生成AI時代のデータ基盤に必要な「セマンティックレイヤー」入門
生成AI時代のデータ活用を成功に導く鍵「セマンティックレイヤー」。その役割と重要性、そしてそれにまつわる主要ツールを解説します。
Table of contents
author: Chiakoba
はじめに
こんにちは、企業内にデータは蓄積されているものの、その活用に課題を感じていませんか?
- 「欲しいデータがあっても、エンジニアに依頼しないと取り出せない」
- 「部署ごとに出てくるレポートで、同じ指標のはずなのに数字が合わない」
- 「そもそも、どのデータが信頼できる『正』なのかわからない」
こうした課題は、多くの組織で共通して聞かれる声です。 私自身も日々、悪戦苦闘しています。
そして、生成AIの登場により、「自然言語で対話するだけで、誰もがデータからインサイトを得られる」という未来が現実味を帯びてきました。
しかし、その実現には1つの大きな問いがあります。 AIは、データベースの 『構文(シンタックス)』 を処理できても、そのデータが持つ 『意味(セマンティック)』 をどうやって理解するのでしょうか?
本記事では、この問いに答える鍵となる「セマンティックレイヤー」に焦点を当て、なぜこれが生成AI時代のデータ戦略において不可欠な要素となるのかを、Google Cloudの主要なデータサービスや関連ツールと共に解説します。
1. データアクセスの進化と、そこに残された課題
データ活用の発展段階を振り返ると、共通の課題が見えてきます。
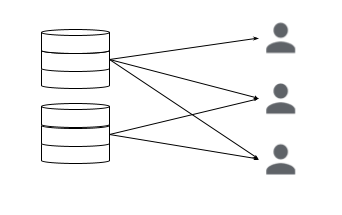
フェーズ1:属人化したクエリによる直接アクセス(SQL is King)
データウェアハウス(DWH)に蓄積された生データに対し、SQLが書ける一部の専門家が直接クエリを発行する段階です。個人の知識に依存するため、指標の定義が統一されず、組織的なデータ活用には繋がりにくいという課題があります。
フェーズ2:データマートによる標準化(Data Mart is King)
dbtなどのツールを用いて生データを加工・整理し、分析用途に最適化されたデータマートを構築する段階です。データの信頼性は向上しますが、依然として利用者はSQLスキルを求められるケースが多く、活用のハードルは残ります。
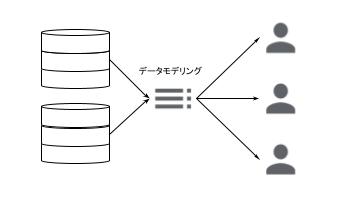
フェーズ3:ダッシュボードによる可視化
データマートを基に、BIツールでダッシュボードを構築し、多くのユーザーがSQLなしでデータを閲覧できる段階です。しかし、新たな分析軸や指標の追加要望が頻発すると、その都度データチームによる改修作業が発生し、運用負荷が増大するという課題が顕在化します。
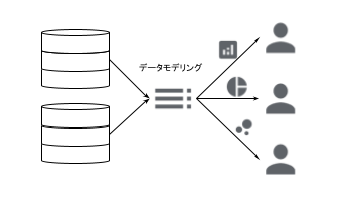
これらの課題を解決し、データ活用を次のステージへ進めるのが、セマンティックレイヤーと生成AIの組み合わせです。
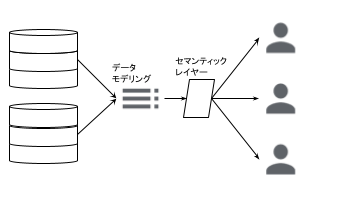
2. なぜ生成AIにセマンティックレイヤー(意味)を求めるのか
セマンティックレイヤーは、技術的なデータ構造とビジネス上の概念とを繋ぐ「意味」の層です。これが生成AIにとって不可欠な理由は、主に3つあります。
① AIに「知性」という名の「文脈」を授けるため
AIは、fct_sales.sales_amtというカラム名だけでは、それが何を意味するのかを理解できません。セマンティックレイヤーは、それが「消費税込みの日本円での売上高」であるといった ビジネス上の文脈(コンテキスト) を与え、AIがデータを正しく解釈するための「辞書」として機能します。
② AIを「暴走」させない「ガードレール」を築くため
