プロジェクトドメイン知識を提供するローカルMCPサーバー構築記
プロジェクトのドメイン知識を提供するLlamaIndexとgemmaを使ったローカルMCPサーバー構築記です
Table of contents
author: teikoku-penguin
はじめに
お久しぶりです。teikoku-penguinです。
今回は今流行りのGemini CLIとローカルMCPサーバーのお話です。
※この記事はGeminiを活用して実験した内容をgeminiに生成させ、筆者が手直しして執筆しました。
「あの機能の設計思想は?」、「このドメイン用語の意味は?」
開発中に、そんな風にAIに気軽に質問できたら便利ですよね。
本記事はそんな思いつきから始まった、「プロジェクトのドメイン知識」を理解するAIアシスタントをローカル環境に構築するまでの、技術的な挑戦と試行錯誤の記録です。
本記事ではLlamaIndexでプロジェクト固有の知識を学習し、OllamaとGemmaで思考するAIサーバーをDocker上で構築。
そしてコマンドラインツールGemini CLIからその知識を呼び出す方法を解説します。
システムの構成:全てをローカルで完結させる
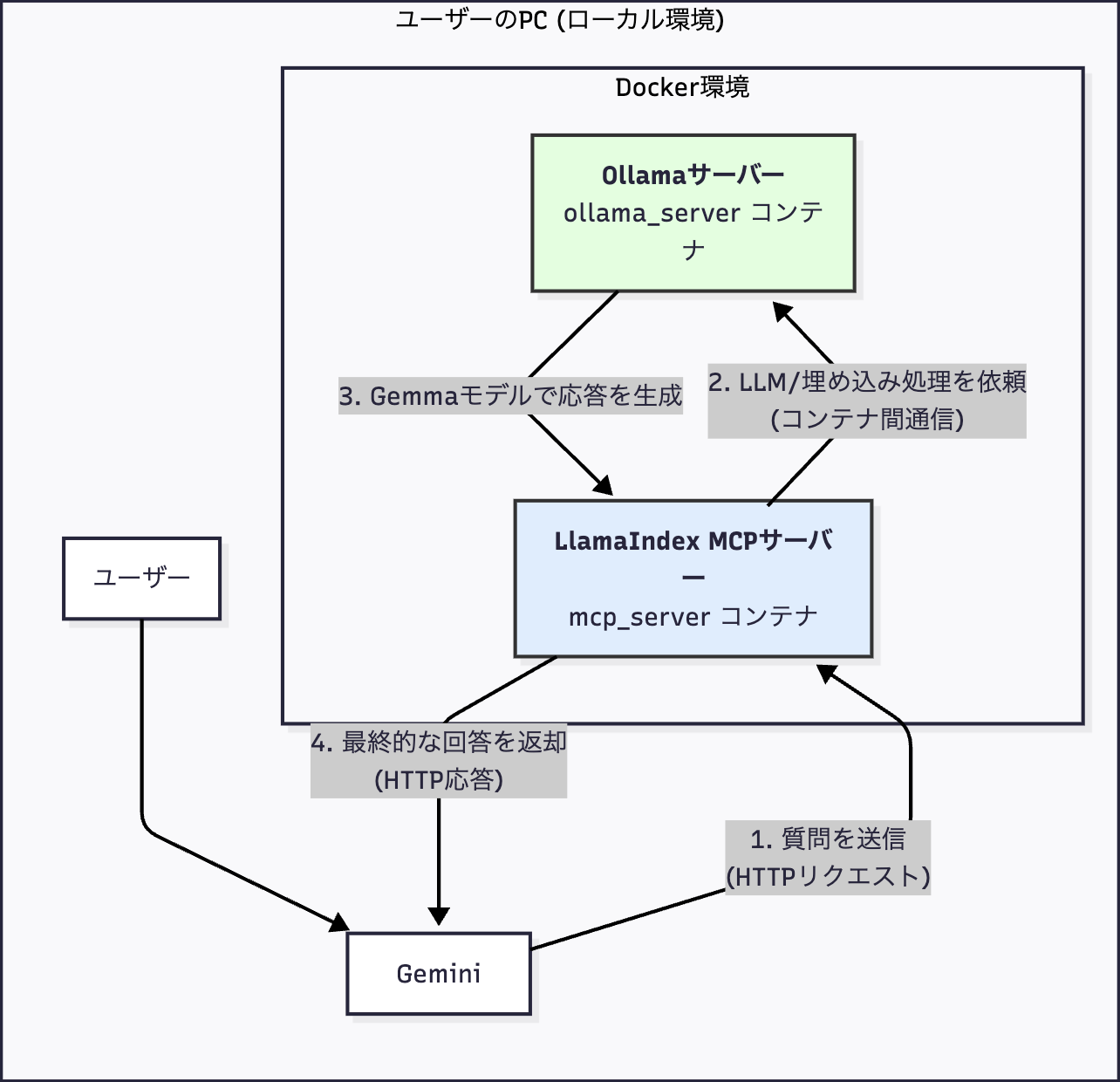
今回目指したのは、プライバシーとコストを気にせず使える、完全にローカルで動作するシステムです。その全体像は以下の通りです。
- Ollamaサーバー (Docker): AIの「脳」となるGemmaモデルを動かします。
- LlamaIndex MCPサーバー (Docker): あなたのドキュメントを知識源として提供する「知識の専門家」です。MCPとは(Model Context Protocol)を指します。
- Docker Compose: これら2つのサーバーを連携させて管理します。
- Gemini CLI: ターミナルからAIと対話するための「窓口」です。
セットアップ:フォルダやLlamaIndexが参照するドキュメントを準備する
まず、プロジェクトの土台となる設定ファイル群を作成します。
1. フォルダとドメイン知識の準備
mkdir llamaIndexMcp
cd llamaIndexMcp
mkdir data
# dataフォルダ内に、AIに学習させたいドキュメントを追加
echo "- ◯◯とは□□のことを指す" > data/project_domain.md2. 必要なライブラリを記載 (requirements.txt)
llama-index>=0.7.35
llama-index-llms-ollama>=0.1.0
llama-index-embeddings-ollama>=0.1.0
llama-index-tools-mcp>=0.2.6
mcp[cli]>=1.11.0
uvicorn3. MCPサーバーの実装 (server.py)
#!/usr/bin/env python3
import logging
import uvicorn
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
from mcp.server.fast_mcp import FastMCP
from mcp.server.fast_mcp.tools.base import tool
# ログ設定
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
logger = logging.getLogger(__name__)
# LLMと埋め込みモデルの設定
Settings.llm = Ollama(model="gemma:2b", base_url="http://ollama:11434", request_timeout=120.0)
Settings.embed_model = OllamaEmbedding(model_name="gemma:2b", base_url="http://ollama:11434")
# インデックス生成
def build_index(data_dir: str = "./data") -> VectorStoreIndex:
docs = SimpleDirectoryReader(data_dir).load_data()
return VectorStoreIndex.from_documents(docs)
# MCPサーバー定義
def create_mcp_server(index: VectorStoreIndex) -> FastMCP:
query_engine = index.as_query_engine()
mcp = FastMCP(
