryにリポジトリを作成※リポジトリ作成の手順は割愛します。
test-repoというリポジトリ名にします。 -
作成したイメージにタグ付け
docker tag blog-summarize us-central1-docker.pkg.dev/project_id/test-repo/blog-summarize
※locationとproject_idは各自で変更してください。 -
Artifact Registryにpush
docker push us-central1-docker.pkg.dev/project_id/test-repo/blog-summarize
※locationとproject_idは各自で変更してください。
※コマンドの詳細やリポジトリに対する認証などの手順は割愛します。詳しくは以下の公式ドキュメントなどをご覧ください。
イメージをpushおよびpullする
作成したリポジトリにイメージがプッシュされているのを確認してください。
Cloud Runへのデプロイ
先ほどpushしたイメージをCloud Runにデプロイします。イメージの画面から進めます。
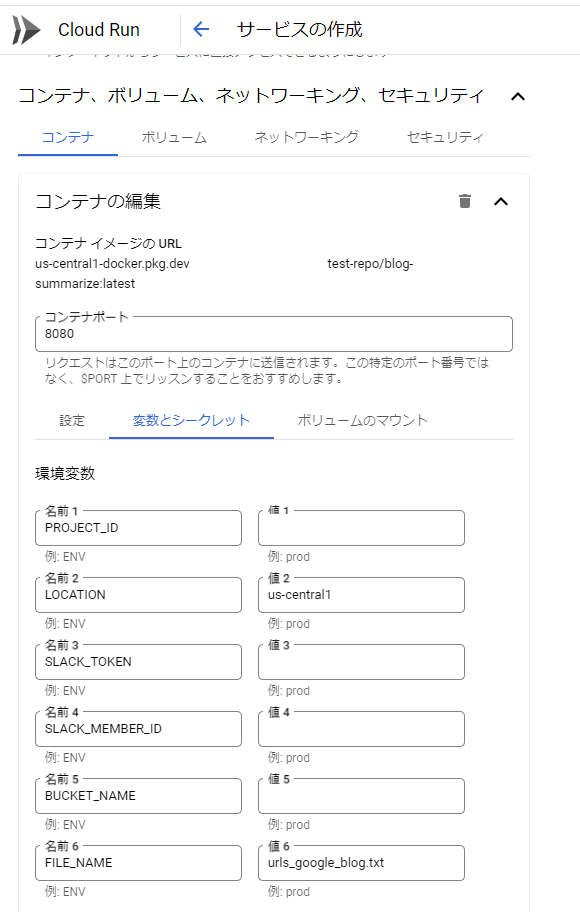
今回は、secretをCloud Runコンテナの環境変数として保存します。
発行したSlackのトークンやCloud Storageのバケット名などを入力してください。
説明の簡略化のため、Cloud Runプロキシを使用してサービスに接続します。
Cloud Run起動元(roles/run.invoker)のロールが付与されたユーザーで以下のコマンドを実行します。
gcloud run services proxy blog-summarize --project YOUR_PROJECT_ID --region REGION
curlでhttp://127.0.0.1:8000/を叩いてみましょう。
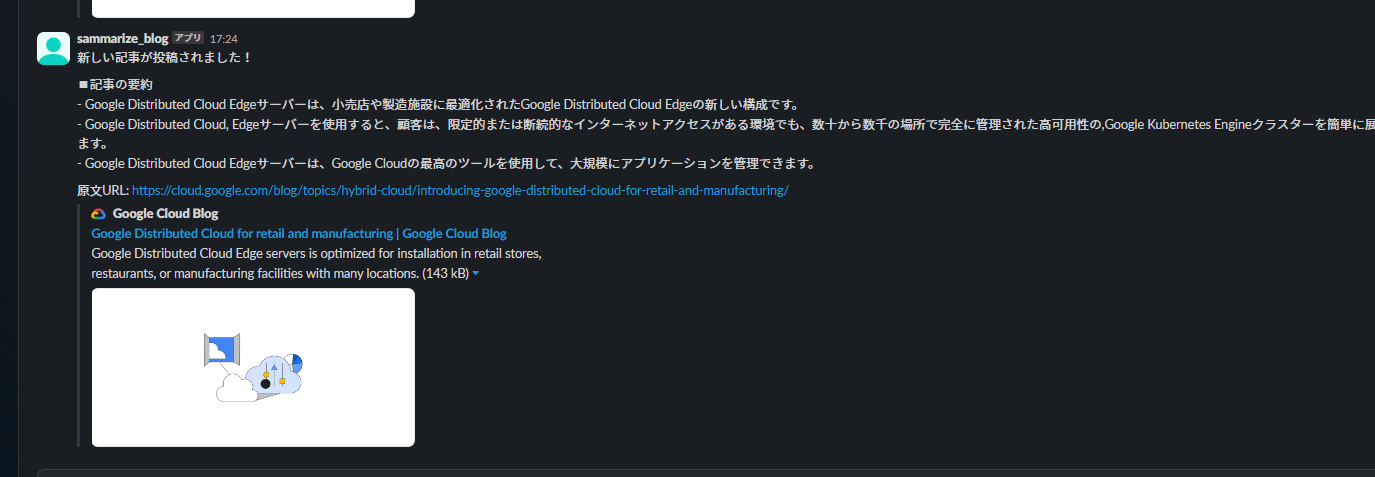
以下のようなメッセージがSlackに来ましたでしょうか?(トータルで10件くらいの通知が逐次きます。)
おわりに
今回設定したCloud RunサービスをCloud Schedulerで実行すれば、
Google Cloudの英語ブログが更新された際に自分個人あてに日本語版の要約が定期的に届くようになります。
※少しやり方を変えればチャンネルへの投稿も可能です。
※環境のクリーンアップは各自でお願いいたします。
LLMはチャットや検索などが注目されがちですが、
こういった地味な用途にも裾野がドンドン広がっていくとすると、
仕事の進め方を日々見直し続ける必要があるなとつくづく実感しますね。
余談
このアプリを作成したのが昨年11月くらいでGeminiが登場していなかったため、
もともとはPaLM2のtext-bison@002で作成してました。ただ、せっかくなので話題のGeminiを使ってみようと切り替えました。
PaLM2からGeminiに切り替えるための記事が用意されていて、切り替え自体はスムーズにいけました。
ただ、レスポンスがいくつかのオブジェクトに分かれて出力されるため、
まとまった1つのレスポンスとして表示させたい場合は若干の後処理が必要になりました。
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。