十分なコンテキストがない状態でAIにデータ分析をさせると、誤った解釈に基づき、もっともらしいが不正確な結果を出力する「ハルシネーション(幻覚)」のリスクが高まります。セマンティックレイヤーは、AIが参照すべきデータの関係性や計算方法を明確に定義することで、その出力精度と信頼性を担保するガードレールとなります。
③ 組織の「唯一の真実」という「秩序」をもたらすため
Lookerでは「利益率」などの重要業績評価指標(KPI)の計算ロジックを、セマンティックレイヤーにコードとして一元的に定義します。
measure: profit_margin {
label: "利益率"
type: number
sql: ${total_profit} / NULLIF(${total_sales}, 0) ;;
value_format: "0.00%"
description: "総利益を総売上で割って算出します。"
}AIを含む全てのユーザーやツールがこの 「唯一の正しい定義(Single Source of Truth)」 を参照することで、組織内での指標のズレを防ぎ、データに基づいた一貫性のある意思決定を促進します。
3. 「意味」を実装するモダンなデータアーキテクチャ
この「意味」の層を実装するための、具体的なアーキテクチャと主要コンポーネントの役割を見ていきましょう。
主要コンポーネントの役割
1. Dataplex データカタログ:組織のデータ資産の「地図」🌏
Dataplexは、Google Cloud上のデータ資産を一元的に発見、管理、統制するための統合データファブリックです。その中核機能であるデータカタログは、BigQueryやCloud Storageなど、組織内に散らばるデータソースを自動的にスキャンし、メタデータを集約します。
- 役割: これから分析する 「そもそも、どんなデータがどこにあるのか」 を把握するための、網羅的な「地図」を提供します。技術的なメタデータに加えて、ビジネス用語の定義(ビジネスグロッサリー)を付与することで、データディスカバリー(データの発見)を促進する、データガバナンスの基盤となります。
2. Dataform/dbt (data build tool):信頼できるデータの「加工工場」🏭
Dataformやdbtは、データウェアハウス内でのデータ変換(Transformation)を効率化するオープンソースのツールです。SQLでデータモデルの構築、テスト、ドキュメント化を行えるため、データエンジニアリングの生産性を飛躍的に向上させます。DataformはGoogle Cloudネイティブなサーバーレスサービスとして、dbtはオープンソースのデファクトスタンダードとして広く利用されています。
- 役割: Dataplexで見つけた生データを、BigQuery内で分析しやすい形(データマート)に変換・加工する 「T in ELT」 の役割を担います。信頼性の高いテスト済みのテーブルを構築し、セマンティックレイヤーが参照する、クリーンで構造化されたデータの土台を作ります。
3. Looker:ビジネスの「意味」を定義する通訳者🗣️
Lookerは、Google Cloudが提供するエンタープライズ対応のBIプラットフォームです。その心臓部であるLookMLという独自のモデリング言語により、極めて強力なセマンティックレイヤーをコードとして構築できます。
- 役割: dbtが作成したデータマートに接続し、「売上」「利益率」といったビジネス指標や、データ間の関係性を定義します。ここで定義された「意味」は、Lookerのダッシュボードだけでなく、APIを通じて他のアプリケーションや生成AIからも利用可能です。まさに、ビジネスユーザーとデータ、そしてAIとの対話を仲介する「通訳者」の役割を果たします。
▼ 実践:自然言語がSQLクエリに変換され、自動でグラフ化する仕組み
ユーザーの質問👦:「昨年度の製品カテゴリ別売上トップ5は?」