title="LlamaIndex Knowledge Server",
description="ドメイン知識に関する質問に答えるサーバー",
streamable_http_path="/mcp",
)
@tool
def ask_internal_docs(query: str) -> str:
"""プロジェクトのドメイン知識に関する質問に答えます。"""
logger.info(f"Query: {query}")
response = query_engine.query(query)
return str(response)
mcp.add_tool(ask_internal_docs)
return mcp
mcp_server = create_mcp_server(build_index())
app = mcp_server.streamable_http_app()
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)4. Docker環境の定義 (Dockerfile & docker-compose.yml)
Dockerfile
FROM python:3.11-slim
WORKDIR /app
ENV PYTHONUNBUFFERED=1 DEBIAN_FRONTEND=noninteractive TZ=Asia/Tokyo
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["python", "server.py"]docker-compose.yml
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama_server
volumes:
- ollama_data:/root/.ollama
ports:
- "11434:11434"
mcp_server:
build: .
container_name: llamaindex_mcp_server
ports:
- "8000:8000"
volumes:
- ./data:/app/data:ro
depends_on:
- ollama
volumes:
ollama_data:起動と対話:AIアシスタントを呼び出す
準備は整いました。サーバーを起動し、Gemini CLIから話しかけてみましょう。
サーバーの起動
# コンテナをビルドしてバックグラウンドで起動
docker compose up -d --build
# OllamaコンテナにGemmaモデルをダウンロード
docker exec -it ollama_server ollama pull gemma:2bGemini CLIの設定
~/.gemini/config.json ファイルを作成・編集し、起動したサーバーに接続するよう設定します。
{
"mcpServers": {
"llamaIndexKnowledgeHttp": {
"httpUrl": "http://localhost:8000/mcp/",
"timeout": 300000
}
}
}対話の実行
gemini -p "◯◯の□□について教えて"理想と現実:精度と調整不足
gemma2bをM1 Mac Bookで動かしたことで精度が出なかったのか、あるいはLlamaIndexに渡したデータの書き方が悪かったのか、残念ながら今回はあまり高い精度がでませんでした。
時間があればより精度の高いものを目指すつもりです。
まとめと次のステップ
今回の挑戦で、 「ローカルLLMと連携するドメイン知識サーバー」をDocker上で構築することに成功 しました。これは、プライバシーとコストを両立するAI活用の大きな一歩です。
一方で、精度の課題が残ることも分かりました。しかし、今回構築した環境は、今後の改善に向けた最高の実験台です。
- より高性能なローカルモデル(llama3:8bなど)を試す。
- クラウドのLLM API(GeminiやGPT-4)に切り替えて、精度の限界を探る。
- LlamaIndexの高度なRAGパイプライン(再ランキングなど)を導入する。
最後までお読みいただきありがとうございました。
この記事がなにかの役に立てば幸いです。
※本記事は、ジーアイクラウド株式会社の見解を述べたものであり、必要な調査・検討は行っているものの必ずしもその正確性や真実性を保証するものではありません。
※リンクを利用する際には、必ず出典がGIC dryaki-blogであることを明記してください。
リンクの利用によりトラブルが発生した場合、リンクを設置した方ご自身の責任で対応してください。
ジーアイクラウド株式会社はユーザーによるリンクの利用につき、如何なる責任を負うものではありません。