↓
セマンティックレイヤーの解釈🤖: AIが「昨年度」「製品カテゴリ」「売上」といった言葉を、事前に定義されたディメンションやメジャーと照合。 ※ 用語解説 ディメンション:「何で」「どこで」「いつ」といった分析の切り口となる項目(例:製品カテゴリ、都道府県など) メジャー:集計・計算される数値データ(例:売り上げ金額、クリック数、顧客数など)
↓
クエリの自動生成🤖: 解釈に基づき、AIが以下のSQLを生成。
SELECT
product.category AS product_category,
SUM(sales.sales_amount) AS total_sales
FROM
`project.dataset.sales` AS sales
LEFT JOIN
`project.dataset.product` AS product ON sales.product_id = product.product_id
WHERE
EXTRACT(YEAR FROM sales.order_date) = EXTRACT(YEAR FROM CURRENT_DATE()) - 1
GROUP BY
1
ORDER BY
total_sales DESC
LIMIT 5↓
実行と可視化🤖: 生成されたクエリがBigQueryで実行され、結果が返されます。さらにAIは、ユーザーの「トップ5」「棒グラフで」という要求を理解しているため、返されたデータを元に最適なビジュアライゼーション(この場合は棒グラフ)を自動で生成し、ユーザーに提示します。
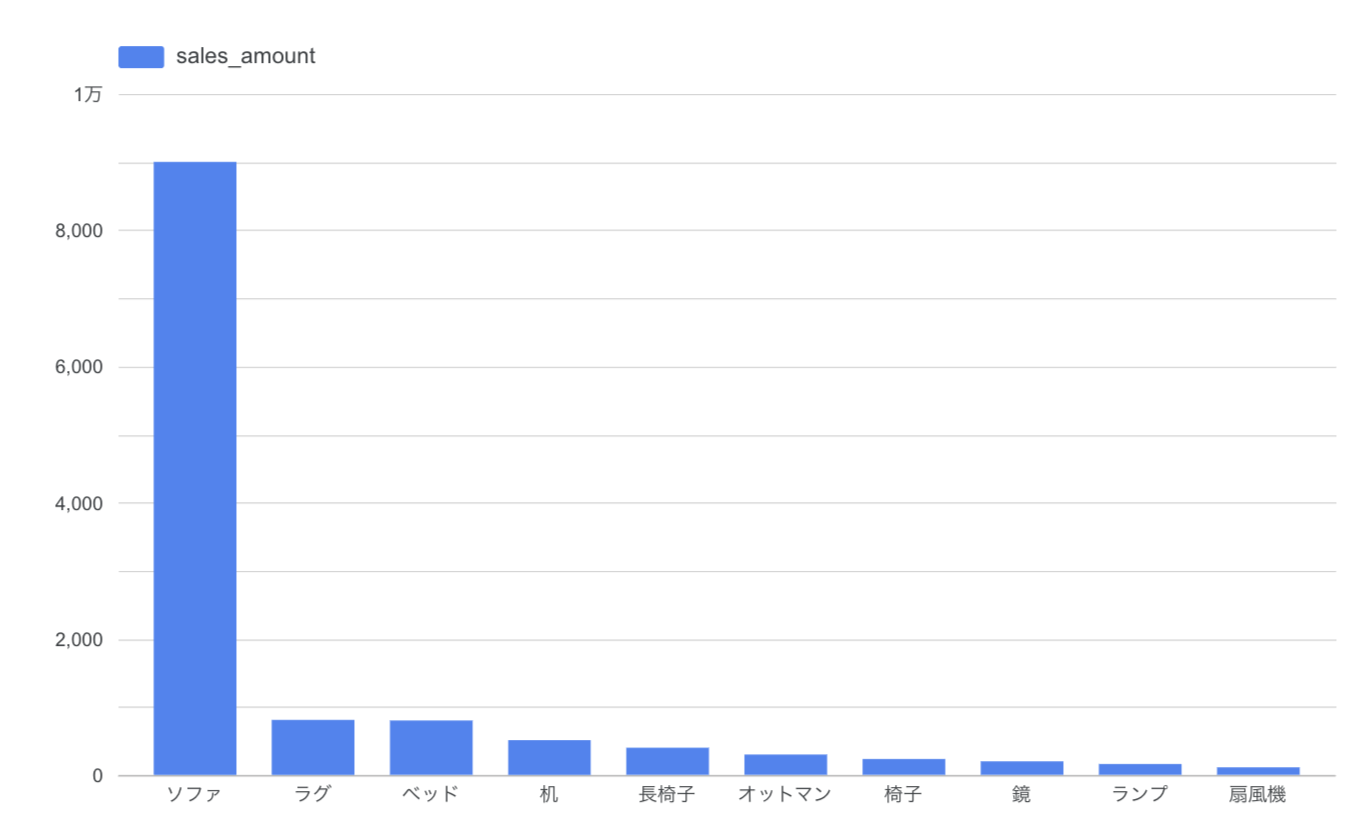
このように、セマンティックレイヤーがあることで、曖昧な自然言語による問いから、具体的なアクションに繋がるインサイトまでがシームレスに提供されるのです。
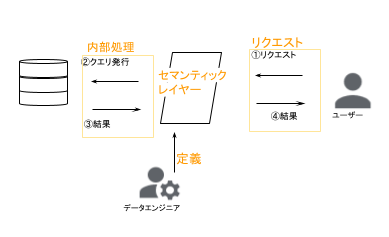
BigQueryのDataCanvasをご利用されたことのある方は、馴染みがある流れではないでしょうか。 この機能を使う際にもセマンティックレイヤーはとても役に立ちます。
4. ただし、銀の弾丸ではない
セマンティックレイヤーは非常に強力ですが、導入すれば全てが解決する「銀の弾丸」ではない、という点は強調しておきます。
まず、このレイヤーを設計・実装するには、データエンジニアの専門知識が不可欠です。 そして最も重要なのは、 「Garbage In, Garbage Out(ゴミからはゴミしか生まれない)」 ということ。dbtなどを用いて、きちんとデータモデリングされた信頼できるテーブルがあってこそ、セマンティックレイヤーはその真価を発揮します。 汚いデータを少しだけ取りやすくしても、根本的な問題は解決しません。
5. まとめ:データ基盤の次なる戦略的投資
生成AIの能力を最大限に引き出すためには、AIが理解できる「意味」が与えられたデータ基盤が不可欠です。 もちろん、SaaS製品を使うのも手です。 Google Cloudで実現するためには、どうすれば良いか。
-
Dataplexで組織のデータ資産を可視化・統制し、
-
dbtで信頼できるデータマートを構築し、
-
Lookerでビジネスの「意味」を一元的に定義する。
この一連のアーキテクチャを整備することが、データ基盤を「構文(シンタックス)」の管理から「意味(セマンティック)」の管理へと昇華させ、将来のAI活用時代における競争優位性を確立します。
生成AIツールの導入を検討することは、同時に、その頭脳となるセマンティックレイヤーへの投資を検討する ことに他なりません。
興味をお持ちいただけたでしょうか。誰かの参考になれば嬉しいです。
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。